 騰訊優圖/浙大/北大提出:重新思考高效神經模型的移動模塊
騰訊優圖/浙大/北大提出:重新思考高效神經模型的移動模塊

引言
本文重新思考了 MobileNetv2 中高效的倒殘差模塊 Inverted Residual Block 和 ViT 中的有效 Transformer 的本質統一,歸納抽象了 MetaMobile Block 的一般概念。受這種現象的啟發,作者設計了一種面向移動端應用的簡單而高效的現代反向殘差移動模塊 (InvertedResidualMobileBlock,iRMB),它吸收了類似 CNN 的效率來模擬短距離依賴和類似 Transformer 的動態建模能力來學習長距離交互。所提出的高效模型 (EfficientMOdel,EMO) 在 ImageNet-1K、COCO2017 和 ADE20K 基準上獲取了優異的綜合性能,超過了同等算力量級下基于 CNN/Transformer 的 SOTA 模型,同時很好地權衡模型的準確性和效率。
動機
近年來,隨著對存儲和計算資源受限的移動應用程序需求的增加,涌現了非常多參數少、FLOPs 低的輕量級模型,例如Inceptionv3時期便提出了使用非對稱卷積代替標準卷積。后來MobileNet提出了深度可分離卷積 depth-wise separable convolution 以顯著減少計算量和參數,一度成為了輕量化網絡的經典之作。在此基礎上,MobileNetv2 提出了一種基于 Depth-Wise Convolution (DW-Conv) 的高效倒置殘差塊(IRB),更是成為標準的高效模塊代表作之一。然而,受限于靜態 CNN 的歸納偏差影響,純 CNN 模型的準確性仍然保持較低水平,以致于后續的輕量化之路并沒有涌現出真正意義上的突破性工作。
Swin
PVT
Eatformer
EAT
隨著 Transformer 在 CV 領域的崛起,一時間涌現了許多性能性能超群的網絡,如 Swin transformer、PVT、Eatformer、EAT等。得益于其動態建模和不受歸納偏置的影響,這些方法都取得了相對 CNN 的顯著改進。然而,受多頭自注意(MHSA)參數和計算量的二次方限制,基于 Transformer 的模型往往具有大量資源消耗,因此也一直被吐槽落地很雞肋。
針對 Transformer 的這個弊端,當然也提出了一些解決方案:
設計具有線性復雜性的變體,如FAVOR+和Reformer等;
降低查詢/值特征的空間分辨率,如Next-vit、PVT、Cvt等;
重新排列通道比率來降低 MHSA 的復雜性,如Delight;
不過這種小修小改還是難成氣候,以致于后續也出現了許多結合輕量級 CNN 設計高效的混合模型,并在準確性、參數和 FLOPs 方面獲得比基于 CNN 的模型更好的性能,例如Mobilevit、MobileViTv2和Mobilevitv3等。然而,這些方法通常也會引入復雜的結構,或者更甚者直接采用多個混合的模塊如Edgenext和Edgevits,這其實是不利于優化的。
總而言之,目前沒有任何基于 Transformer 或混合的高效塊像基于 CNN 的 IRB 那樣流行。因此,受此啟發,作者重新考慮了 MobileNetv2 中的 Inverted Residual Block 和 Transformer 中的 MHSA/FFN 模塊,歸納抽象出一個通用的 Meta Mobile Block,它采用參數擴展比 λ 和高效算子 F 來實例化不同的模塊,即 IRB、MHSA 和前饋網絡 (FFN)。
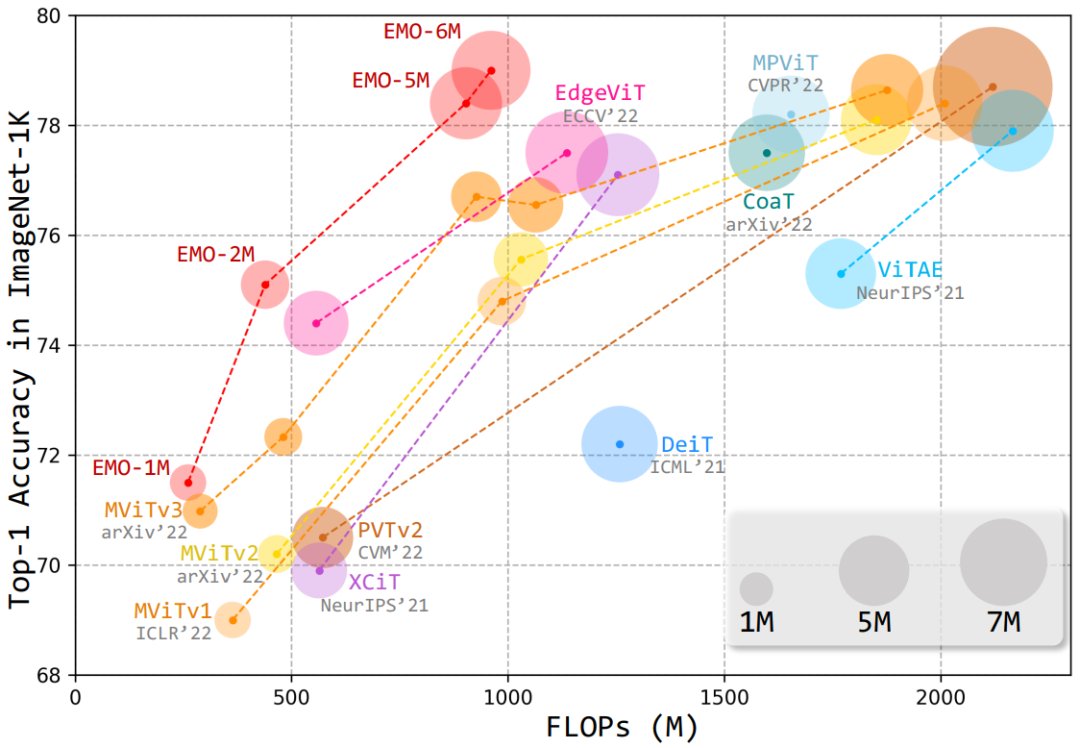
基于此,本文提出了一種簡單高效的模塊——反向殘差移動塊(iRMB),通過堆疊不同層級的 iRMB,進而設計了一個面向移動端的輕量化網絡模型——EMO,它能夠以相對較低的參數和 FLOPs 超越了基于 CNN/Transformer 的 SOTA 模型,如下圖所示:
方法
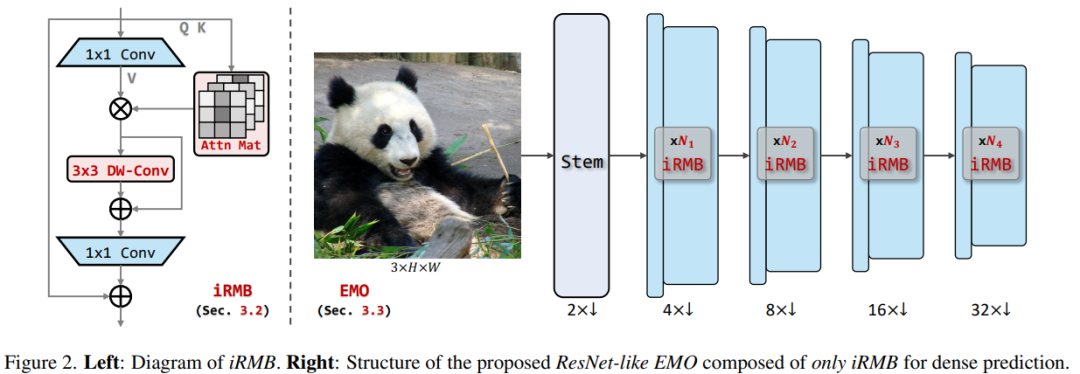
EMO
上圖是整體框架圖,左邊是 iRMB 模塊的示例圖。下面讓我們進一步拆解下這個網絡結構圖。
Meta Mobile Block
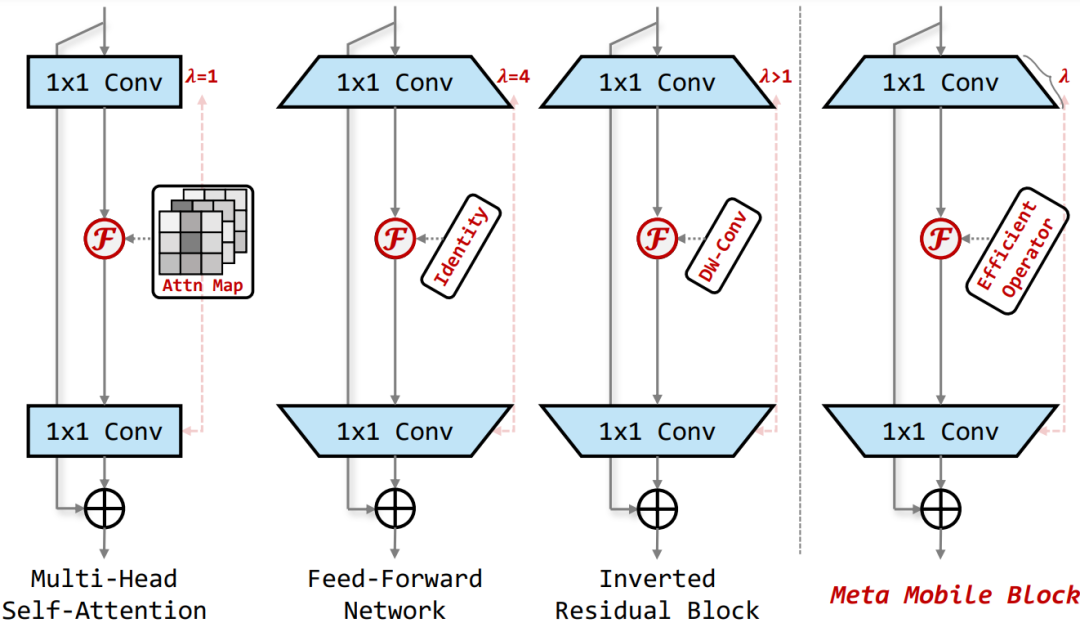
Meta Mobile Block
如上所述,通過對 MobileNetv2 中的 Inverted Residual Block 以及 Transformer 中的核心 MHSA 和 FFN 模塊進行抽象,作者提出了一種統一的 Meta Mobile (M2) Block 對上述結構進行統一的表示,通過采用參數擴展率 λ 和高效算子 F 來實例化不同的模塊。
Inverted Residual Mobile Block
基于歸納的 M2 塊,本文設計了一個反向殘差移動塊 (iRMB),它吸收了 CNN 架構的效率來建模局部特征和 Transformer 架構動態建模的能力來學習長距離交互。
具體實現中,iRMB 中的 F 被建模為級聯的 MHSA 和卷積運算,公式可以抽象為 。這里需要考慮的問題主要有兩個:
通常大于中間維度將是輸入維度的倍數,導致參數和計算的二次增加。
MHSA 的 FLOPs 與總圖像像素的二次方成正比。
具體的參數比對大家可以簡單看下這個表格:
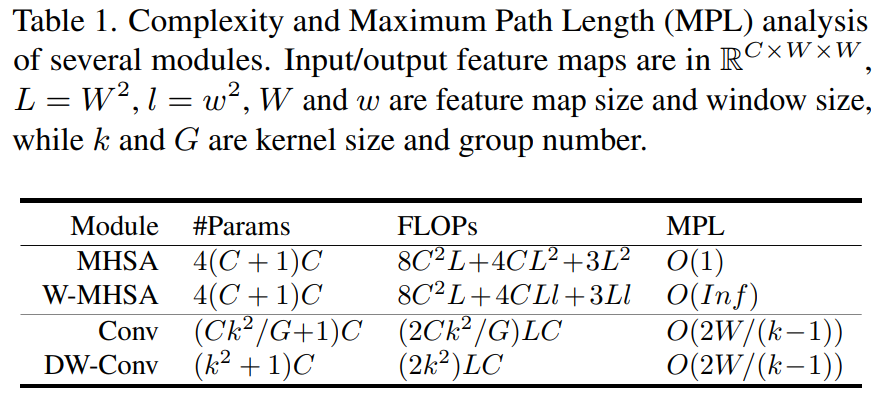
因此,作者很自然的考慮結合 W-MHSA 和 DW-Conv 并結合殘差機制設計了一種新的模塊。此外,通過這種級聯方式可以提高感受野的擴展率,同時有效的將模型的 MPL 降低到 。
為了評估 iRMB 性能,作者將 λ 設置為 4 并替換 DeiT 和 PVT 中標準的 Transformer 結構。如下述表格所述,我們可以發現 iRMB 可以在相同的訓練設置下以更少的參數和計算提高性能。
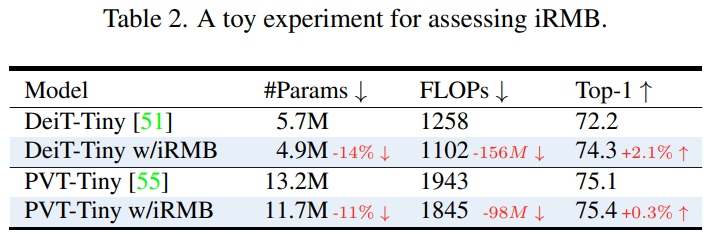
EMO
為了更好的衡量移動端輕量化模型的性能,作者定義了以下4個標準:
可用性。即不使用復雜運算符的簡單實現,易于針對應用程序進行優化。
簡約性。即使用盡可能少的核心模塊以降低模型復雜度。
有效性。即良好的分類和密集預測性能。
高效性。即更少的參數和計算精度權衡。
下面的表格總結了本文方法與其它幾個主流的輕量化模型區別:
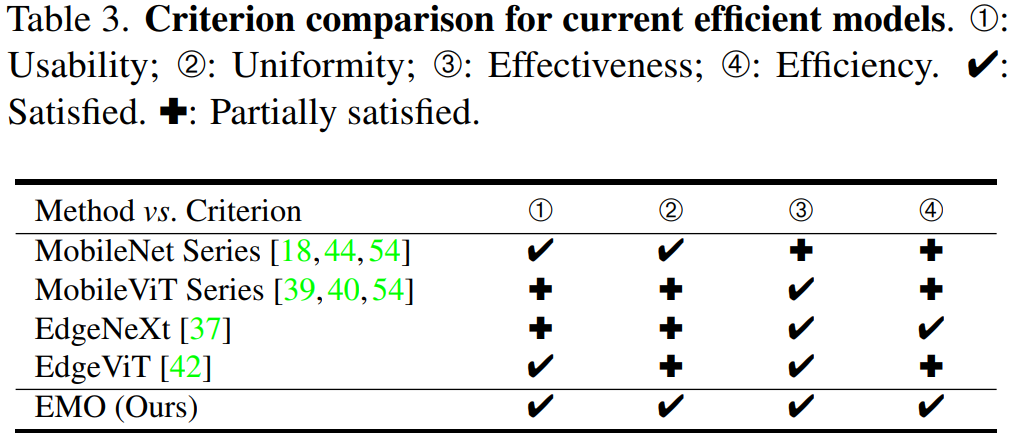
可以觀察到以下幾點現象:
基于 CNN 的 MobileNet 系列的性能現在看起來略低,而且其參數略高于同行;
近期剛提出的 MobileViT 系列雖然取得了更優異的性能,但它們的 FLOPs 較高,效率方面欠佳;
EdgeNeXt 和 EdgeViT 的主要問題是設計不夠優雅,模塊較為復雜;
基于上述標準,作者設計了一個由多個 iRMB 模塊堆疊而成的類似于 ResNet 的高效模型——EMO,主要體現在以下幾個優勢:
1)對于整體框架,EMO 僅由 iRMB 組成,沒有多樣化的模塊,這在設計思想上可稱得上大道至簡;
2)對于特定模塊,iRMB 僅由標準卷積和多頭自注意力組成,沒有其他復雜的運算符。此外,受益于 DW-Conv,iRMB 還可以通過步長適應下采樣操作,并且不需要任何位置嵌入來向 MHSA 引入位置偏差;
3)對于網絡的變體設置,作者采用逐漸增加的擴展率和通道數,詳細配置如下表所示。
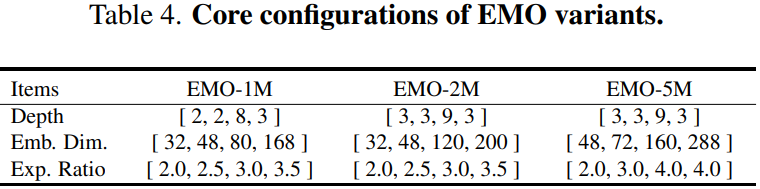
由于 MHSA 更適合為更深層的語義特征建模,因此 EMO 僅在第3和第4個stage采用它。為了進一步提高 EMO 的穩定性和效率,作者還在第1和第2個stage引入 BN 和 SiLU 的組合,而在第3和第4個stage替換成 LN 和 GeLU 的組合,這也是大部分 CNN 和 Transformer 模型的優先配置。
實驗
參數比對
先來看下 EMO 和其他輕量化網絡的相關超參比對:
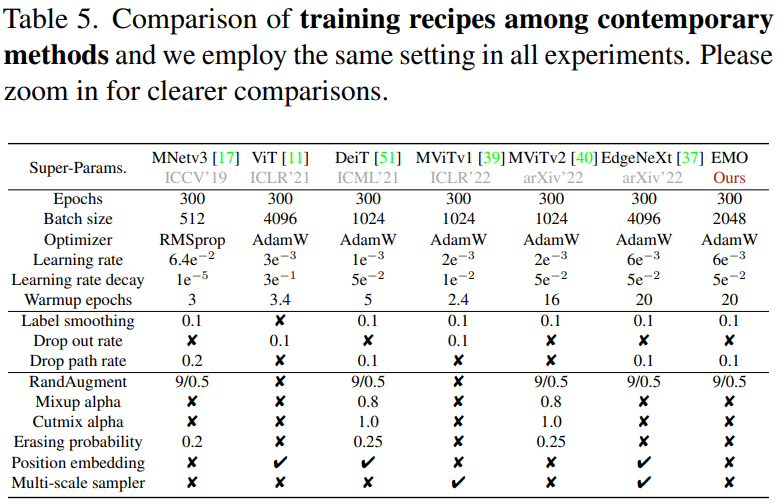
可以看到,EMO 并沒有使用大量的強 DataAug 和 Tricks,這也充分體現了其模塊設計的有效性。
性能指標
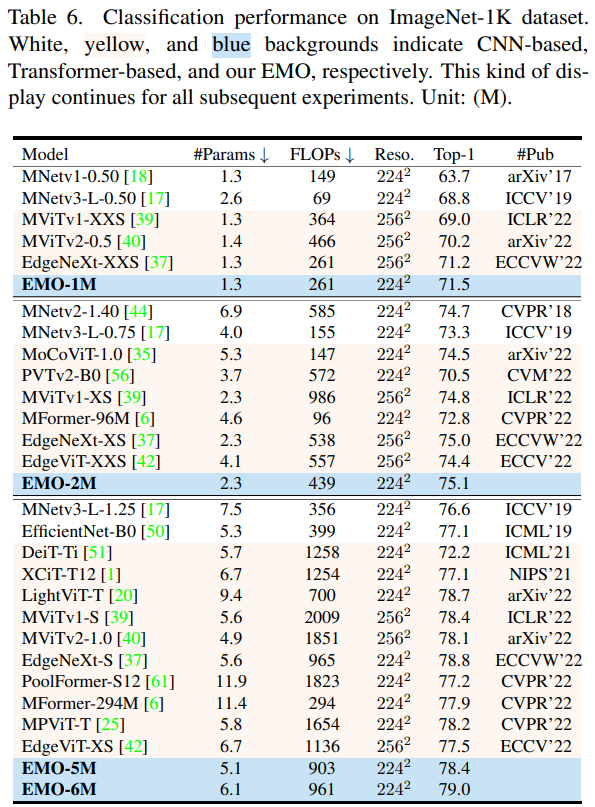
圖像分類
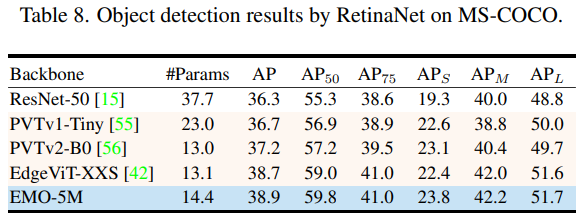
目標檢測
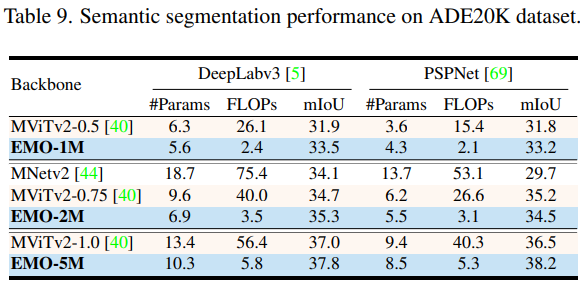
語義分割
整體來看,EMO 在圖像分類、目標檢測和語義分割 CV 三大基礎任務都表現強勁,可以以較少的計算量和參數量取得更加有競爭力的結果。
可視化效果

Qualitative comparisons with MobileNetv2 on two main downstream tasks
從上面的可視化結果可以明顯的觀察到,本文提出的方法在分割的細節上表現更優異。

Attention Visualizations by Grad-CAM
為了更好地說明本文方法的有效性,作者進一步采用 Grad-CAM 方法突出顯示不同模型的相關區域。如上圖所示,基于 CNN 的 ResNet 傾向于關注特定對象,而基于 Transformer 的 MPViT 更關注全局特征。相比之下,EMO 可以更準確地關注顯著物體,同時保持感知全局區域的能力。這在一定程度上也解釋了為什么 EMO 在各類任務中能獲得更好的結果。
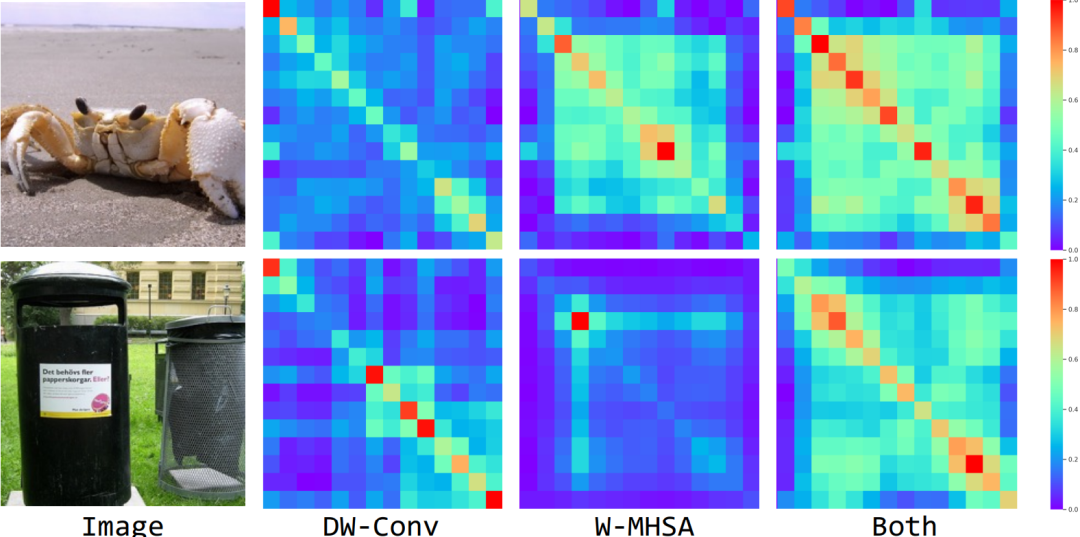
Feature Similarity Visualizations
上面我們提到過,通過級聯 Convolution 和 MHSA 操作可以有效提高感受野的擴展速度。為了驗證此設計的有效性,這里將第3個Stage中具有不同組成的對角線像素的相似性進行可視化,即可視化 DW-Conv 和 EW-MHSA 以及同時結合兩個模塊。

可以看出,無論從定量或定性的實驗結果看來,當僅使用 DW-Conv 時,特征往往具有短距離相關性,而 EW-MHSA 帶來更多的長距離相關性。相比之下,當同時采用這兩者時,網絡具有更大感受野的模塊,即更好的建模遠距離的上下文信息。
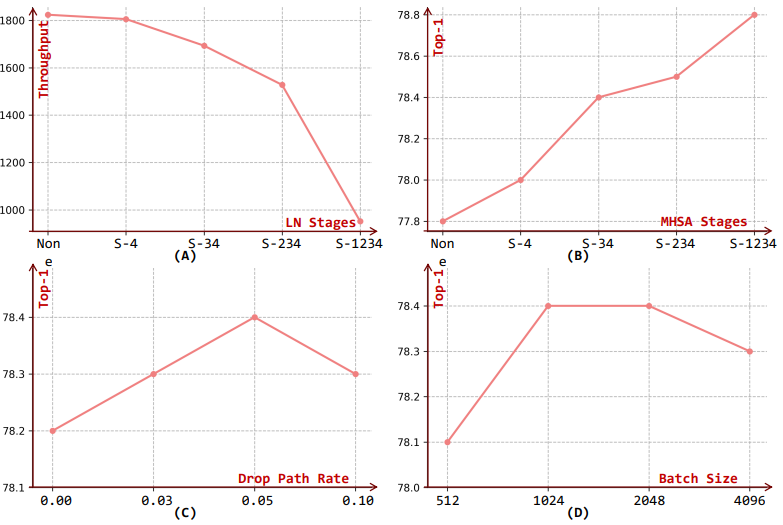
Ablation studies on ImageNet-1K with EMO-5M
最后展示的是本文的消融實驗,整體來說實驗部分還是挺充實的,感興趣的小伙伴去看下原文,時間有限,今天我們就分析到這里。
結論
本文探討了面向移動端的高效架構設計,通過重新思考 MobileNetv2 中高效的 Inverted Residual Block 和 ViT 中的有效 Transformer 的本質統一,作者引入了一個稱為 Meta Mobile Block 的通用概念,進而推導出一個簡單而高效的現代 iRMB 模塊。具體地,該模塊包含兩個核心組件,即 DW-Conv 和 EW-MHSA,這兩個組件可以充分利用 CNN 的效率來建模短距離依賴同時結合 Transformer 的動態建模能力來學習長距離交互。最后,通過以不同的規模堆疊 iRMB 模塊搭建了一個高效的類 ResNet 架構——EMO,最終在 ImageNet-1K、COCO2017 和 ADE20K 三個基準測試的大量實驗證明了 EMO 優于其它基于 CNN 或 Transformer 的 SoTA 方法。
審核編輯 :李倩
-
圖像
+關注
關注
2文章
1096瀏覽量
42330 -
模型
+關注
關注
1文章
3752瀏覽量
52111 -
cnn
+關注
關注
3文章
355瀏覽量
23425
原文標題:騰訊優圖/浙大/北大提出:重新思考高效神經模型的移動模塊
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Arm率先適配騰訊混元HY-1.8B-2Bit模型
大模型中常提的快慢思考會對自動駕駛產生什么影響?

NMSIS神經網絡庫使用介紹
脈沖神經元模型的硬件實現
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
騰訊地圖在AI時代的全新思考與實踐
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+神經形態計算、類腦芯片
3萬字長文!深度解析大語言模型LLM原理

小白學大模型:國外主流大模型匯總
硬件與應用同頻共振,英特爾Day 0適配騰訊開源混元大模型
摩爾線程率先支持騰訊混元-A13B模型
CoT 數據集如何讓大模型學會一步一步思考?

基于RV1126開發板移植NCNN部署庫方法
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
?適配 17 款國產 AI 芯片,中國移動推出九天 AI 大模型?



 工商網監
工商網監
評論