") 用于中文縮略詞預(yù)測的序列生成模型研究
用于中文縮略詞預(yù)測的序列生成模型研究

研究背景
縮略詞是單詞或短語的縮寫形式。為了方便寫作和表達,在文本中提及某個實體時,人們傾向于使用縮寫名稱而不是它的完整形式(名稱)。理解縮略詞,尤其是實體的縮寫名稱,是知識圖譜構(gòu)建和應(yīng)用的關(guān)鍵步驟。縮略詞處理主要包括三個任務(wù):縮略詞擴展,縮略詞識別和提取,以及縮略詞預(yù)測。毫無疑問,縮略詞處理在各種自然語言處理 (NLP) 任務(wù)中發(fā)揮著重要作用例如信息檢索、實體鏈接等任務(wù)。
在本文中,我們重點關(guān)注縮略詞處理的第三個任務(wù),即縮略詞預(yù)測,其目標是預(yù)測實體完整形式的可能縮寫形式。縮略詞實際上是一個子序列,由一個詞或一些字符按完整形式的順序排列。不同于英文縮略詞(通常是首字母縮略詞),中文縮略詞形式更加復(fù)雜多樣。
如表 1 所示,縮略詞可以是位于實體完整形式中的第一個詞(“復(fù)旦”)也可以是最后一個詞(“迪士尼”),并且可能包含實體中一些不連續(xù)但有序的字符(“北大”)。而且,一個實體的縮略詞可以有多種形式(“央視”或“中央臺”)。因此,作為一項更具挑戰(zhàn)性的任務(wù),中文縮略詞預(yù)測已成為近年來的研究熱點。

▲ 表1. 中文縮略詞的幾個實例
現(xiàn)有的中文縮略詞預(yù)測方法可以被認為是基于特征的方法。它們通常是將縮略詞預(yù)測作為序列標記問題,即對每個 token 作二分類,去判斷是否該字符是否應(yīng)保留在縮略詞中。盡管取得了成就,但以前的方法仍然有以下缺點:一方面,他們只使用轉(zhuǎn)移矩陣來尋找最高概率的標簽,未能充分利用標簽依賴關(guān)系;另一方面,他們忽略了實體相關(guān)文本的豐富信息,只利用實體本身的語義。事實上,我們可以獲取足夠的與給定實體相關(guān)的文本例如百度百科文本、景點 POI 實體評論和 query 文本,能提供模型預(yù)測縮寫的信號。
為了解決這些問題,我們將中文縮略詞預(yù)測看作從全稱實體序列到縮略詞序列的定長機器翻譯任務(wù)。貢獻包括,首先,我們提出了一種用于中文縮略詞預(yù)測的序列生成模型。其次,我們將實體相關(guān)上下文納入中文縮略詞預(yù)測任務(wù),為模型提供了更多語義信息。最后,我們構(gòu)建了旅游中文縮略詞數(shù)據(jù)集。此外,我們在飛豬搜索系統(tǒng)上部署的縮略詞實現(xiàn)了 2.03% 的轉(zhuǎn)化率提升。
研究框架
問題建模:針對給定的一個全稱實體 和其對應(yīng)的相關(guān)文本,CETAR 能生成一個其對應(yīng)的縮略詞序列。
模型框架:我們的模型框架由上下文增強編碼器和縮略-恢復(fù)解碼器組成。圖 2 是 CETAR 模型架構(gòu)框架圖。

▲ 圖2:基于上下文增強和縮略-恢復(fù)策略的縮略詞transformer框架圖
2.1 上下文增強編碼器
首先,將實體的完整形式 x 及其相關(guān)文本 d 都輸入到這個模塊。使用與 BERT 相同的初始化操作得到初始 embedding,以及它們的位置 embedding 一起輸入 transformer encoder block,生成一些重要的特征表示。為了減少數(shù)據(jù)的噪音,最終只取實體對應(yīng)的隱狀態(tài)輸入到解碼器當(dāng)中,以便后續(xù)的解碼。

2.2 縮略-恢復(fù)解碼器
這是我們模型生成縮略詞序列的關(guān)鍵模塊。它是用 transformer decoder block 和縮寫及恢復(fù)策略對應(yīng)的兩個分類器分別構(gòu)成。整個解碼過程是實際上是一個迭代的過程。具體來說,在每一輪開始時,輸入上一輪過程輸出的由 n+2 個 token 組成的 token 序列。然后,每個 token 的初始 embedding 附加其位置 embedding,伴隨著解碼器的輸出 H, 然后輸入第一個 transformer decoder block。最后,我們將最后一個 block 輸出的隱藏狀態(tài)作為后續(xù)兩個分類器的輸入。

隨著所有標記的隱藏狀態(tài),縮寫分類器或恢復(fù)分類器判斷序列中哪個 token 應(yīng)該縮寫或恢復(fù)。在第k輪解碼過程中,縮寫分類器首先判斷序列中的每個 token 是否應(yīng)該縮寫。類似地,恢復(fù)分類器判斷序列中每個特殊的縮略詞*是應(yīng)該保留還是恢復(fù)到相同位置的源 token。如下式所示,其中:

縮略分類器:

恢復(fù)分類器:

最后,縮略詞序列中的所有 * 都被刪除,并且因此我們得到了源實體的最終縮略詞。
實驗結(jié)果
我們將 CETAR 與基線模型在三個中文縮寫數(shù)據(jù)集上進行了比較,其中兩個屬于通用領(lǐng)域,一個屬于特定的景點領(lǐng)域。后者是基于阿里飛豬景點 POI 實體及其別名構(gòu)建的中文縮略詞數(shù)據(jù)集。對于通用領(lǐng)域的數(shù)據(jù)集中的實體,我們選取了其百度百科描述性文本的第一句話作為相關(guān)文本;而對于飛豬中文縮略詞數(shù)據(jù)集中的景點 POI 實體,我們則是以其最相關(guān)的評論文本及 query 文本作為相關(guān)文本。
至于評價指標,首先,我們使用 Hit 作為指標來比較模型的性能。測試樣本被視為命中樣本如果它的預(yù)測縮寫和它 ground-truth 縮寫一模一樣。而 Hit score 是命中樣本占所有測試樣本的比例。此外,考慮到一些實體有多個縮寫,我們進一步考慮了以下指標,這些指標是基于對從測試集中隨機選擇的 500 個樣本的人工評估計算得出的,包括正確樣本、NA、NW 和 WOM 在所有人類評估樣本中的比例。
具體來說,NA 表示預(yù)測的縮略詞是正確的,但和 ground-truth 的縮略詞不同。NW 代表錯誤且語言結(jié)構(gòu)異常的預(yù)測縮略詞,而 WOM 代表錯誤但語言結(jié)構(gòu)正常的預(yù)測縮略詞。具體實例可見表 2。
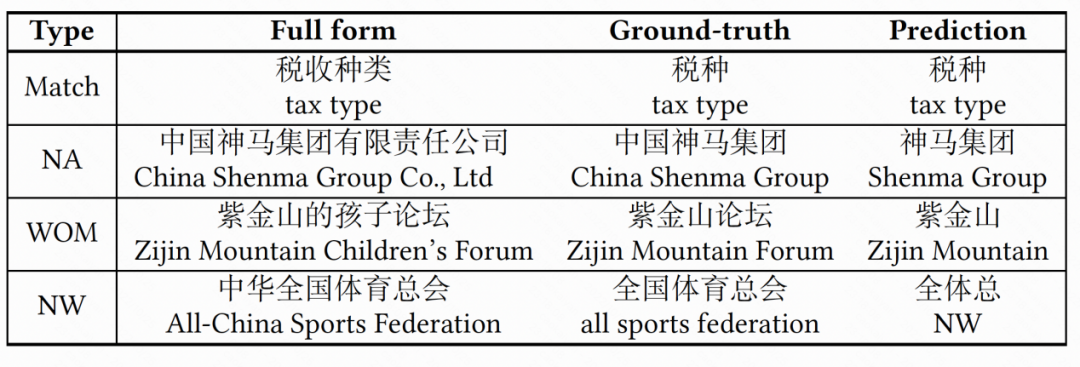
▲ 表2: 縮略詞的四種不同形式實例
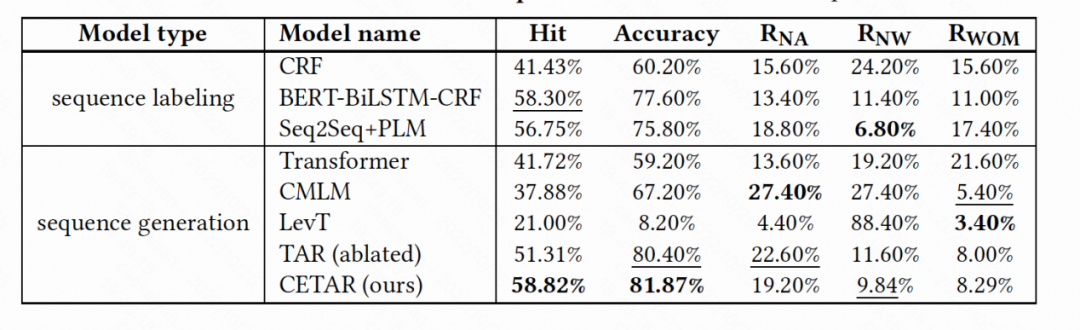
▲ 表3: 數(shù)據(jù)集一各模型表現(xiàn)

▲ 表4: 數(shù)據(jù)集二和數(shù)據(jù)集三各模型表現(xiàn)
從表 3 和表 4,我們得到以下結(jié)論:
1. 在命中率和準確性方面,我們的 CETAR 在通用領(lǐng)域數(shù)據(jù)集( 和 )和特定領(lǐng)域數(shù)據(jù)集()上都優(yōu)于所有基線。
2. 所有模型的 NW 分數(shù)幾乎都高于其 WOM 分數(shù),說明不正確的分詞是導(dǎo)致錯誤預(yù)測的主要原因。因此,單詞邊界的信息對于準確的縮略詞預(yù)測非常重要。
3. 我們還發(fā)現(xiàn),大多數(shù)模型在 上的準確度得分都優(yōu)于 和 。這是因為旅游 POI 的縮寫通常由完整形式的連續(xù)標記組成,例如“杭州西湖風(fēng)景區(qū)-西湖”,而一般領(lǐng)域的實體縮略詞通常由不連續(xù)的標記組成。前者更容易讓模型實現(xiàn)準確的預(yù)測。

▲ 表5: CETAR 針對數(shù)據(jù)集二中輸入實體不同長度的文本(摘要)預(yù)測結(jié)果
3.1 消融實驗
事實上,輸入過多的文本可能會產(chǎn)生過多的噪音,也會消耗更多的計算資源。為了尋求輸入文本的最佳長度,我們比較了 CETAR 在 D2 上輸入百度百科實體摘要的前 1~4 個句子時的性能。
表 5 表明,輸入摘要的第一句表現(xiàn)最好。通過對從數(shù)據(jù)集中隨機抽取的 300 個樣本的調(diào)查,我們發(fā)現(xiàn)大約 75.33% 的第一句話提到了源實體的類型。這也證明了實體類型是促使 CETAR 生成正確縮略詞序列的關(guān)鍵信息。

▲ 表6: CETAR 針對數(shù)據(jù)集三中輸入實體不同長度的文本(評論)預(yù)測結(jié)果

▲ 表7: CETAR 針對數(shù)據(jù)集三中輸入實體不同長度的文本(query)預(yù)測結(jié)果
同樣,作為數(shù)據(jù)集三(表 6 & 表 7),CETAR 在將語義最相關(guān)(第一個)的評論或查詢集作為相關(guān)文本時取得了最佳性能。通過深入調(diào)查,我們發(fā)現(xiàn)熱門評論(查詢)更有可能包含目標實體的縮略詞,幫助 CETAR 實現(xiàn)更準確的預(yù)測。
3.2 應(yīng)用
為了驗證縮略詞在搜索系統(tǒng)中提高召回率和準確捕捉用戶搜索意圖的有效性,我們將 CETAR 預(yù)測的 56,190 個 POI 實體的縮略詞部署到飛豬的搜索系統(tǒng)中。然后,我們進行了持續(xù) 4 天的大規(guī)模 A/B 測試,發(fā)現(xiàn)處理桶與對照桶相比,獲得了 2.03% 的 CVR 提升。那為什么有意義呢?例如,基于精確關(guān)鍵字匹配的搜索系統(tǒng)不會為查詢“迪士尼樂園”返回酒店“上海迪士尼樂園酒店”,因為酒店的名稱與查詢不完全匹配。但是,如果預(yù)先將“迪士尼”識別為“迪士尼度假區(qū)”的縮略詞,則可以更輕松地將酒店與查詢相關(guān)聯(lián)。
總結(jié)
在本文中,我們提出了用于中文縮略詞預(yù)測的 CETAR,它利用了與源實體相關(guān)的信息上下文。CETAR 通過迭代解碼過程生成準確的縮略詞序列,其中縮略分類器和恢復(fù)分類器交替工作。我們的實驗證明了 CETAR 優(yōu)于 SOTA 方法的中文縮略詞預(yù)測。此外,我們在景點領(lǐng)域成功構(gòu)建了一個中文縮略詞數(shù)據(jù)集,并已部署在現(xiàn)實世界的飛豬搜索系統(tǒng)上。系統(tǒng)的在線A/B測試實現(xiàn)了CVR的顯著提升,驗證了縮略詞在促進業(yè)務(wù)方面的價值。
審核編輯:郭婷
-
nlp
+關(guān)注
關(guān)注
1文章
491瀏覽量
23280
原文標題:CIKM2022 | 基于文本增強和縮略-恢復(fù)策略的縮略詞Transformer
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
JSON:簡潔代碼高效搞定序列化與反序列化

什么是“TKU”(在 Dubhe-80 中)?
從數(shù)據(jù)到模型:如何預(yù)測細節(jié)距鍵合的剪切力?
大模型支撐后勤保障方案生成系統(tǒng):功能特點與平臺架構(gòu)解析
大模型賦能物資需求精準預(yù)測與采購系統(tǒng):功能特點與平臺架構(gòu)解析
世界模型是讓自動駕駛汽車理解世界還是預(yù)測未來?

一文讀懂LSTM與RNN:從原理到實戰(zhàn),掌握序列建模核心技術(shù)

ATA-D60090功率放大器在時間調(diào)制序列生成中的應(yīng)用

在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗
基于全局預(yù)測歷史的gshare分支預(yù)測器的實現(xiàn)細節(jié)
如何讓大模型生成你想要的測試用例?

小白學(xué)大模型:大模型加速的秘密 FlashAttention 1/2/3
大模型推理顯存和計算量估計方法研究
?Diffusion生成式動作引擎技術(shù)解析
使用OpenVINO GenAI和LoRA適配器進行圖像生成



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論