 效率加倍,高并發場景下的接口請求合并方案
效率加倍,高并發場景下的接口請求合并方案

前言
請求合并到底有什么意義呢?我們來看下圖。
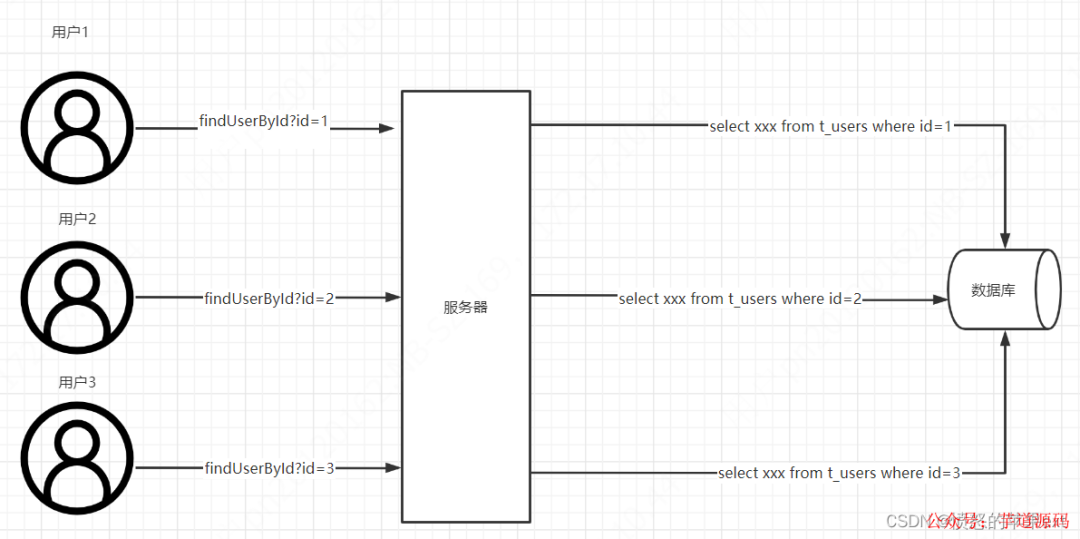
假設我們3個用戶(用戶id分別是1、2、3),現在他們都要查詢自己的基本信息,請求到服務器,服務器端請求數據庫,發出3次請求。我們都知道數據庫連接資源是相當寶貴的,那么我們怎么盡可能節省連接資源呢?
這里把數據庫換成被調用的遠程服務,也是同樣的道理。
我們改變下思路,如下圖所示。
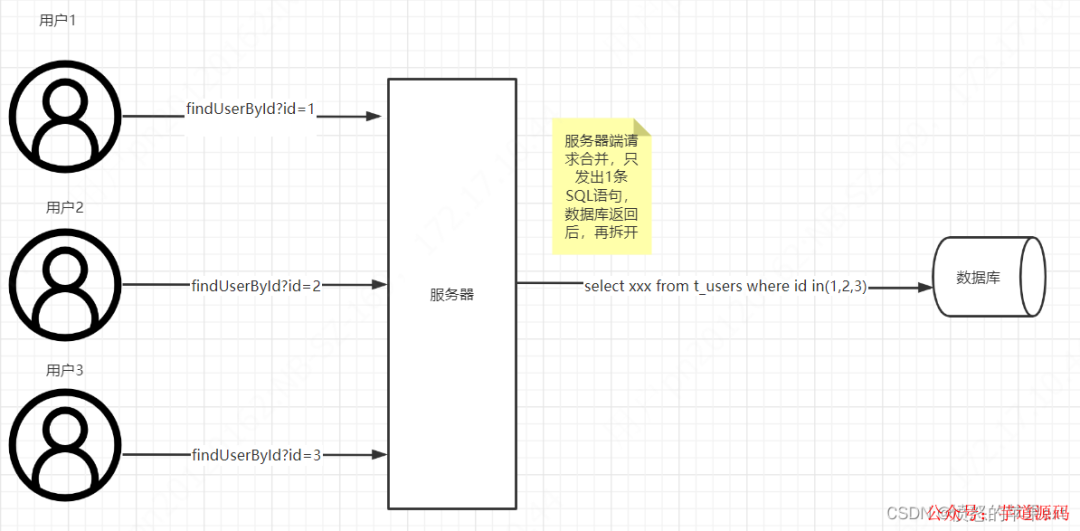
我們在服務器端把請求合并,只發出一條SQL查詢數據庫,數據庫返回后,服務器端處理返回數據,根據一個唯一請求ID,把數據分組,返回給對應用戶。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
技術手段
-
LinkedBlockQueue阻塞隊列 -
ScheduledThreadPoolExecutor定時任務線程池 -
CompleteableFuture future阻塞機制(Java 8 的 CompletableFuture 并沒有 timeout 機制,后面優化,使用了隊列替代)
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/yudao-cloud
- 視頻教程:https://doc.iocoder.cn/video/
代碼實現
查詢用戶的代碼
publicinterfaceUserService{
MapqueryUserByIdBatch(ListuserReqs) ;
}
@Service
publicclassUserServiceImplimplementsUserService{
@Resource
privateUsersMapperusersMapper;
@Override
publicMapqueryUserByIdBatch(ListuserReqs) {
//全部參數
ListuserIds=userReqs.stream().map(UserWrapBatchService.Request::getUserId).collect(Collectors.toList());
QueryWrapperqueryWrapper=newQueryWrapper<>();
//用in語句合并成一條SQL,避免多次請求數據庫的IO
queryWrapper.in("id",userIds);
Listusers=usersMapper.selectList(queryWrapper);
Map>userGroup=users.stream().collect(Collectors.groupingBy(Users::getId));
HashMapresult=newHashMap<>();
userReqs.forEach(val->{
ListusersList=userGroup.get(val.getUserId());
if(!CollectionUtils.isEmpty(usersList)){
result.put(val.getRequestId(),usersList.get(0));
}else{
//表示沒數據
result.put(val.getRequestId(),null);
}
});
returnresult;
}
}
合并請求的實現
packagecom.springboot.sample.service.impl;
importcom.springboot.sample.bean.Users;
importcom.springboot.sample.service.UserService;
importorg.springframework.stereotype.Service;
importjavax.annotation.PostConstruct;
importjavax.annotation.Resource;
importjava.util.*;
importjava.util.concurrent.*;
/***
*zzq
*包裝成批量執行的地方
**/
@Service
publicclassUserWrapBatchService{
@Resource
privateUserServiceuserService;
/**
*最大任務數
**/
publicstaticintMAX_TASK_NUM=100;
/**
*請求類,code為查詢的共同特征,例如查詢商品,通過不同id的來區分
*CompletableFuture將處理結果返回
*/
publicclassRequest{
//請求id唯一
StringrequestId;
//參數
LonguserId;
//TODOJava8的CompletableFuture并沒有timeout機制
CompletableFuturecompletableFuture;
publicStringgetRequestId(){
returnrequestId;
}
publicvoidsetRequestId(StringrequestId){
this.requestId=requestId;
}
publicLonggetUserId(){
returnuserId;
}
publicvoidsetUserId(LonguserId){
this.userId=userId;
}
publicCompletableFuturegetCompletableFuture(){
returncompletableFuture;
}
publicvoidsetCompletableFuture(CompletableFuturecompletableFuture){
this.completableFuture=completableFuture;
}
}
/*
LinkedBlockingQueue是一個阻塞的隊列,內部采用鏈表的結果,通過兩個ReenTrantLock來保證線程安全
LinkedBlockingQueue與ArrayBlockingQueue的區別
ArrayBlockingQueue默認指定了長度,而LinkedBlockingQueue的默認長度是Integer.MAX_VALUE,也就是無界隊列,在移除的速度小于添加的速度時,容易造成OOM。
ArrayBlockingQueue的存儲容器是數組,而LinkedBlockingQueue是存儲容器是鏈表
兩者的實現隊列添加或移除的鎖不一樣,ArrayBlockingQueue實現的隊列中的鎖是沒有分離的,即添加操作和移除操作采用的同一個ReenterLock鎖,
而LinkedBlockingQueue實現的隊列中的鎖是分離的,其添加采用的是putLock,移除采用的則是takeLock,這樣能大大提高隊列的吞吐量,
也意味著在高并發的情況下生產者和消費者可以并行地操作隊列中的數據,以此來提高整個隊列的并發性能。
*/
privatefinalQueuequeue=newLinkedBlockingQueue();
@PostConstruct
publicvoidinit(){
//定時任務線程池,創建一個支持定時、周期性或延時任務的限定線程數目(這里傳入的是1)的線程池
ScheduledExecutorServicescheduledExecutorService=Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(()->{
intsize=queue.size();
//如果隊列沒數據,表示這段時間沒有請求,直接返回
if(size==0){
return;
}
Listlist=newArrayList<>();
System.out.println("合并了["+size+"]個請求");
//將隊列的請求消費到一個集合保存
for(inti=0;i//后面的SQL語句是有長度限制的,所以還要做限制每次批量的數量,超過最大任務數,等下次執行
if(i//拿到我們需要去數據庫查詢的特征,保存為集合
ListuserReqs=newArrayList<>();
for(Requestrequest:list){
userReqs.add(request);
}
//將參數傳入service處理,這里是本地服務,也可以把userService看成RPC之類的遠程調用
Mapresponse=userService.queryUserByIdBatch(userReqs);
//將處理結果返回各自的請求
for(Requestrequest:list){
Usersresult=response.get(request.requestId);
request.completableFuture.complete(result);//completableFuture.complete方法完成賦值,這一步執行完畢,下面future.get()阻塞的請求可以繼續執行了
}
},100,10,TimeUnit.MILLISECONDS);
//scheduleAtFixedRate是周期性執行schedule是延遲執行initialDelay是初始延遲period是周期間隔后面是單位
//這里我寫的是初始化后100毫秒后執行,周期性執行10毫秒執行一次
}
publicUsersqueryUser(LonguserId){
Requestrequest=newRequest();
//這里用UUID做請求id
request.requestId=UUID.randomUUID().toString().replace("-","");
request.userId=userId;
CompletableFuturefuture=newCompletableFuture<>();
request.completableFuture=future;
//將對象傳入隊列
queue.offer(request);
//如果這時候沒完成賦值,那么就會阻塞,直到能夠拿到值
try{
returnfuture.get();
}catch(InterruptedExceptione){
e.printStackTrace();
}catch(ExecutionExceptione){
e.printStackTrace();
}
returnnull;
}
}
控制層調用
/***
*請求合并
**/
@RequestMapping("/merge")
publicCallablemerge(LonguserId) {
returnnewCallable(){
@Override
publicUserscall()throwsException{
returnuserBatchService.queryUser(userId);
}
};
}
Callable是什么可以參考:
- https://blog.csdn.net/baidu_19473529/article/details/123596792
模擬高并發查詢的代碼
packagecom.springboot.sample;
importorg.springframework.web.client.RestTemplate;
importjava.util.Random;
importjava.util.concurrent.CountDownLatch;
publicclassTestBatch{
privatestaticintthreadCount=30;
privatefinalstaticCountDownLatchCOUNT_DOWN_LATCH=newCountDownLatch(threadCount);//為保證30個線程同時并發運行
privatestaticfinalRestTemplaterestTemplate=newRestTemplate();
publicstaticvoidmain(String[]args){
for(inti=0;i//循環開30個線程
newThread(newRunnable(){
publicvoidrun(){
COUNT_DOWN_LATCH.countDown();//每次減一
try{
COUNT_DOWN_LATCH.await();//此處等待狀態,為了讓30個線程同時進行
}catch(InterruptedExceptione){
e.printStackTrace();
}
for(intj=1;j<=?3;j++){
intparam=newRandom().nextInt(4);
if(param<=0){
param++;
}
StringresponseBody=restTemplate.getForObject("http://localhost:8080/asyncAndMerge/merge?userId="+param,String.class);
System.out.println(Thread.currentThread().getName()+"參數"+param+"返回值"+responseBody);
}
}
}).start();
}
}
}
測試效果
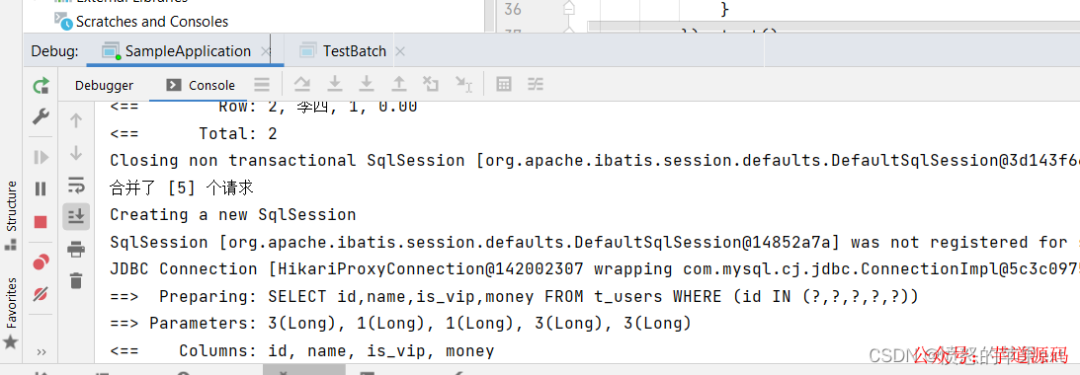
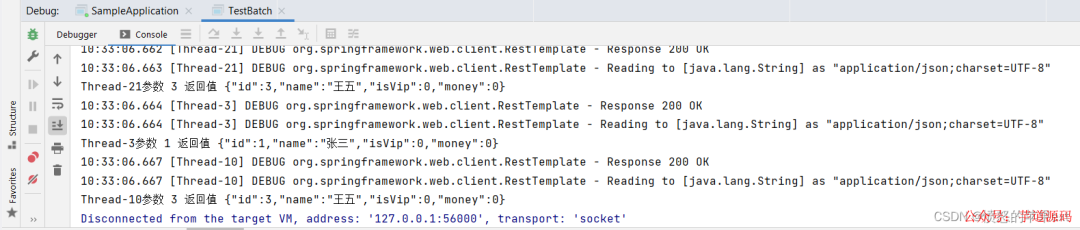
要注意的問題
- Java 8 的 CompletableFuture 并沒有 timeout 機制
- 后面的SQL語句是有長度限制的,所以還要做限制每次批量的數量,超過最大任務數,等下次執行(本例中加了MAX_TASK_NUM判斷)
使用隊列的超時解決Java 8 的 CompletableFuture 并沒有 timeout 機制
核心代碼
packagecom.springboot.sample.service.impl;
importcom.springboot.sample.bean.Users;
importcom.springboot.sample.service.UserService;
importorg.springframework.stereotype.Service;
importjavax.annotation.PostConstruct;
importjavax.annotation.Resource;
importjava.util.*;
importjava.util.concurrent.*;
/***
*zzq
*包裝成批量執行的地方,使用queue解決超時問題
**/
@Service
publicclassUserWrapBatchQueueService{
@Resource
privateUserServiceuserService;
/**
*最大任務數
**/
publicstaticintMAX_TASK_NUM=100;
/**
*請求類,code為查詢的共同特征,例如查詢商品,通過不同id的來區分
*CompletableFuture將處理結果返回
*/
publicclassRequest{
//請求id
StringrequestId;
//參數
LonguserId;
//隊列,這個有超時機制
LinkedBlockingQueueusersQueue;
publicStringgetRequestId(){
returnrequestId;
}
publicvoidsetRequestId(StringrequestId){
this.requestId=requestId;
}
publicLonggetUserId(){
returnuserId;
}
publicvoidsetUserId(LonguserId){
this.userId=userId;
}
publicLinkedBlockingQueuegetUsersQueue() {
returnusersQueue;
}
publicvoidsetUsersQueue(LinkedBlockingQueueusersQueue) {
this.usersQueue=usersQueue;
}
}
/*
LinkedBlockingQueue是一個阻塞的隊列,內部采用鏈表的結果,通過兩個ReenTrantLock來保證線程安全
LinkedBlockingQueue與ArrayBlockingQueue的區別
ArrayBlockingQueue默認指定了長度,而LinkedBlockingQueue的默認長度是Integer.MAX_VALUE,也就是無界隊列,在移除的速度小于添加的速度時,容易造成OOM。
ArrayBlockingQueue的存儲容器是數組,而LinkedBlockingQueue是存儲容器是鏈表
兩者的實現隊列添加或移除的鎖不一樣,ArrayBlockingQueue實現的隊列中的鎖是沒有分離的,即添加操作和移除操作采用的同一個ReenterLock鎖,
而LinkedBlockingQueue實現的隊列中的鎖是分離的,其添加采用的是putLock,移除采用的則是takeLock,這樣能大大提高隊列的吞吐量,
也意味著在高并發的情況下生產者和消費者可以并行地操作隊列中的數據,以此來提高整個隊列的并發性能。
*/
privatefinalQueuequeue=newLinkedBlockingQueue();
@PostConstruct
publicvoidinit(){
//定時任務線程池,創建一個支持定時、周期性或延時任務的限定線程數目(這里傳入的是1)的線程池
ScheduledExecutorServicescheduledExecutorService=Executors.newScheduledThreadPool(1);
scheduledExecutorService.scheduleAtFixedRate(()->{
intsize=queue.size();
//如果隊列沒數據,表示這段時間沒有請求,直接返回
if(size==0){
return;
}
Listlist=newArrayList<>();
System.out.println("合并了["+size+"]個請求");
//將隊列的請求消費到一個集合保存
for(inti=0;i//后面的SQL語句是有長度限制的,所以還要做限制每次批量的數量,超過最大任務數,等下次執行
if(i//拿到我們需要去數據庫查詢的特征,保存為集合
ListuserReqs=newArrayList<>();
for(Requestrequest:list){
userReqs.add(request);
}
//將參數傳入service處理,這里是本地服務,也可以把userService看成RPC之類的遠程調用
Mapresponse=userService.queryUserByIdBatchQueue(userReqs);
for(RequestuserReq:userReqs){
//這里再把結果放到隊列里
Usersusers=response.get(userReq.getRequestId());
userReq.usersQueue.offer(users);
}
},100,10,TimeUnit.MILLISECONDS);
//scheduleAtFixedRate是周期性執行schedule是延遲執行initialDelay是初始延遲period是周期間隔后面是單位
//這里我寫的是初始化后100毫秒后執行,周期性執行10毫秒執行一次
}
publicUsersqueryUser(LonguserId){
Requestrequest=newRequest();
//這里用UUID做請求id
request.requestId=UUID.randomUUID().toString().replace("-","");
request.userId=userId;
LinkedBlockingQueueusersQueue=newLinkedBlockingQueue<>();
request.usersQueue=usersQueue;
//將對象傳入隊列
queue.offer(request);
//取出元素時,如果隊列為空,給定阻塞多少毫秒再隊列取值,這里是3秒
try{
returnusersQueue.poll(3000,TimeUnit.MILLISECONDS);
}catch(InterruptedExceptione){
e.printStackTrace();
}
returnnull;
}
}
...省略..
@Override
publicMapqueryUserByIdBatchQueue(ListuserReqs) {
//全部參數
ListuserIds=userReqs.stream().map(UserWrapBatchQueueService.Request::getUserId).collect(Collectors.toList());
QueryWrapperqueryWrapper=newQueryWrapper<>();
//用in語句合并成一條SQL,避免多次請求數據庫的IO
queryWrapper.in("id",userIds);
Listusers=usersMapper.selectList(queryWrapper);
Map>userGroup=users.stream().collect(Collectors.groupingBy(Users::getId));
HashMapresult=newHashMap<>();
//數據分組
userReqs.forEach(val->{
ListusersList=userGroup.get(val.getUserId());
if(!CollectionUtils.isEmpty(usersList)){
result.put(val.getRequestId(),usersList.get(0));
}else{
//表示沒數據,這里要new,不然加入隊列會空指針
result.put(val.getRequestId(),newUsers());
}
});
returnresult;
}
...省略...
小結
請求合并,批量的辦法能大幅節省被調用系統的連接資源,本例是以數據庫為例,其他RPC調用也是類似的道理。缺點就是請求的時間在執行實際的邏輯之前增加了等待時間,不適合低并發的場景。
代碼地址
- https://gitee.com/apple_1030907690/spring-boot-kubernetes/tree/v1.0.5
參考
- https://www.cnblogs.com/oyjg/p/13099998.html
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
接口
+關注
關注
33文章
9520瀏覽量
157021 -
服務器
+關注
關注
14文章
10253瀏覽量
91482 -
數據庫
+關注
關注
7文章
4020瀏覽量
68340
原文標題:效率加倍,高并發場景下的接口請求合并方案
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
彈性負載均衡:現代 IT 架構的高可用與高并發基石
前言在數字化浪潮下,互聯網服務的訪問量呈爆炸式增長,單臺服務器早已難以承載海量并發請求。此時,負載均衡(LoadBalancing)技術應運而生,成為優化資源分配、提升系統性能的核心支撐。作為現代

Neway電機方案在電機控制的應用場景
應用場景:通過DC-DC轉換將48V輸入轉換為24V輸出,適配驅動器需求,為CNC機床主軸提供穩定電源。優勢體現:高功率密度:GaN模塊的高功率密度設計提高了電源效率,降低了能耗,支持
發表于 01-04 10:10
Hi8000大電流高效率升壓恒壓驅動芯片智芯一級代理聚能芯半導體原廠技術支持賦能多場景電源設計
模式切換功能,可根據負載大小自動切換 PWM、PFM 和 BURST 模式,確保輕、中、重負載全場景下均保持高電源系統效率,避免傳統芯片在輕載時能效下滑的痛點。低待機關機功能同樣亮眼,
發表于 12-04 17:09
Temu跨境電商按關鍵字搜索Temu商品API的應用及接口請求示例
Temu跨境電商按關鍵字搜索Temu商品API的應用及接口請求示例 Temu跨境電商按關鍵字搜索Temu商品API的應用場景 Temu跨境電商平臺按關鍵字搜索Temu商品API的主要應用場景包括但不
工業物聯網數據中臺的高并發性有什么作用
工業物聯網數據中臺的高并發性是保障其在復雜工業場景下穩定運行的核心能力之一。它的核心作用是確保大量設備同時接入和數據傳輸時,系統依然能高效處理、不卡頓、不丟失數據,能夠在單位時間內高效
訂單拆單合并處理接口設計與實現
處理接口能顯著提升系統性能,降低運營開銷。本文將逐步介紹該接口的核心設計、實現細節和使用場景,幫助開發者快速上手。 1. 接口核心功能 該接口

CS、IU系列單聲道音頻功放 —— 覆蓋從低功耗到高功率的全場景解決方案
CS、IU系列單聲道音頻功放 —— 覆蓋從低功耗到高功率的全場景解決方案
在音頻應用中,不同場景對功放的要求差異巨大:從便攜式設備的低功耗,到家庭影院、專業音響的
發表于 09-16 09:07
有沒有針對特定行業或場景的裝置數據驗證效率提升方案?
)、工業制造(汽車 / 化工)、數據中心、醫療行業四大典型場景,提供定制化的驗證效率提升方案,兼顧 “效率” 與 “行業合規性”。 一、新能源場站(光伏 / 風電):解決 “地理分散、

Nginx高并發優化方案
作為一名在生產環境中摸爬滾打多年的運維工程師,我見過太多因為Nginx配置不當導致的性能瓶頸。今天分享一套完整的Nginx高并發優化方案,幫助你的系統從10萬QPS突破到百萬級別。
NVMe高速傳輸之擺脫XDMA設計19:PCIe請求模塊設計(下)
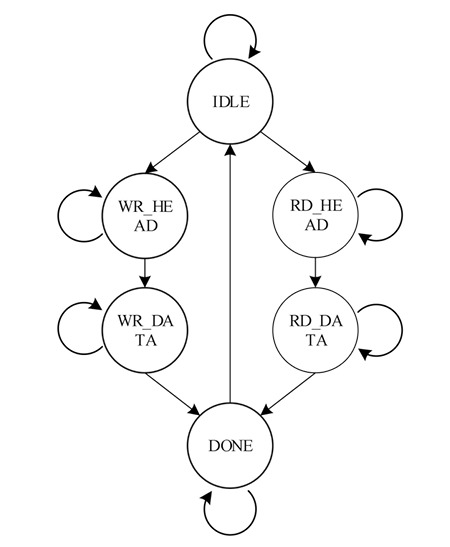
組裝寫請求的TLP報頭,并將報頭通過axis_rq接口發送。當axis_rq接口握手時跳轉到WR_DATA狀態。WR_DATA:請求寫TLP數據發送狀態。該狀態
發表于 08-11 15:24
NVMe高速傳輸之擺脫XDMA設計13:PCIe請求模塊設計(下)
避免異常情況的出現。
WR_HEAD:請求寫TLP頭發送狀態。該狀態下根據請求類型、請求地址組裝寫請求的TLP報頭,并將報頭通過axis
發表于 08-04 16:39
NVMe高速傳輸之擺脫XDMA設計13:PCIe請求模塊設計(下)
在接收到請求總線接口的請求事務后,當請求類型的值為0時,表示通過PCIE硬核的配置管理接口發送請求
鴻蒙5開發寶藏案例分享---應用并發設計
?** 鴻蒙并發編程實戰指南:解鎖ArkTS多線程黑科技**
嘿,開發者朋友們! 今天給大家扒一扒鴻蒙官方文檔里藏著的并發編程寶藏—— 100+實戰場景解決方案 !從金融理財到游戲開發
發表于 06-12 16:19
Ingress網關高并發請求的解決方案
當 Ingress 網關面臨高并發請求(如 QPS 超過 10萬+)時,可能導致服務崩潰、響應延遲激增或資源耗盡。
TurMass? 如何幫助解決 UWB 定位系統大規模終端標簽高并發通信沖突問題?
在大容量定位終端數據高并發場景中,現有通信技術因信號沖突、系統容量受限等問題,難以滿足需求。TurMass? 通信技術通過多信道設計、時隙劃分、定位與通信一體化等創新方案,有效解決了




 工商網監
工商網監
評論