 KeenOpt調優算法框架實現對調優對象和配套工具的快速適配
KeenOpt調優算法框架實現對調優對象和配套工具的快速適配

KeenTune(輕豚)是一款 AI 算法與專家知識庫雙輪驅動的操作系統全棧式智能優化產品,為主流的操作系統提供輕量化、跨平臺的一鍵式性能調優,讓應用在智能定制的運行環境發揮最優性能。自 2021年 9 月正式成立 SIG 并宣布開源以來,受到了廣大開發者的關注。KeenTune 的整體開源框架聚焦于通用和靈活的設計原則,其中對于調優場景的擴展,通過分布式架構以及標準化的場景配置模式,可以方便的實現對于 Linux 內核參數,應用配置參數,編譯器優化參數,benchmark 配置參數等調優對象和配套工具的快速適配。
今天, KeenTune 再次帶來開源重磅特性——新增通用的調優算法框架:keenopt。有了 keenopt 的加持,KeenTune 不再僅僅是支持靈活擴展調優場景的調優工具,還成長為了具備靈活擴展調優算法的調優平臺,不僅可以作為性能調優工程師的法寶,也可以成為算法工程師的利器。Keenopt 調優算法框架的開源設計,同樣旨在方便快捷的擴展學術界和工業界新提出的調優算法,以及結合實際需要定制化的調優算法。 聰明的童鞋一定會自然問出一個問題:為什么不能只調用當前流行的調優算法庫,而要打造一個算法框架呢?這就要從我們調優過程中趟過的一個一個坑說起了...
坑洼調優路
一提起調優,首先進入讀者腦海的就是近年來愈發流行的針對機器學習模型,尤其是神經網絡超參數的調優算法。這些調優算法從貝葉斯優化和遺傳算法出發,凝聚了豐富多彩的調優思路,已經成為提升機器學習算法研發效率的利器。那么這些大多圍繞著機器學習模型超參數優化的算法,是不是可以直接應用于比如系統軟件配置和參數調優上來呢?答案是經典的 yes and no。 首先,經典的貝葉斯優化算法(基于高斯代理模型)及其衍生算法(如 TPE),當然是可以直接應用于系統參數調優的。但概括來說,這類算法整體的調優效率卻經常無法滿足無論是機器學習模型超參數調優還是系統參數調優。相應的,近年來的學術創新主要圍繞著進一步提升調優的整體效率展開。也就是在這個層面上,機器學習模型超參數的調優和系統參數調優,走上了不同的道路。
對于機器學習模型超參數調優來說,調優的時間開銷主要來自兩個方面: (1)調優算法搜索策略所需要的運算耗時。 (2)機器學習模型訓練的耗時。 對于近年來逐漸廣為人知的基于高保真原理的優化算法,如 Successive Halving[1],HyperBand[2] 等,主要聚焦于減少第二個方面的時間開銷,畢竟和訓練動輒千萬上億級參數的模型,調優算法搜索策略的開銷簡直不值一提。幸運的事,機器學習模型訓練的耗時確實是靈活可調整的。 然而,對于系統參數調優來說,雖然調優的時間開銷也主要來自兩個方面: (1)調優算法搜索策略所需要的運算耗時。 (2)評估調優推薦參數配置的耗時。 但是其中(2)的耗時由于往往來自調用標準 benchmark 工具獲得,是固定不可調整的。具體例子可以設想一下運行 Fio、SPEC CPU 2017 這類 benchmark 工具的過程。因此,針對系統參數調優的算法領域,無法通過優化(2)的開銷曲線救國,只能老老實實的提升調優算法的搜索策略。到此,我們來到了第二個坑。
參數調優可謂是“維度災難”的一個重災區。基于貝葉斯優化框架的調優算法,本質上是在一個漆黑的空間中摸索,而隨著維度的增加,這個漆黑的環境的 volume 急劇增大,摸索的時間成本的增加是不可避免的。對于機器學習模型超參數的調優來說,這個維度往往在十幾到二十幾這個量級,維度的鐵拳仍然比較溫柔。而對于系統參數調優來說,這個維度往往在幾十到上百甚至過千的量級。在這個量級維度的鐵拳下,經典的貝葉斯調優算法及其衍生算法,往往就會被錘成齏粉。以基于高斯代理模型的貝葉斯優化算法來說,我們可以比較粗糙的概括這種算法為“散點”法,這并不是說這類算法就是亂槍打鳥,畢竟有強大的貝葉斯原理作為引領,搜索的策略和路徑還是有跡可循的。 然而,當維度足夠高的時候,已經有相關研究證明,貝葉斯優化算法和隨機搜索算法基本上是一對臥龍鳳雛的存在[3]。因此,近年來 AI 領域頂會的學術成果,已經開始關注高維空間中的貝葉斯優化問題,由這種“散點”法,逐漸過渡到“局域”法[4,5]。這里“局域”又是我們的一個比較概括的說法,主要原理是在高維空間中,搜索主要被限制在于較小的局部區域進行,而各個局部區域本身的取舍依然服從貝葉斯原理。這類“局域”法有效的限制了搜索區域的 volume,因此往往有更高效的收斂和更好的調優效果。尤其是更好的收斂效果這種特性,對于系統參數的調優實踐來說,可謂一定程度上減輕了燃眉之急,因為實際的系統參數調優實踐,往往要考慮系統資源開銷和整體時間限制,從而需要在盡可能少的調優輪次中給出最優或略低于最優的調優結果。當我們欣喜的準備吸取這些算法進入 KeenTune 去磨刀霍霍的時候,我們來到了第三個坑。 如前所述,當前主流的調優算法庫或工具,往往圍繞著機器學習模型超參數調優的場景進行擴展。因此如 Scikit-Optimize (skopt)[6] 和 NNI[7] 這類算法庫,更多的聚焦于支持 Successive Halving 和 HyperBand 這些針對模型訓練開銷優化的算法,而對于解決高維貝葉斯優化問題的算法不夠及時。此外,即使想在這些算法庫中定制化實現這些算法,也依然需要詳細的研讀這些庫中算法的實現,照貓畫虎的在復雜的代碼邏輯中前進,這種苦楚只能說懂得都懂。因此,當我們拔劍四顧的時候,刀鞘卻阻礙了我們披巾斬棘的身影。至此,讀者已經和我們來到了同樣的境地,也看到那臨門一腳的必選項 --打造更靈活通用的調優算法框架。
KeenOpt 的初心
當我們談論參數調優算法框架的時候,我們談論的是 :
(1)算法集成和定制化的方便快捷。
(2)算法的標準化和模塊化。 圍繞著這兩個設計初心,我們的算法框架盡可能的將各個主要功能模塊獨立的抽象成類。
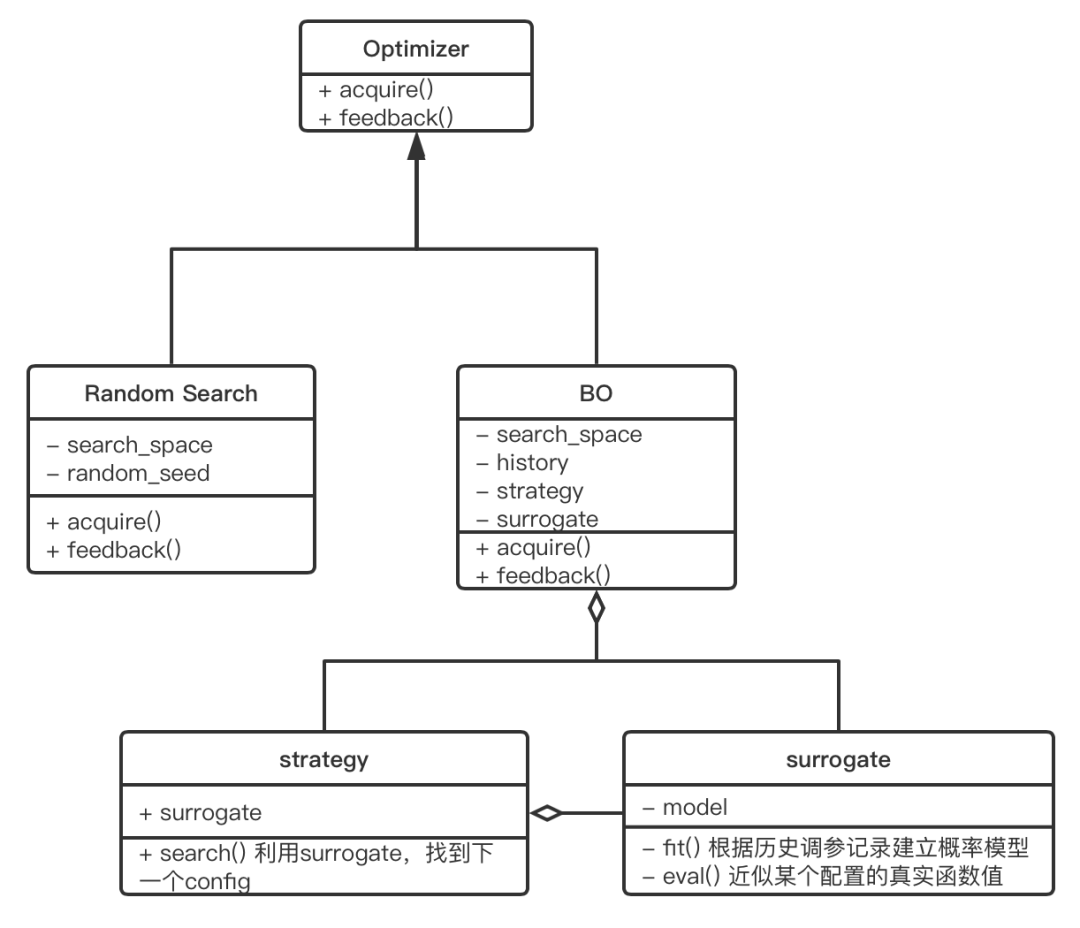
(圖3/ KeenOpt框架概圖) 如圖 3 所示,自頂向下的從優化總體控制類,衍生出如隨機和網格搜索的經典優化算法類,和基于貝葉斯優化的優化算法類。其中優化總體控制類,只要求提供 acquire() 和 feedback() 函數,分別負責選取參數和獲得 benchmark 執行的反饋結果。其中針對貝葉斯優化的算法類,又進一步抽象出:
調優控制類:提供貝葉斯優化必須依賴的接口參數。在最基礎的優化類中,一定程度上實現了對于貝葉斯優化算法接口的標準化,包括參數空間,歷史數據記錄,代理模型,和搜索策略。
參數空間類:參數空間可以靈活定義整型,浮點型,類別型的參數和其取值范圍。由于實際的調優場景中,無可能出現真正意義上的連續參數空間,因此每個參數相應的還搭配了可定義的步長。
代理模型類:代理模型的選擇可以根據具體需要,靈活的選擇經典回歸類機器學習模型和基于 pytorch 實現的神經網絡類模型。
搜索策略類:具體的搜索策略可以實現經典的貝葉斯優化算法,也可以實現如上所述的“局域”搜索策略,整個類只要求實現具體的 search()方法。
下圖 4 中展示了當前 KeenOpt 的支持的部分算法(TPE, LA-MCTS-Bo和LA-MCTS-TuRBO) 在 4 中常見的 synthetic 函數在低維(20)和高維(100)情況下的對比結果,可見“局域”算法確實比經典貝葉斯優化算法有更好的優化結果和更高的收斂效率。
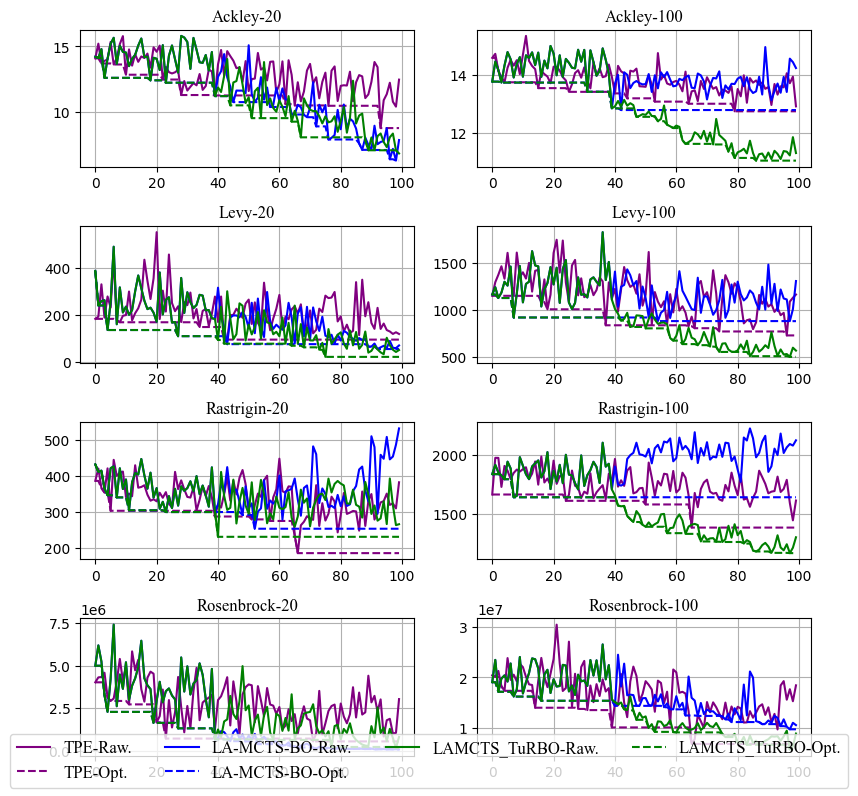
(圖4/ KeenOpt支持算法效果對比)
審核編輯:郭婷
-
操作系統
+關注
關注
37文章
7401瀏覽量
129284 -
AI
+關注
關注
91文章
39755瀏覽量
301365
原文標題:KeenTune的算法之心——KeenOpt 調優算法框架 | 龍蜥技術
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Linux系統內核參數調優實戰指南
實戰RK3568性能調優:如何利用迅為資料壓榨NPU潛能-在Android系統中使用NPU

PYQT 應用程序框架及開發工具
天翼云基于開源歐拉的智能調優實踐
HarmonyOSAI編程智慧調優
Linux服務器性能調優的核心技巧和實戰經驗
HarmonyOS AI輔助編程工具(CodeGenie)智慧調優
Linux網絡性能調優方案
Linux內核參數調優方案
MySQL配置調優技巧
Nginx在企業環境中的調優策略
手把手教你如何調優Linux網絡參數
英飛凌攜手優優綠能,助力電能轉換效率新突破




 工商網監
工商網監
評論