 2分鐘看懂快速排序的算法
2分鐘看懂快速排序的算法

之前有同學提出想要復習一下排序算法,那我們今天就挑一個難度中等的,快速排序。
先搞清楚快速排序原理,然后再寫代碼。
快速排序的原理不難,先找到一個數字,我們把它稱作基準,然后通過一系列的比較交換,能讓基準達到一個合適的位置,保證基準前面的數字都比他小,后面的數字都比他大。
這個過程需要兩個指針 x 和 y,其實就是數組的下標,x指向數組第一個數字,y指向數組最后一個數字。
為了操作方便,我們一般以第一個數字為基準。
先把他記下來。 ?
?
然后從 y 開始,4比3大,不用管,y 向前移動。 ?
?
2比 3 小,比基準小的數字應該放在左邊,所以把 2 移動到前面,同時 x 向后移動。 ?
?
6比 3 大,放在后面,y 向前移動。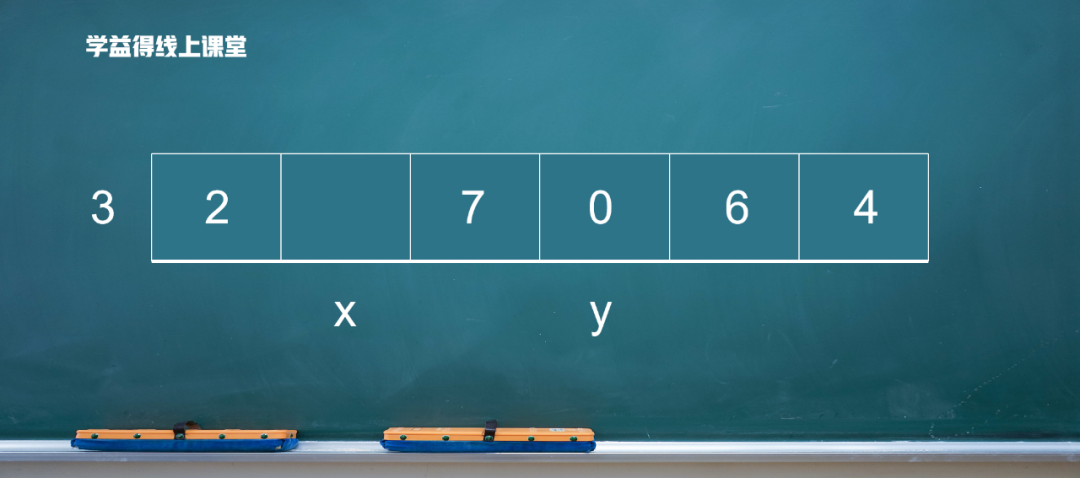 ?
?
0比3小,放在前面,x向后移動。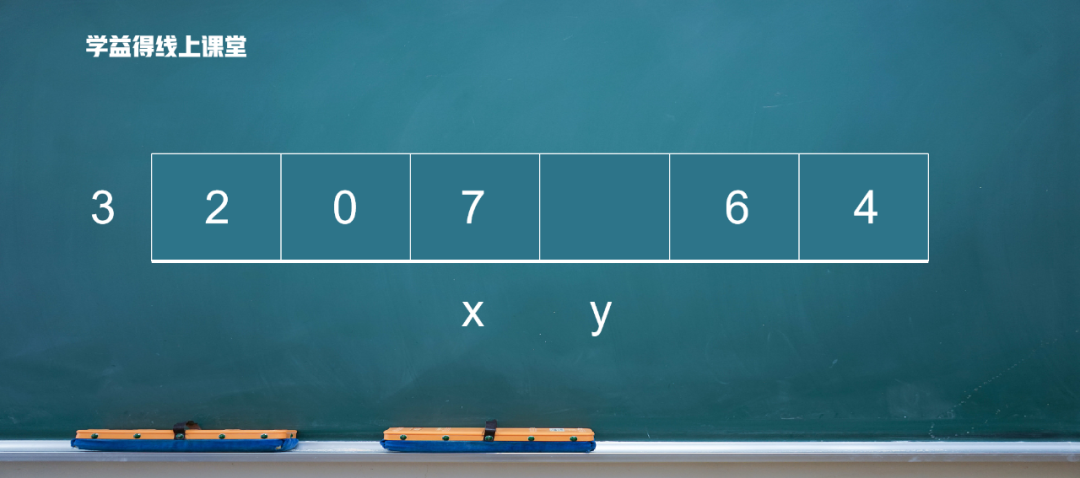 ?
?
7比3大,放在后面,y 向前移動。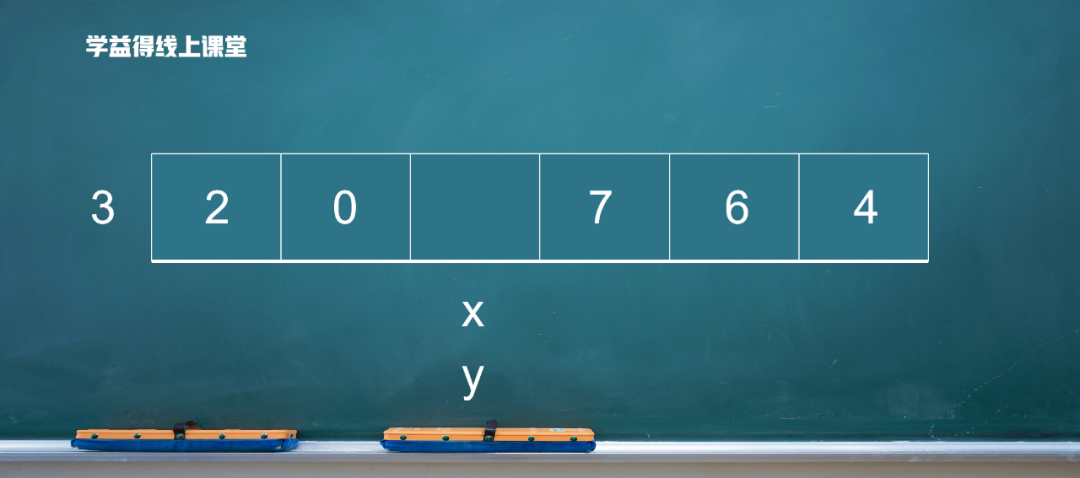 ?
?
最后,x 和 y 相等,把3放到這個位置上。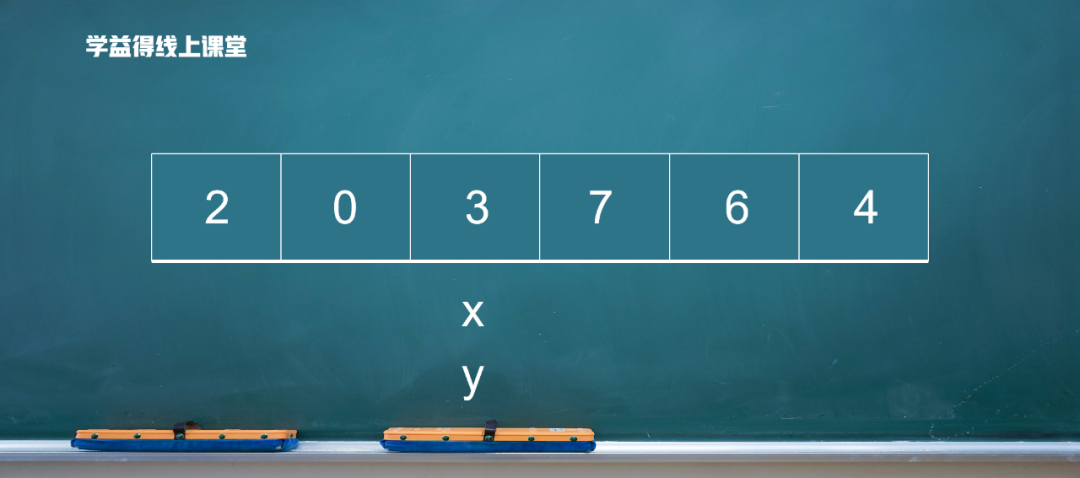
第一輪移動結束。現象就是,3的前面都是比3小的,3的后面都是比3大的。
接下來就是對3的前面和3的后面做同樣的操作,我們應該立馬能想到遞歸。
搞清楚了原理還不夠,作為求職者把代碼寫出來才是王道。
#include快速排序是不是真的很快? 我們可以和冒泡排序做個對比,修改下代碼,隨機產生5萬個數據,使用冒泡排序和快速排序,時間上的差別確實很大。void quick_sort(int *a, int start, int end) { if (start >= end) return; int x = start; int y = end; int base = a[start]; while (x < y) { while (a[y] > base && x < y) { y--; } if (x < y) { a[x++] = a[y]; } while (a[x] < base && x < y) { x++; } if (x < y) { a[y--] = a[x]; } } a[x] = base; quick_sort(a, start, x - 1); quick_sort(a, x + 1, end); } int main() { int array[] = {3, 6, 7, 0, 2, 4}; quick_sort(array, 0, 6); for (int i = 0; i < 6; i++) { printf("%d ", array[i]); } return 0; }
冒泡排序:
real 0m8.255s user 0m8.098s sys 0m0.008s快速排序:
real 0m0.078s user 0m0.010s sys 0m0.000s要說原因的話,冒泡排序只能相鄰位置上比較移動,但是快速排序卻可以跳著來,所以大部分情況下,快速排序效率都要高于冒泡排序。
審核編輯:劉清
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
排序算法
+關注
關注
0文章
53瀏覽量
10426 -
Array
+關注
關注
102文章
19瀏覽量
19760
原文標題:2分鐘看懂快速排序
文章出處:【微信號:學益得智能硬件,微信公眾號:學益得智能硬件】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
matlab快速排序算法實現
待排的記錄分割成獨立的兩部分,%其中前一部分的 記錄的關鍵字均比另一部分記錄的關鍵字小,%再分別對兩組記錄進行遞歸分割,達到排序的目的%平均時間復雜度為O(log2(n))functi
發表于 02-29 15:58
嵌入式stm32實用的排序算法 - 交換排序
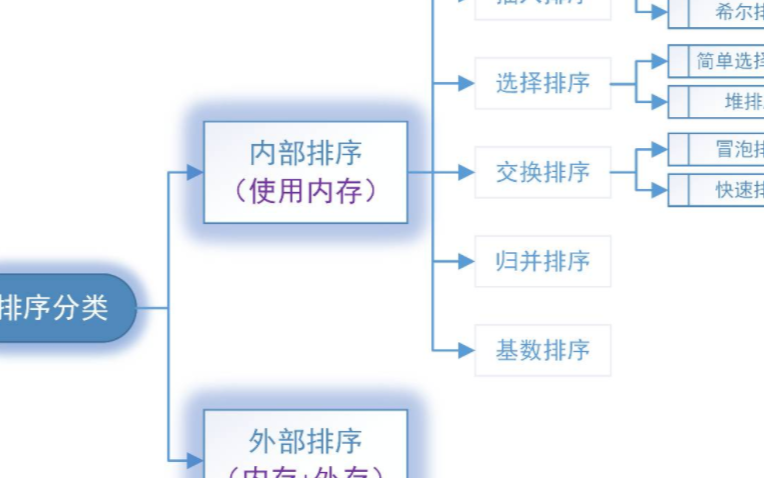
合很多,我這里就不再一一舉例說明,掌握排序的基本算法,到時候遇到就有用武之地。Ⅱ、排序算法分類1.按存儲分類:內部排序和外部
發表于 04-12 13:14
基于Hadoop的幾種排序算法研究
如何高效排序是在對大數據進行快速有效的分析與處理時的一個重要問題。首先對基于Hadoop平臺的幾種高效的排序算法(Quicksort,Heapsort和Mergesort
發表于 11-08 17:25
?15次下載

C語言排序中快速排序的技巧
快速排序是由東尼·霍爾所發展的一種排序算法。在平均狀況下,排序 n 個項目要Ο(n log n)次比較。在最壞狀況下則需要Ο(n

排序算法有哪些
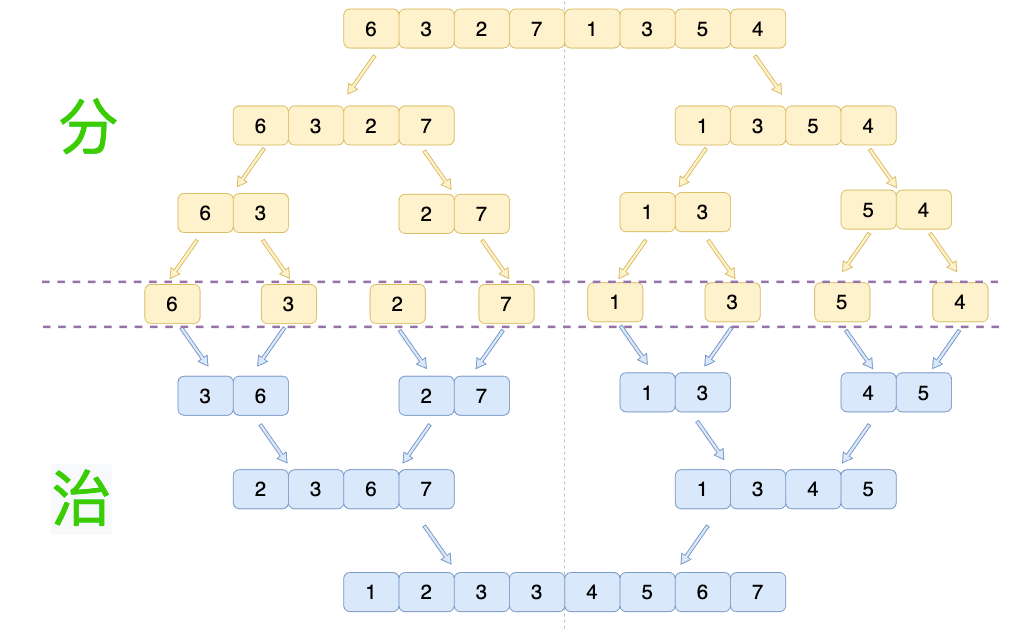
合并 我們來具體看看例子,假設我們現在給定一個數組:[6,3,2,7,1,3,5,4],我們需要使用歸并算法對其排序,其大致過程如下圖所示: 分 階段可以理解為就是 遞歸拆分子序列 的




 工商網監
工商網監
評論