") 一種新的輕量級(jí)視覺Transformer
一種新的輕量級(jí)視覺Transformer

Introduction
隨著 ViT 的出現(xiàn),Transformer 模型在計(jì)算機(jī)視覺領(lǐng)域遍地開花,一層激起一層浪。雖然精度很高,但被人廣為詬病的依舊是它的效率問題,說(shuō)人話就是這東西壓根不好部署在移動(dòng)端。
隨后,有許多研究人員提出了很多解決方案來(lái)加速注意力機(jī)制,例如早先蘋果提出的 Mobile-Former 以及前段時(shí)間的 EdgeNeXt,均是針對(duì)移動(dòng)端設(shè)計(jì)的。
本文的思路也很簡(jiǎn)單,就是仿造 CNNs 圈子中的移動(dòng)端之王—— MobileNet 來(lái)進(jìn)行一系列的設(shè)計(jì)和優(yōu)化。對(duì)于端側(cè)部署來(lái)講,模型的參數(shù)量(例如 Flash 大小)和延遲對(duì)資源受限型的硬件來(lái)說(shuō)至關(guān)重要。因此,作者結(jié)合了細(xì)粒度聯(lián)合搜索策略,提出了一種具備低延遲和大小的高效網(wǎng)絡(luò)——EfficientFormerV2 ,該網(wǎng)絡(luò)在同等量級(jí)參數(shù)量和延遲下比 MobileNetV2 可以高出4個(gè)百分點(diǎn)(ImageNet驗(yàn)證集)。
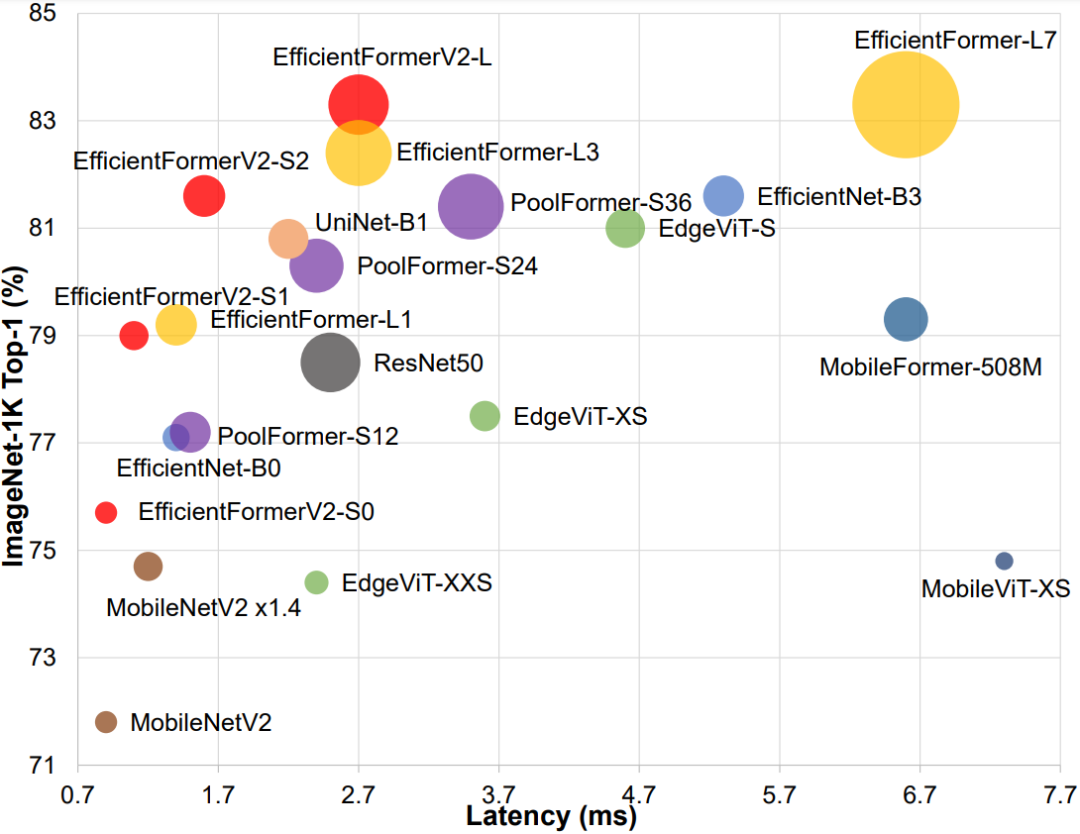 Comparison of model size, speed, and performance
Comparison of model size, speed, and performance上圖所示模型是在 ImageNet-1K 上進(jìn)行訓(xùn)練所獲得的 Top-1 精度。延遲是在 iPhone 12(iOS 16)上進(jìn)行測(cè)量的。每個(gè)圓圈的面積與參數(shù)數(shù)量(模型大小)成正比。可以看出,EfficientFormerV2 在模型更小和推理速度更快的情況下獲得了更高的性能。
Framework
先來(lái)看下整體的網(wǎng)絡(luò)長(zhǎng)什么樣子:
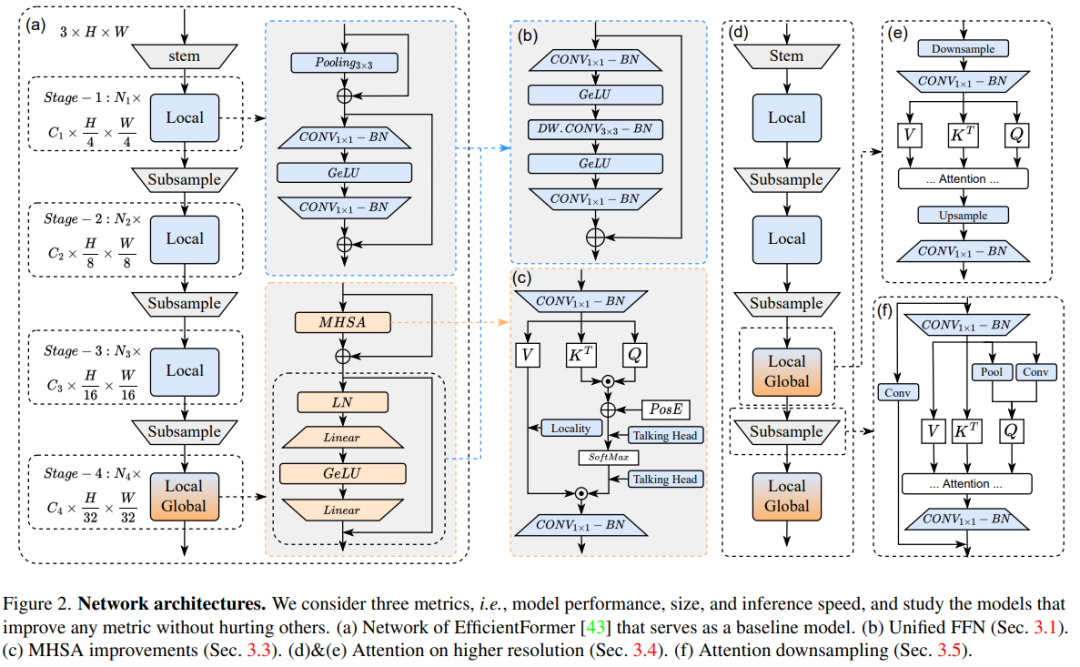 Overall
Overall
既然都叫 EfficientFormerV2,那必然是在上一版的基礎(chǔ)上改進(jìn)了,如圖(a)所示。沒什么特別新奇的,一個(gè)很常規(guī)的 ViT 型架構(gòu)。下面的圖表是作者統(tǒng)計(jì)的實(shí)驗(yàn)改進(jìn)結(jié)果:
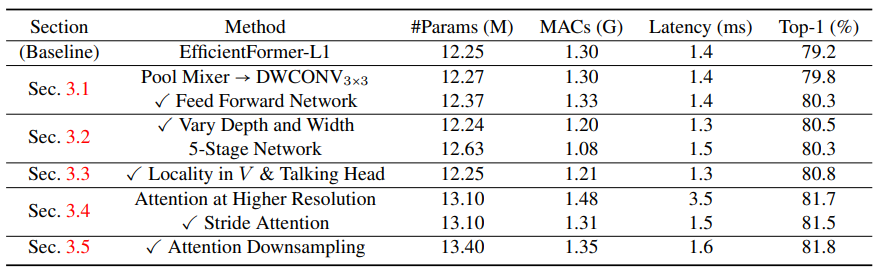 Number of parameters, latency, and performance for various design choices
Number of parameters, latency, and performance for various design choices基于整體架構(gòu)圖和上述表格,讓我們逐步拆解看看究竟做了哪些改進(jìn)。
Token Mixers vs. Feed Forward Network
通常來(lái)說(shuō),結(jié)合局部信息可以有效提高性能,同時(shí)使 ViTs 對(duì)明確的位置嵌入缺失表現(xiàn)得更加穩(wěn)健。PoolFormer 和 EfficientFormer 中都使用了 3×3 的平均池化層(如圖 2(a)所示)作為局部的Token Mixers。采用相同卷積核大小的深度可分離卷積(DWCONV)替換這些層不會(huì)帶來(lái)延遲開銷,同時(shí)性能也能提高 **0.6%**,參數(shù)量?jī)H微漲 0.02M。此外,同 NASVit,作者也在 ViTs 的前饋網(wǎng)絡(luò)(FFN)中注入了局部信息建模層,這也有益于提高性能。
這里,作者直接將原來(lái)的 Pooling 層刪掉了(下采樣越大,理論感受野越大),而是直接替換成 BottleNeck 的形式,先用 1×1 卷積降維壓縮,再嵌入 3×3 的深度可分離卷積提取局部信息,最后再通過 1×1 的卷積升維。這樣做的一個(gè)好處是,這種修改有利于后續(xù)直接才用超參搜索技術(shù)搜索出具體模塊數(shù)量的網(wǎng)絡(luò)深度,以便在網(wǎng)絡(luò)的后期階段中提取局部和全局信息。
Search Space Refinement
通過調(diào)整網(wǎng)絡(luò)的深度即每個(gè)階段中的塊數(shù)和寬度即通道數(shù),可以發(fā)現(xiàn),更深和更窄的網(wǎng)絡(luò)可以帶來(lái):
- 更好的準(zhǔn)確性(0.2% 的性能提升)
- 更少的參數(shù)(0.13M 的參數(shù)壓縮)
- 更低的延遲(0.1ms 的推理加速)
同時(shí)將這個(gè)修改的網(wǎng)絡(luò)設(shè)置為后續(xù) NAS 搜素的 Baseline.
MHSA Improvements
一般的 Transformer 模塊都會(huì)包含兩個(gè)組件,即多頭注意力 MHSA 和全連接層 FFN. 作者隨后便研究了如何在不增加模型大小和延遲的情況下提高注意模塊性能的技術(shù)。
首先,通過 3×3 的卷積將局部信息融入到 Value 矩陣中,這一步跟 NASVit 和 Inception transformer 一樣。
其次,在 Head 維度之間添加 FC 層(就圖中標(biāo)識(shí)的Talking Head),增強(qiáng)不同頭之間的信息交互。
通過這些修改,可以發(fā)現(xiàn)性能進(jìn)一步提高了,與基線模型相比,準(zhǔn)確度達(dá)到了 80.8%,同時(shí)參數(shù)和延遲也基本保持一致。
Attention on Higher Resolution
加入注意力機(jī)制普遍都是能夠提升性能的。然而,將它應(yīng)用于高分辨率特征會(huì)降低端側(cè)的推理效率,因?yàn)樗哂信c空間分辨率成平方關(guān)系的時(shí)間復(fù)雜度。因此,作者僅在最后的 1/32 的空間分辨率下使用,而對(duì)于倒數(shù)的第二階段即 4 倍下采樣提出了另外一種 MHSA,這有助于將準(zhǔn)確率提高了 0.9% 同時(shí)加快推理效率。
先前的解決方案,例如 Cswin transformer 和 Swin transformer 都是采用基于滑動(dòng)窗口的方式去壓縮特征維度,又或者像 Next-vit 一樣直接將 Keys 和 Values 矩陣進(jìn)行下采樣壓縮,這些方法對(duì)于移動(dòng)端部署并不是一個(gè)最佳的選擇。這里也不難理解,以 Swin transformer 為例,它在每個(gè) stage 都需要進(jìn)行復(fù)雜的窗口劃分和重新排序,所以這種基于 windows 的注意力是很難在移動(dòng)設(shè)備上加速優(yōu)化的。而對(duì)于 Next-vit 來(lái)說(shuō)表面上看雖然進(jìn)行了壓縮,但整個(gè) Key 和 Value 矩陣依舊需要全分辨率查詢矩陣(Query)來(lái)保持注意力矩陣乘法后的輸出分辨率。
本文方法的解決方案可以參考圖(d)和(e),整體思路是采用一個(gè)帶步長(zhǎng)的注意力,實(shí)現(xiàn)上就是將所有的 QKV 均下采樣到固定的空間分辨率(這里是 1/32),并將注意力的輸出復(fù)原到原始分辨率以喂入下一層。(⊙o⊙)…,有點(diǎn)類似于把瓶頸層的思路又搬過來(lái)套。
Attention Downsampling
以往的下采樣方式大都是采用帶步長(zhǎng)的卷積或者池化層直接進(jìn)行的。不過最近也有一部分工作在探討 Transformer 模塊內(nèi)部的下采樣方式,如 LeViT 和 UniNet 提出通過注意力機(jī)制將特征分辨率減半,從而更好的整合全局上下文來(lái)進(jìn)感知下采樣。具體的做法也就是將 Query 中的 Token 數(shù)量減半,從而對(duì)注意力模塊的輸出進(jìn)行壓縮。
說(shuō)到這里不經(jīng)意間有個(gè)疑問,Token 數(shù)量減少多少才是合適?況且,如果我們直接就對(duì)所有的查詢矩陣進(jìn)行降采樣的話,這對(duì)于較前的 stage 的特征提取是不利的,因?yàn)榫W(wǎng)絡(luò)的淺層更多的是提取諸如紋理、顏色、邊緣等 low-level 的信息,因此從經(jīng)驗(yàn)上來(lái)看是需要保持更高分辨率的。
作者的方法是提出一種結(jié)合局部和全局上下文融合的組合策略,如上圖(f)所示。為了得到下采樣的查詢,采用池化層作為靜態(tài)局部下采樣,而 3×3 DWCONV 則作為可學(xué)習(xí)的局部下采樣,并將結(jié)果拼接起來(lái)并投影到查詢矩陣中。此外,注意力下采樣模塊殘差連接到一個(gè)帶步長(zhǎng)的卷積以形成局部-全局方式,類似于下采樣瓶頸 或倒置瓶頸層。
Super-Network-Search
上面定義完基礎(chǔ)的網(wǎng)絡(luò)架構(gòu)后,作者又進(jìn)一步的應(yīng)用了一種細(xì)粒度聯(lián)合搜索策略,具體算法步驟如下所示:
 NAS
NAS整體架構(gòu)沿用的是超網(wǎng)的結(jié)構(gòu)。
Conclusion
在這項(xiàng)工作中,作者全面研究混合視覺主干并驗(yàn)證對(duì)于端側(cè)更加友好的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)。此外,基于確定的網(wǎng)絡(luò)結(jié)構(gòu),進(jìn)一步提出了在大小和速度上的細(xì)粒度聯(lián)合搜索,并獲得了輕量級(jí)和推理速度超快的 EfficientFormerV2 模型。
審核編輯 :李倩
-
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1715瀏覽量
47625 -
Transformer
+關(guān)注
關(guān)注
0文章
156瀏覽量
6937
原文標(biāo)題:更快更強(qiáng)!EfficientFormerV2來(lái)了!一種新的輕量級(jí)視覺Transformer
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Transformer如何讓自動(dòng)駕駛大模型獲得思考能力?
瑞芯微SOC智能視覺AI處理器
輕量級(jí)參數(shù)的管理框架(C語(yǔ)言)
Transformer如何讓自動(dòng)駕駛變得更聰明?
【CW32】uart_obj_fw 輕量級(jí)串口框架
Crypto核心庫(kù):顛覆傳統(tǒng)的數(shù)據(jù)安全輕量級(jí)加密方案
基于米爾瑞芯微RK3576開發(fā)板部署運(yùn)行TinyMaix:超輕量級(jí)推理框架
如何在RK3576開發(fā)板上運(yùn)行TinyMaix :超輕量級(jí)推理框架--基于米爾MYD-LR3576開發(fā)板

MQTT介紹
輕量級(jí)≠低效能:RK3506J核心板如何用性價(jià)比感動(dòng)用戶?

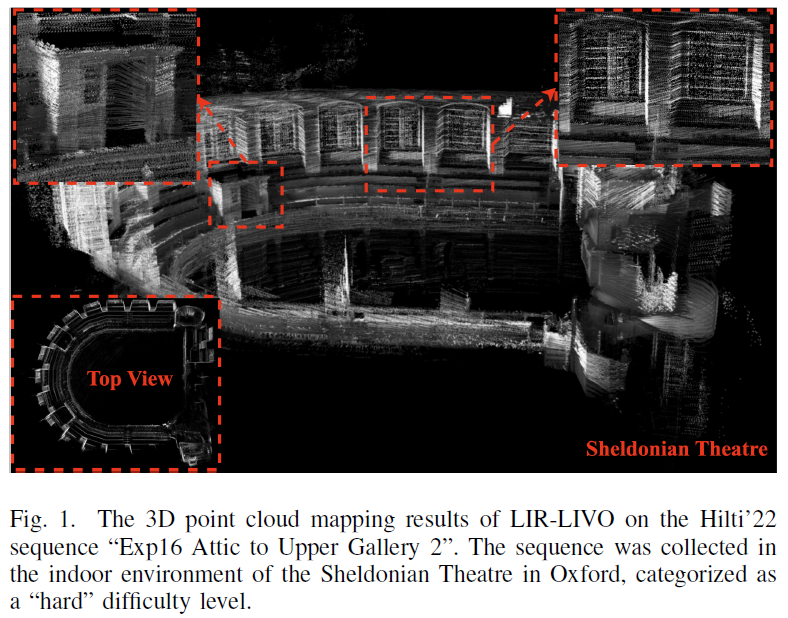
一種新型激光雷達(dá)慣性視覺里程計(jì)系統(tǒng)介紹
樹莓派替代臺(tái)式計(jì)算機(jī)?樹莓派上七款最佳的輕量級(jí)操作系統(tǒng)!

一種基于點(diǎn)、線和消失點(diǎn)特征的單目SLAM系統(tǒng)設(shè)計(jì)

?VLM(視覺語(yǔ)言模型)?詳細(xì)解析

開鴻智谷新一代輕量級(jí)鴻蒙控制器首次公開發(fā)布!“鴻蒙+AI”交通方案斬獲行業(yè)大獎(jiǎng)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論