 研討會預告 | 使用 Transducer 模型優化語音識別結果
研討會預告 | 使用 Transducer 模型優化語音識別結果

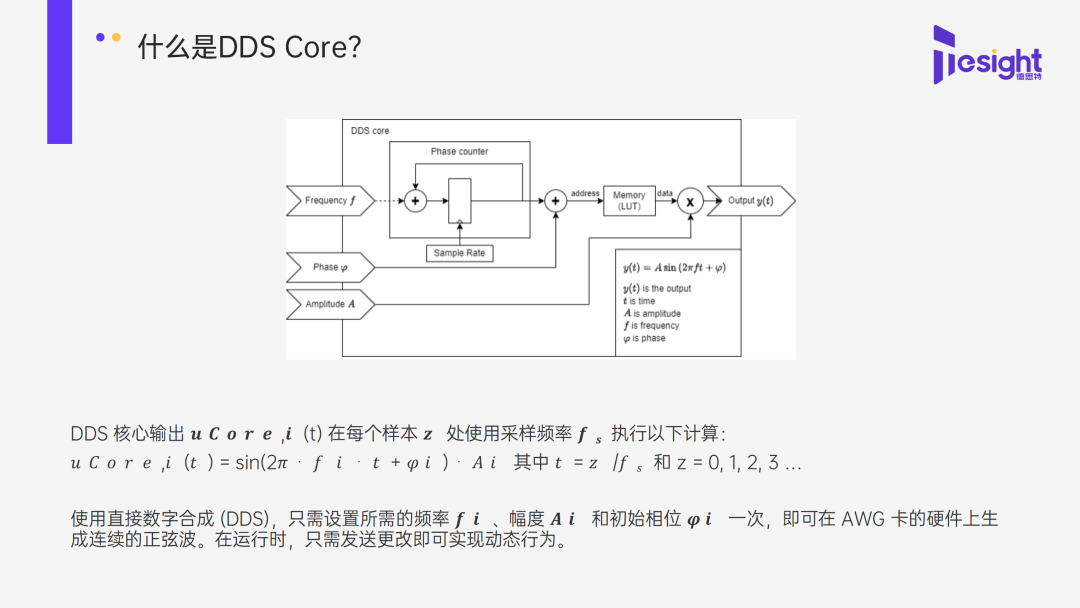
在 ASR 自動語音識別領域,基于 CTC 的聲學模型不再需要對訓練的音頻序列和文本序列進行強制對齊,實際上已經初步具備了端到端的聲學模型建模能力。但是 CTC 模型進行聲學建模存在著兩個嚴重的瓶頸,一是缺乏語言模型建模能力,不能整合語言模型進行聯合優化,二是 CTC 有一個不合理的假設:標簽相互獨立,這個基本假設與語音識別任務之間存在著一定程度的背離,因為在語言系統中存在語境的上下文關系。因此針對 CTC 的不足,Transducer 模型可以彌補這種不合理的假設,解決 CTC 的問題。
3 月 9 日,NVIDIA 企業開發者社區經理李奕澎將面向有 NLP 和 Speech AI 開發需求的開發者,在本次研討會中重點討論 Transducer 模型,并通過代碼來訓練和評估 Transducer 模型。
Transducer 模型在自動語音識別中的應用 – NVIDIA NeMo 代碼解析

3 月 9 日,星期四,20:00 - 21:30
主要內容:
本次網絡研討會主要面向有 NLP 和 Speech AI 開發需求的開發者。通過本次網絡研討會,您可以獲得以下信息:
Transducer 介紹
Transducer loss 的優勢和局限
Transducer 的模型架構
ContextNet 的模型架構
Transducer 模型的訓練和評估
演講嘉賓

李奕澎 | NVIDIA 企業開發者社區經理
擁有多年數據分析建模、人工智能自然語言處理開發經驗。在自動語音識別、自然語言處理、語音合成等對話式 AI 技術領域有豐富的實戰經驗與見解。曾開發法律、金融、保險文檔中基于實體抽取的智能問答系統,曾開發基于 NLP 知識抽取,KG 知識圖譜的建立的科研文檔智能檢索系統。
參與方式

識別二維碼注冊本次研討會
相關資料

識別二維碼了解 NVIDIA NeMo 更多信息
點擊 “閱讀原文” 或掃描下方海報二維碼,即可免費注冊 GTC23,在 3 月 24 日 聽 OpenAI 聯合創始人與 NVIDIA 創始人的爐邊談話,將由 NVIDIA 專家主持,配中文講解和實時答疑,一起看 AI 的現狀和未來!

原文標題:研討會預告 | 使用 Transducer 模型優化語音識別結果
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
23文章
4087瀏覽量
99182
原文標題:研討會預告 | 使用 Transducer 模型優化語音識別結果
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
特瑞仕電源架構解決方案網絡研討會問題解答(2)
Arm SystemReady研討會圓滿召開
活動預告|雅特力與您相約2025電機控制先進技術研討會

BlackBerry QNX亮相2025恩智浦技術日巡回研討會杭州站
MPS第八屆新能源汽車電源與EMI優化技術研討會回顧
報名開啟!2025 STM32 研討會:華清遠見邀工程師共話技術突破與項目實戰

瑞豐光電亮相DVN東京國際汽車照明研討會
Rambus邀您相約Keysight設備安全研討會
火山引擎2025“大模型+智能硬件”機智云特邀研討會圓滿收官 共繪萬物智能產業藍圖

面向未來量子通信與大物理研究線上研討會QA筆記請查收!
2025年簡儀科技全國巡回研討會預告



 工商網監
工商網監
評論