 大腦視覺信號被Stable Diffusion復現成圖像!
大腦視覺信號被Stable Diffusion復現成圖像!

“現在Stable Diffusion已經能重建大腦視覺信號了!”
就在昨晚,一個聽起來細思極恐的“AI讀腦術”研究,在網上掀起軒然大波:

這項研究聲稱,只需用fMRI(功能磁共振成像技術,相比sMRI更關注功能性信息,如腦皮層激活情況等)掃描大腦特定部位獲取信號,AI就能重建出我們看到的圖像!

例如這是一系列人眼看到的圖像,包括戴著蝴蝶結的小熊、飛機和白色鐘樓:

AI看了眼人腦信號后,立馬就給出這樣的結果,屬實把該抓的重點全都抓住了:

再發展一步,這不就約等于哈利波特里的讀心術了嗎??

更有網友感到驚嘆:如果說ChatGPT開放API是件大事,那這簡直稱得上瘋狂。
所以,這究竟是怎么一回事?
用Stable Diffusion可視化人腦信號
這項研究來自日本大阪大學,目前已經被CVPR 2023收錄:

High-resolution image reconstruction with latent diffusion models from human brain activity
研究希望能從人類大腦活動中,重建高保真的真實感圖像,來理解大腦、并解讀計算機視覺模型和人類視覺系統之間的聯系。
要知道,此前雖然有不少腦機接口研究,致力于從人類大腦活動中讀取并重建信號,如意念打字等。
然而,從人類大腦活動中重建視覺信號——具有真實感的圖像,仍然挑戰極大。
例如這是此前UC伯克利做過的一項類似研究,復現一張人眼看到的飛機片段,但計算機重建出來的圖像卻幾乎看不出飛機的特征:

△圖源UC伯克利研究Reconstructing Visual Experiences from Brain Activity Evoked by Natural Movies
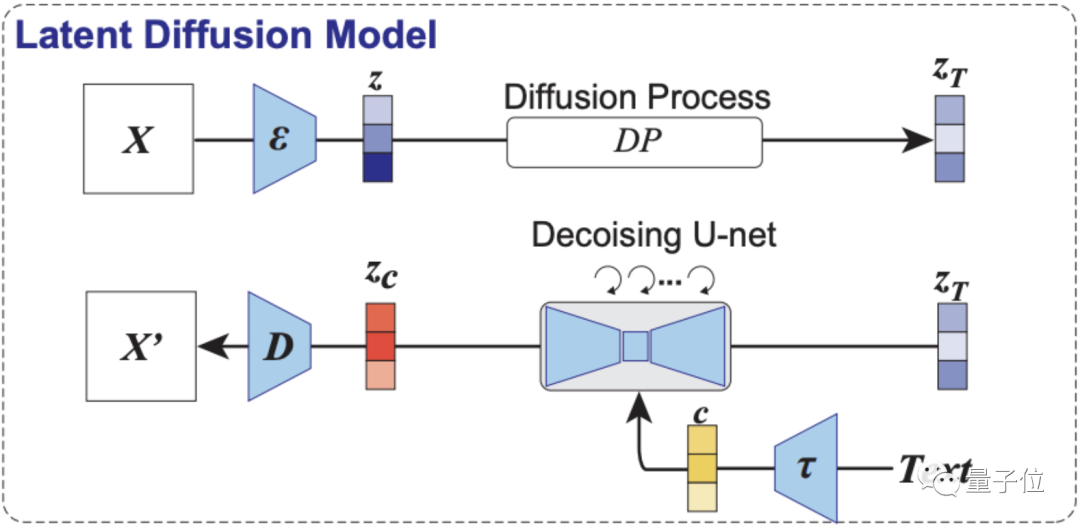
這次,研究人員重建信號選用的AI模型,是這一年多在圖像生成領域地位飛升的擴散模型。
當然,更準確地說是基于潛在擴散模型(LDM)——Stable Diffusion。
整體研究的思路,則是基于Stable Diffusion,打造一種以人腦活動信號為條件的去噪過程的可視化技術。
它不需要在復雜的深度學習模型上進行訓練或做精細的微調,只需要做好fMRI(功能磁共振成像技術)成像到Stable Diffusion中潛在表征的簡單線性映射關系就行。
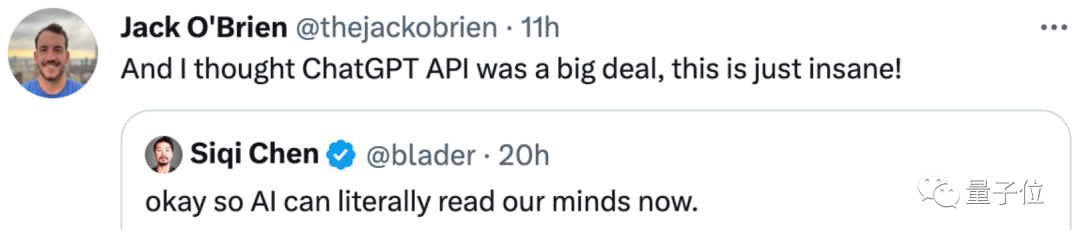
它的概覽框架是這樣的,看起來也非常簡單:
僅由1個圖像編碼器、1個圖像解碼器,外加1個語義解碼器組成。
具體怎么work?
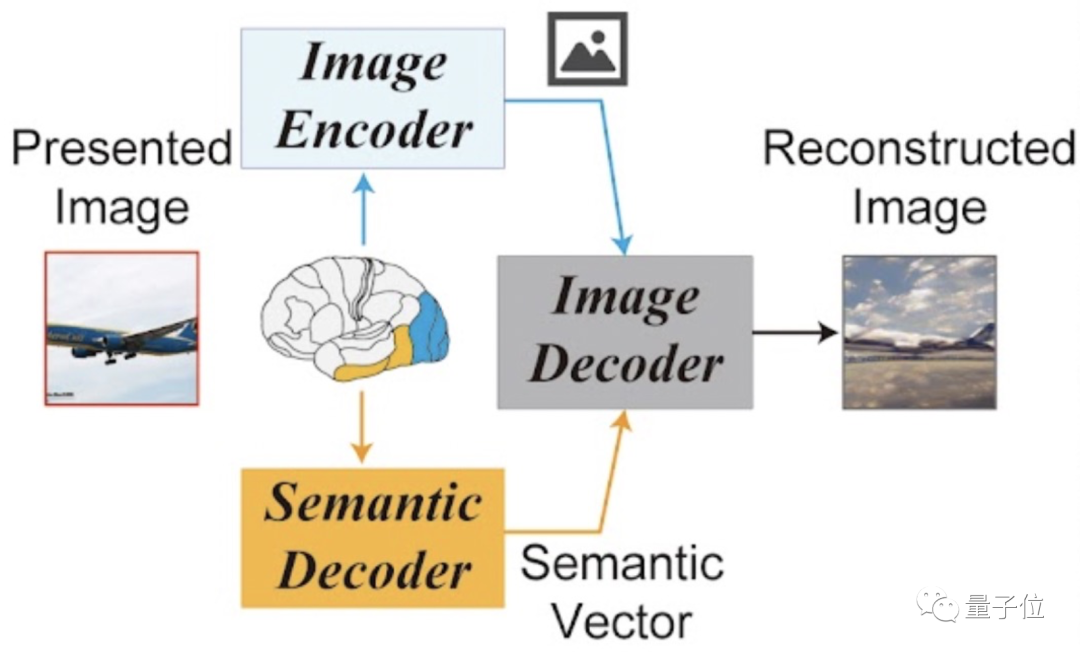
如下圖所示,第一部分為本研究用到的LDM示意圖。
其中ε代表圖像編碼器,D代表圖像解碼器,而τ是一個文本編碼器(CLIP)。
重點是解碼分析,如下圖所示,模型依次從大腦早期(藍色)和較高(黃色)視覺皮層內的fMRI信號中,解碼出重建圖像(z)和相關文本c的潛在表征。
然后將這些潛在表征當作輸入,就可以得到模型最終復現出來的圖像Xzc。
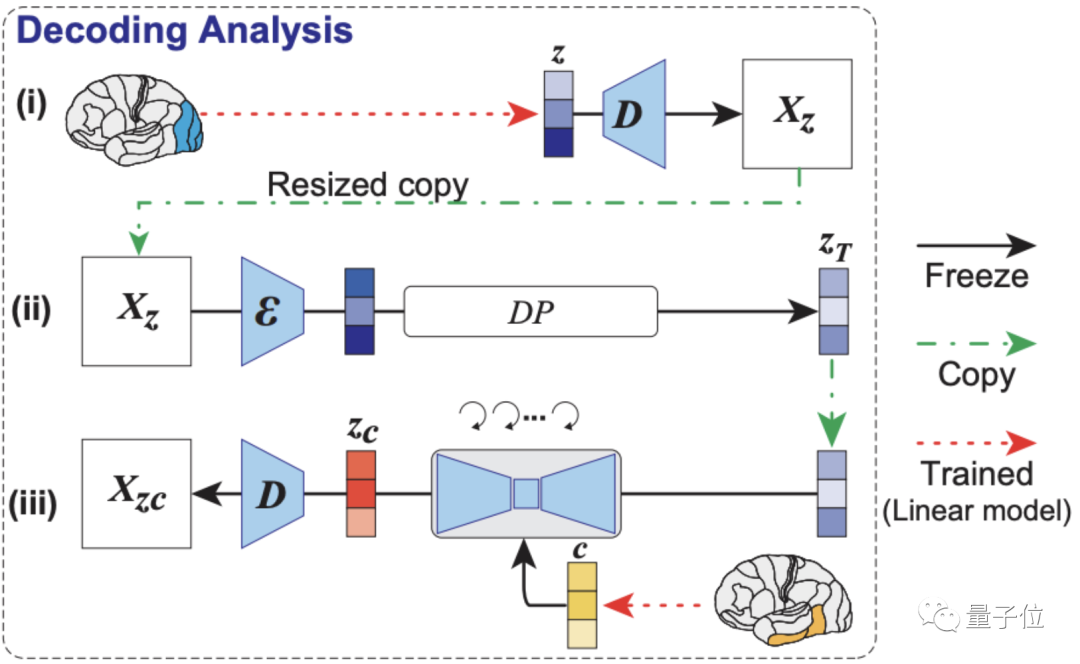
最后還沒有完,如編碼分析示意圖,作者還構建了一個編碼模型,用來預測LDM不同組件(包括圖像z、文本c和zc)所對應的fMRI信號,它可以用來理解Stable Diffusion的內部過程。
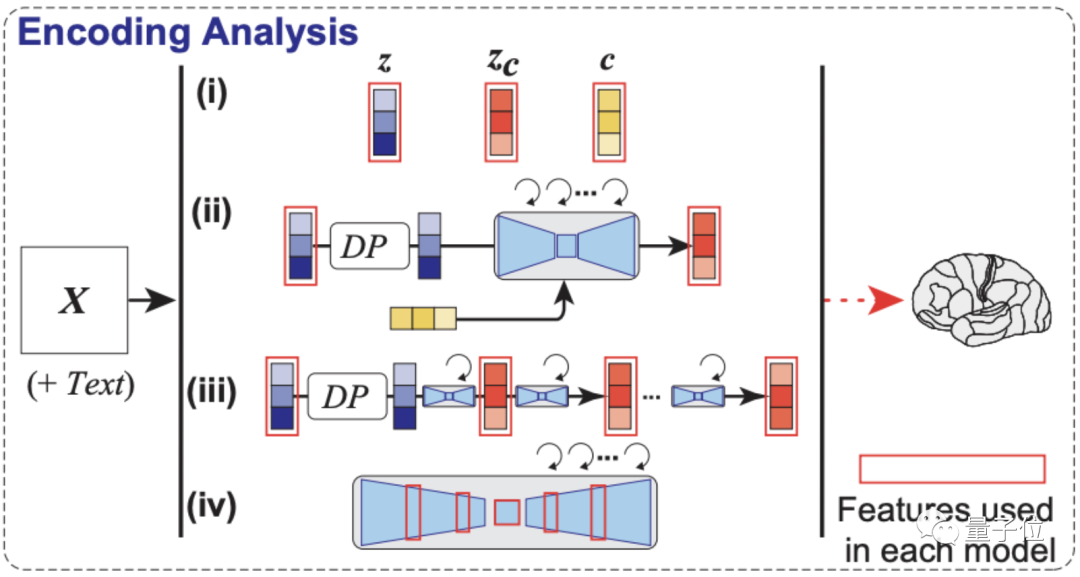
可以看到,采用了zc的編碼模型在大腦后部視覺皮層產生的預測精確度是最高的。(zc是與c進行交叉注意的反向擴散后,z再添加噪聲的潛在表征)
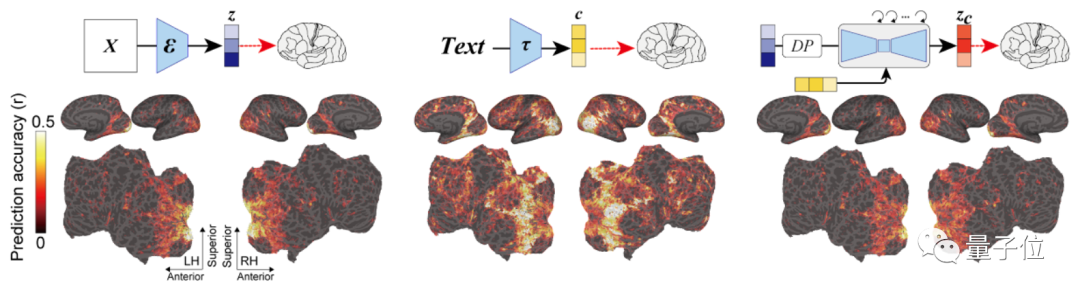
相比其它兩者,它生成的圖像既具有高語義保真度,分辨率也很高。

還有用GAN重建人臉圖像的
看完這項研究,已經有網友想到了細思極恐的東西:
這個AI雖然只是復制了“眼睛”所看到的東西。
但是否會有一天,AI能直接從人腦的思維、甚至是記憶中重建出圖像或文字?
“語言的用處不再存在了”

于是有網友進一步想到,如果能讀取記憶的話,那么目擊證人的證詞似乎也會變得更可靠了:

還別說,就在去年真有一項研究基于GAN,通過fMRI收集到的大腦信號重建看到的人臉圖像:

不過,重建出來的效果似乎不怎么樣……
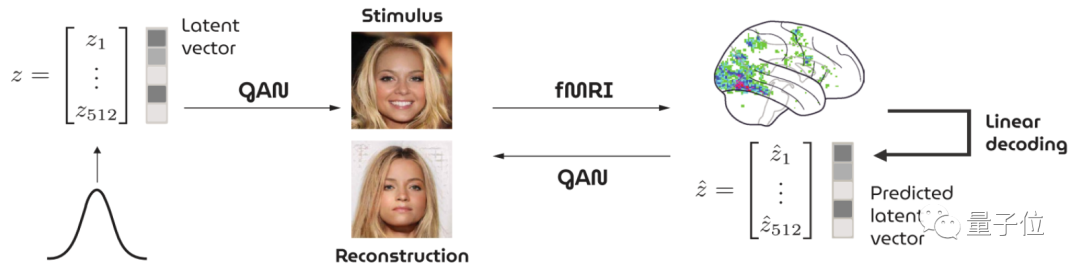
顯然,在人臉這種比較精細的圖像生成上,AI“讀腦術”還有很長一段路要走。
對于這種大腦信號重建的研究,也有網友提出了質疑。
例如,是否只是AI從訓練數據集中提取出了相似的數據?
對此有網友回復表示,論文中的訓練數據集和測試集是分開的:

作者們也在項目主頁中表示,代碼很快會開源。可以先期待一下~

作者介紹
本研究僅兩位作者。
一位是2021年才剛剛成為大阪大學助理教授的Yu Takagi,他主要從事計算神經科學和人工智能的交叉研究。
最近,他同時在牛津大學人腦活動中心和東京大學心理學系利用機器學習技術,來研究復雜決策任務中的動態計算。
另一位是大阪大學教授Shinji Nishimoto,他也是日本腦信息通信融合研究中心的首席研究員。
研究方向為定量理解大腦中的視覺和認知處理,谷歌學術引用3000+次。
那么,你覺得這波AI重建圖像的效果如何?
審核編輯 :李倩
-
成像技術
+關注
關注
4文章
309瀏覽量
32227 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265414
原文標題:CVPR 2023 | 大腦視覺信號被Stable Diffusion復現成圖像!"AI讀腦術"來了!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
圖像采集卡:機器視覺系統的“數據中樞”,解鎖精準成像新可能


工業機器視覺中的關鍵組件:圖像采集卡選型與應用
從模擬到AI集成:圖像采集卡的技術演進與未來三大趨勢
工業4.0的“數據橋梁”:圖像采集卡如何撐起智能制造的視覺核心
圖像采集卡:機器視覺時代的圖像數據核心樞紐
工業圖像采集卡:機器視覺的“信號中樞”

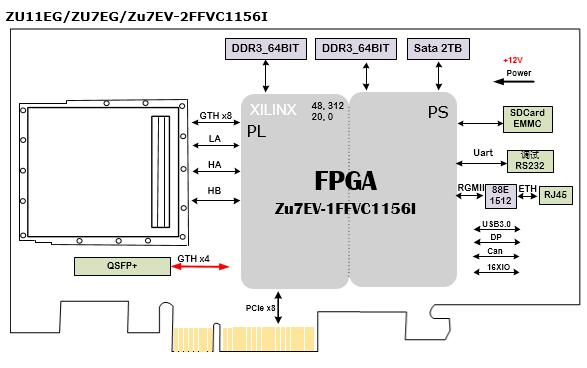
圖像信號分析處理卡設計原理圖:536-基于FMC接口的XCZU7EV 通用PCIe卡 視覺處理卡 工業控制卡
是德N5173B信號發生器在EMC測試中的干擾信號精準復現技巧
工業相機圖像采集卡:機器視覺的核心樞紐

基于LockAI視覺識別模塊:C++圖像的基本運算

基于LockAI視覺識別模塊:C++圖像采集例程
?Diffusion生成式動作引擎技術解析
使用OpenVINO GenAI和LoRA適配器進行圖像生成



 工商網監
工商網監
評論