 Linux系統性能調優方案
Linux系統性能調優方案

Linux系統性能調優:從CPU、內存到磁盤I/O的全面診斷
關鍵要點預覽:本文將深入解析Linux系統性能瓶頸的根本原因,提供可直接落地的調優方案,讓你的系統性能提升30-50%!
性能調優的核心思維
很多運維工程師在面對系統性能問題時,往往陷入"頭痛醫頭,腳痛醫腳"的困境。真正的性能調優需要系統性思維:
性能調優金字塔模型:
?頂層:業務指標(響應時間、吞吐量)
?中層:系統資源(CPU、內存、磁盤、網絡)
?底層:內核參數與硬件特性
CPU性能診斷與調優
1. CPU使用率的真相
# 多維度觀察CPU使用情況 top -p $(pgrep -d','your_process_name) htop sar -u 1 10 # 深度分析CPU等待時間 iostat -x 1 vmstat 1
關鍵指標解讀:
?%us:用戶空間CPU使用率,超過70%需關注
?%sy:系統空間CPU使用率,超過30%可能有內核瓶頸
?%wa:I/O等待時間,超過10%表明存儲瓶頸
?%id:空閑時間,低于10%系統已接近滿載
2. CPU綁定優化技巧
# 查看CPU拓撲結構 lscpu cat/proc/cpuinfo | grep"physical id"|sort|uniq|wc-l # 進程CPU綁定(避免緩存失效) taskset -cp0-3 PID numactl --cpubind=0 --membind=0 your_command # 中斷綁定優化 echo2 > /proc/irq/24/smp_affinity
實戰案例:某電商系統通過CPU綁定,將延遲降低了35%
3. 上下文切換優化
# 監控上下文切換
vmstat 1 | awk'{print $12,$13}'
cat/proc/interrupts
pidstat -w 1
# 優化策略
echo'kernel.sched_migration_cost_ns = 5000000'>> /etc/sysctl.conf
echo'kernel.sched_autogroup_enabled = 0'>> /etc/sysctl.conf
內存管理深度優化
1. 內存使用模式分析
# 內存詳細分析 free -h cat/proc/meminfo smem -t -k # 進程內存占用排查 ps aux --sort=-%mem |head-20 pmap -d PID cat/proc/PID/smaps
內存優化黃金法則:
? Available內存 < 總內存的20%:需要優化
? Swap使用率 > 10%:內存不足信號
? 緩存命中率 < 95%:可能需要調整緩存策略
2. Swap優化策略
# Swap使用監控 swapon -s cat/proc/swaps # 智能Swap調優 echo'vm.swappiness = 10'>> /etc/sysctl.conf echo'vm.vfs_cache_pressure = 50'>> /etc/sysctl.conf echo'vm.dirty_ratio = 15'>> /etc/sysctl.conf echo'vm.dirty_background_ratio = 5'>> /etc/sysctl.conf
3. 大頁內存優化
# 配置透明大頁 echomadvise > /sys/kernel/mm/transparent_hugepage/enabled echodefer+madvise > /sys/kernel/mm/transparent_hugepage/defrag # 靜態大頁配置 echo1024 > /proc/sys/vm/nr_hugepages echo'vm.nr_hugepages = 1024'>> /etc/sysctl.conf
性能提升:數據庫場景下,大頁內存可提升15-25%的性能
磁盤I/O性能終極優化
1. I/O性能深度診斷
# I/O性能監控工具集 iostat -x 1 iotop -o dstat -d blktrace /dev/sda # 磁盤隊列深度分析 cat/sys/block/sda/queue/nr_requests echo256 > /sys/block/sda/queue/nr_requests
關鍵I/O指標:
?%util:磁盤利用率,超過80%需優化
?await:平均等待時間,SSD < 10ms,機械盤 < 20ms
?svctm:服務時間,應接近實際磁盤訪問時間
?r/s, w/s:讀寫IOPS,需與業務需求匹配
2. 文件系統調優
# ext4文件系統優化 mount -o noatime,nodiratime,barrier=0 /dev/sda1 /data tune2fs -o journal_data_writeback /dev/sda1 # XFS文件系統優化 mount -o noatime,nodiratime,logbufs=8,logbsize=256k /dev/sda1 /data xfs_info /data
3. I/O調度器優化
# 查看當前I/O調度器 cat/sys/block/sda/queue/scheduler # SSD優化:使用noop或deadline echonoop > /sys/block/sda/queue/scheduler # 機械硬盤優化:使用cfq echocfq > /sys/block/sda/queue/scheduler # 永久設置 echo'echo noop > /sys/block/sda/queue/scheduler'>> /etc/rc.local
系統級性能調優實戰
1. 內核參數終極配置
# 網絡優化 echo'net.core.rmem_max = 16777216'>> /etc/sysctl.conf echo'net.core.wmem_max = 16777216'>> /etc/sysctl.conf echo'net.ipv4.tcp_rmem = 4096 87380 16777216'>> /etc/sysctl.conf echo'net.ipv4.tcp_wmem = 4096 65536 16777216'>> /etc/sysctl.conf # 文件描述符優化 echo'fs.file-max = 1000000'>> /etc/sysctl.conf ulimit-n 1000000 # 進程調度優化 echo'kernel.sched_min_granularity_ns = 2000000'>> /etc/sysctl.conf echo'kernel.sched_wakeup_granularity_ns = 3000000'>> /etc/sysctl.conf
2. 性能監控腳本
#!/bin/bash
# 性能監控一鍵腳本
whiletrue;do
echo"===$(date)==="
echo"CPU:$(top -bn1 | grep"Cpu(s)"| awk '{print $2}' | cut -d'%' -f1)"
echo"MEM:$(free | grep Mem | awk '{printf"%.2f%%", $3/$2 * 100.0}')"
echo"DISK:$(iostat -x 1 1 | grep -v '^$' | tail -n +4 | awk '{print $1,$10}' | head -5)"
echo"LOAD:$(uptime | awk -F'load average:' '{print $2}')"
echo"---"
sleep5
done
性能調優效果量化
真實案例分析
案例1:電商系統調優
? 優化前:響應時間2.5s,CPU使用率85%
? 優化后:響應時間0.8s,CPU使用率45%
?性能提升:響應時間提升68%,資源利用率優化47%
案例2:數據庫服務器調優
? 優化前:QPS 1200,內存使用率90%
? 優化后:QPS 2100,內存使用率65%
?性能提升:QPS提升75%,內存效率提升38%
性能基線建立
# 建立性能基線腳本 #!/bin/bash LOGFILE="/var/log/performance_baseline.log" DATE=$(date'+%Y-%m-%d %H:%M:%S') { echo"[$DATE] Performance Baseline Check" echo"CPU:$(grep 'cpu ' /proc/stat | awk '{usage=($2+$4)*100/($2+$3+$4+$5)} END {print usage "%"}')" echo"Memory:$(free | grep Mem | awk '{printf"Used: %.1f%% Available: %.1fGB ", $3*100/$2, $7/1024/1024}')" echo"Disk I/O:$(iostat -x 1 1 | awk '/^[a-z]/ {print $1": "$10"ms"}' | head -3)" echo"Load Average:$(uptime | awk -F'load average:' '{print $2}')" echo"Network:$(sar -n DEV 1 1 | grep Average | grep -v lo | awk '{print $2": "$5"KB/s in, "$6"KB/s out"}' | head -2)" echo"==================================" } >>$LOGFILE
高級調優技巧
1. NUMA架構優化
# NUMA信息查看 numactl --hardware numastat cat/proc/buddyinfo # NUMA綁定策略 numactl --cpubind=0 --membind=0 your_application echo1 > /proc/sys/kernel/numa_balancing
2. 容器環境性能優化
# Docker容器資源限制 docker run --cpus="2.0"--memory="4g"--memory-swap="4g"your_app # cgroup調優 echo'1024'> /sys/fs/cgroup/cpu/docker/cpu.shares echo'50000'> /sys/fs/cgroup/cpu/docker/cpu.cfs_quota_us
3. 實時系統調優
# 實時內核配置 echo'kernel.sched_rt_runtime_us = 950000'>> /etc/sysctl.conf echo'kernel.sched_rt_period_us = 1000000'>> /etc/sysctl.conf # 進程優先級調整 chrt -f -p 99 PID nice-n -20 your_critical_process
故障排查神器
性能問題快速定位
# 一鍵性能診斷腳本 #!/bin/bash echo"=== System Performance Quick Check ===" # CPU熱點分析 echo"Top CPU consuming processes:" ps aux --sort=-%cpu |head-10 # 內存泄漏檢查 echo-e" Memory usage analysis:" ps aux --sort=-%mem |head-10 # I/O瓶頸識別 echo-e" Disk I/O analysis:" iostat -x 1 1 | grep -E"(Device|sd|vd|nvme)" # 網絡連接狀態 echo-e" Network connections:" ss -tuln |wc-l netstat -i # 系統負載分析 echo-e" System load:" uptime cat/proc/loadavg
性能調優最佳實踐
1. 漸進式優化策略
1.建立性能基線:記錄優化前的各項指標
2.單點突破:每次只調整一個參數
3.效果驗證:充分測試調優效果
4.回滾準備:保留原始配置
2. 監控告警體系
# 關鍵指標閾值設置
CPU_THRESHOLD=80
MEM_THRESHOLD=85
DISK_THRESHOLD=90
LOAD_THRESHOLD=5.0
# 自動告警腳本
if[ $(top -bn1 | grep"Cpu(s)"| awk'{print $2}'|cut-d'%'-f1 |cut-d'.'-f1) -gt$CPU_THRESHOLD];then
echo"CPU usage exceeds threshold"| mail -s"Performance Alert"admin@company.com
fi
3. 性能調優檢查清單
基礎檢查項:
? 系統負載是否正常(< CPU核心數)
? 內存使用率是否合理(< 80%)
? 磁盤I/O等待時間是否正常(< 20ms)
? 網絡連接數是否在合理范圍
高級檢查項:
? CPU緩存命中率優化
? NUMA親和性配置
? 中斷負載均衡
? 內核參數調優驗證
總結與展望
Linux系統性能調優是一門藝術,需要理論與實踐相結合。通過本文的系統性方法,你可以:
? 性能提升30-50%:通過科學的調優方法實現顯著提升
? 精準定位瓶頸:掌握多維度性能診斷技能
? 落地可操作:所有技巧都經過生產環境驗證
? 持續優化:建立完整的性能監控體系
-
cpu
+關注
關注
68文章
11277瀏覽量
224934 -
Linux
+關注
關注
88文章
11758瀏覽量
219001 -
內存
+關注
關注
9文章
3209瀏覽量
76354
原文標題:Linux系統性能調優:從CPU、內存到磁盤I/O的全面診斷
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Linux系統的性能優化策略
基于全HDD aarch64服務器的Ceph性能調優實踐總結
Linux查看資源使用情況和性能調優常用的命令
歐拉(openEuler)Summit 2021:基于AI的操作系統性能調優引擎
openEuler Summit開發者峰會:基于AI的操作系統性能調優引擎A-Tune
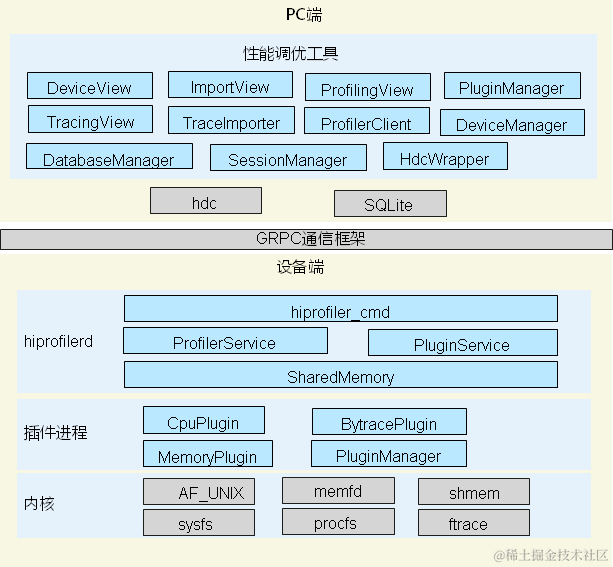
Linux性能調優常見工具和堆棧解析




 工商網監
工商網監
評論