 FPGA執行計算密集型任務性能表現及優勢有哪些
FPGA執行計算密集型任務性能表現及優勢有哪些

FPGA可用于處理多元計算密集型任務,依托流水線并行結構體系,FPGA相對GPU、CPU在計算結果返回時延方面具備技術優勢。
計算密集型任務:矩陣運算、機器視覺、圖像處理、搜索引擎排序、非對稱加密等類型的運算屬于計算密集型任務。該類運算任務可由CPU卸載至FPGA執行。
FPGA執行計算密集型任務性能表現:
? 計算性能相對CPU:如Stratix系列FPGA進行整數乘法運算,其性能與20核CPU相當,進行浮點乘法運算,其性能與8核CPU相當。
? 計算性能相對GPU:FPGA進行整數乘法、浮點乘法運算,性能相對GPU存在數量級差距,可通過配置乘法器、浮點運算部件接近GPU計算性能。
FPGA執行計算密集型任務核心優勢:搜索引擎排序、圖像處理等任務對結果返回時限要求較為嚴格,需降低計算步驟時延。傳統GPU加速方案下數據包規模較大,時延可達毫秒級別。FPGA加速方案下,PCIe時延可降至微秒級別。遠期技術推動下,CPU與FPGA數據傳輸時延可降至100納秒以下。
FPGA可針對數據包步驟數量搭建同等數量流水線(流水線并行結構),數據包經多個流水線處理后可即時輸出。GPU數據并行模式依托不同數據單元處理不同數據包,數據單元需一致輸入、輸出。針對流式計算任務,FPGA流水線并行結構在延遲方面具備天然優勢。
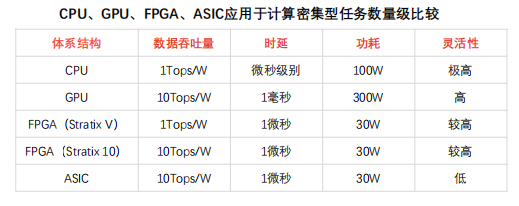
FPGA用于處理通信密集型任務不受網卡限制,在數據包吞吐量、時延方面表現優于CPU方案,時延穩定性較強。
通信密集型任務:對稱加密、防火墻、網絡虛擬化等運算屬于通信密集型計算任務,通信密集數據處理相對計算密集數據處理復雜度較低,易受通信硬件設備限制。
FPGA執行通信密集型任務優勢:
① 吞吐量優勢:CPU方案處理通信密集任務需通過網卡接收數據,易受網卡性能限制(線速處理64字節數據包網卡有限,CPU及主板PCIe網卡插槽數量有限)。GPU方案(高計算性能)處理通信密集任務數據包缺乏網口,需依靠網卡收集數據包,數據吞吐量受CPU及網卡限制,時延較長。FPGA可接入40Gbps、100Gbps網線,并以線速處理各類數據包,可降低網卡、交換機配置成本。
② 時延優勢:CPU方案通過網卡收集數據包,并將計算結果發送至網卡。受網卡性能限制,DPDK數據包處理框架下,CPU處理通信密集任務時延近5微秒,且CPU時延穩定性較弱,高負載情況下時延或超過幾十微秒,造成任務調度不確定性。FPGA無需指令,可保證穩定、極低時延,FPGA協同CPU異構模式可拓展FPGA方案在復雜端設備的應用。
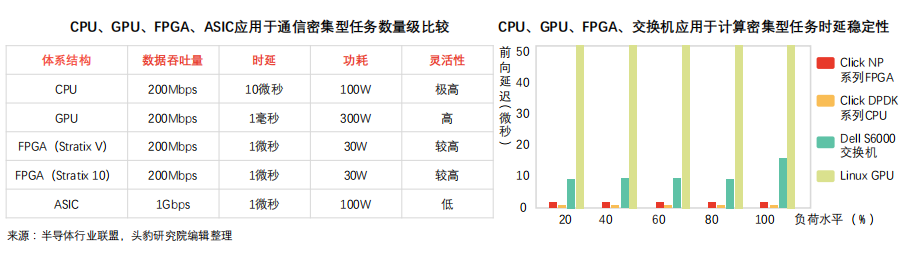
FPGA部署包括集群式、分布式等,逐漸從中心化過渡至分布式,不同部署方式下,服務器溝通效率、故障傳導效應表現各異。
FPGA嵌入功耗負擔:FPGA嵌入對服務器整體功耗影響較小,以Catapult聯手微軟開展的FPGA加速機器翻譯項目為例,加速模塊整體總計算能力達到103Tops/W,與10萬塊GPU計算能力相當。相對而言,嵌入單塊FPGA導致服務器整體功耗增加約30W。
FPGA部署方式特點及限制:
① 集群部署特點及限制:FPGA芯片構成專用集群,形成FPGA加速卡構成的超級計算器(如Virtex系列早期實驗板于同一硅片部署6塊FPGA,單位服務器搭載4塊實驗板)。
? 專用集群模式無法在不同機器FPGA之間實現通信;
? 數據中心其他機器需集中發送任務至FPGA集群,易造成網絡延遲;
? 單點故障導致數據中心整體加速能力受限
② 網線連接分布部署:為保證數據中心服務器同構性(ASIC解決方案亦無法滿足),該部署方案于不同服務器嵌入FPGA,并通過專用網絡連接,可解決單點故障傳導、網絡延遲等問題。
?類同于集群部署模式,該模式不支持不同機器FPGA間通信;
?搭載FPGA芯片的服務器具備高度定制化特點,運維成本較高
③ 共享服務器網絡部署:該部署模式下,FPGA置于網卡、交換機間,可大幅提高加速網絡功能并實現存儲虛擬化。FPGA針對每臺虛擬機設置虛擬網卡,虛擬交換機數據平面功能移動至FPGA內,無需CPU或物理網卡參與網絡數據包收發過程。該方案顯著提升虛擬機網絡性能(25Gbps),同時可降低數據傳輸網絡延遲(10倍)。
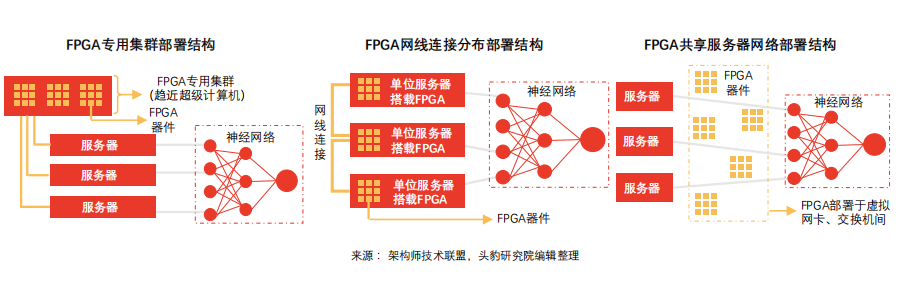
分享服務器網絡部署模式下,FPGA加速器有助于降低數據傳輸時延,維護數據中心時延穩定,顯著提升虛擬機網絡性能。
分享服務器網絡部署模式下FPGA加速Bing搜索排序:Bing搜索排序于該模式下采用10Gbps專用網線通信,每組網絡由8個FPGA組成。其中,部分負責提取信號特征,部分負責計算特征表達式,部分負責計算文檔得分,最終形成機器人即服務(RaaS)平臺。FPGA加速方案下,Bing搜索時延大幅降低,延遲穩定性呈現正態分布。該部署模式下,遠程FPGA通信延遲相對搜索延遲可忽略。
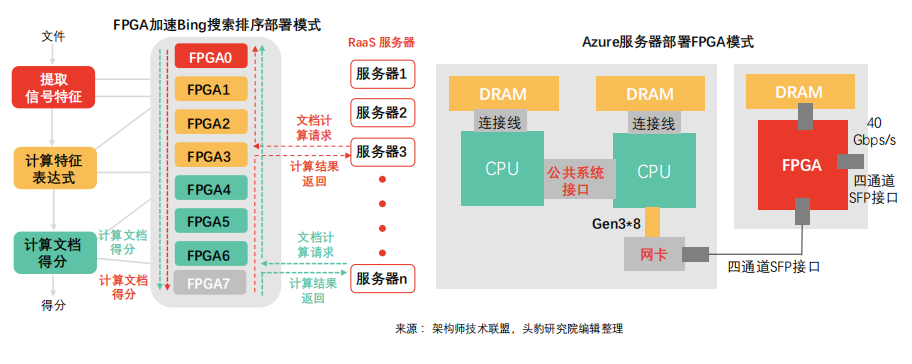
Azure服務器部署FPGA模式:Azure針對網絡及存儲虛擬化成本較高等問題采取FPGA分享服務器網絡部署模式。隨網絡計算速度達到40Gbps,網絡及存儲虛擬化CPU成本激增(單位CPU核僅可處理100Mbps吞吐量)。通過在網卡及交換機間部署FPGA,網絡連接擴展至整個數據中心。通過輕量級傳輸層,同一服務器機架時延可控制在3微秒內,觸達同數據中心全部FPGA機架時延可控制在20微秒內。
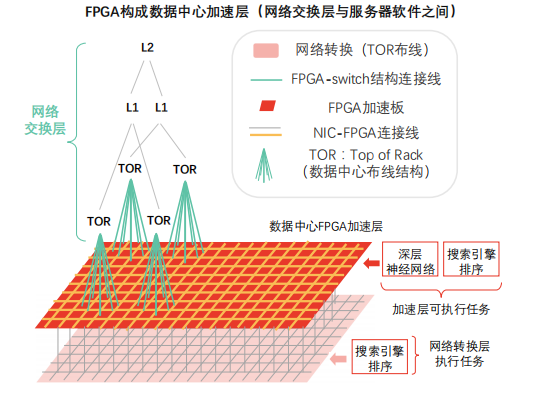
依托高帶寬、低時延優勢,FPGA可組成網絡交換層與服務器軟件之間的數據中心加速層,并隨分布式加速器規模擴大實現性能超線性提升。
數據中心加速層:FPGA嵌入數據中心加速平面,位于網絡交換層(支架層、第一層、第二層)及傳統服務器軟件(CPU層面運行軟件)之間。
加速層優勢:
? FPGA加速層負責為每臺服務器(提供云服務)提供網絡加速、存儲虛擬化加速支撐,加速層剩余資源可用于深度神經網絡(DNN)等計算任務。
? 隨分布式網絡模式下FPGA加速器規模擴大,虛擬網絡性能提升呈現超線性特征。
加速層性能提升原理:使用單塊FPGA時,單片硅片內存不足以支撐全模型計算任務,需持續訪問DRAM以獲取權重,受制于DRAM性能。加速層通過數量眾多的FPGA支撐虛擬網絡模型單層或單層部分計算任務。該模式下,硅片內存完整加載模型權重,可突破DRAM性能瓶頸,FPGA計算性能得到充分發揮。加速層需避免計算任務過度拆分而導致計算、通信失衡。
嵌入式eFPGA技術在性能、成本、功耗、盈利能力等方面優于傳統FPGA嵌入方案,可針對不同應用場景、不同細分市場需求提供靈活解決方案.
eFPGA技術驅動因素:設計復雜度提升伴隨設備成本下降的經濟趨勢促發市場對eFPGA技術需求。
器件設計復雜度提升:SoC設計實現過程相關軟件工具趨于復雜(如Imagination Technologies為滿足客戶完整開發解決方案需求而提供PowerVR圖形界面、Eclipse整合開發環境),工程耗時增加(編譯時間、綜合時間、映射時間,FPGA規模越大,編譯時間越長)、制模成本提高(FPGA芯片成本為同規格ASIC芯片成本100倍)。
設備單位功能成本持續下降:20世紀末期,FPGA平均售價較高(超1,000元),傳統模式下,FPGA與ASIC集成設計導致ASIC芯片管芯面積、尺寸增大,復雜度提升,早期混合設備成本較高。21世紀,相對批量生產的混合設備,FPGA更多應用于原型設計、預生產設計,成本相對傳統集成持續下降(最低約100元),應用靈活。eFPGA技術優勢:
更優質:eFPGA IP核及其他功能模塊的SoC設計相對傳統FPGA嵌入ASIC解決方案,在功耗、性能、體積、成本等方面表現更優。
更方便:下游應用市場需求更迭速度快,eFPGA可重新編程特性有助于設計工程師更新SoC,產品可更長久占有市場,利潤、收入、盈利能力同時大幅提升。eFPGA方案下SoC可實現高效運行,一方面迅速更新升級以支持新接口標準,另一方面可快速接入新功能以應對細分化市場需求。
更節能:SoC設計嵌入eFPGA技術可在提高總性能的同時降低總功耗。利用eFPGA技術可重新編程特性,工程師可基于硬件,針對特定問題對解決方案進行重新配置,進而提高設計性能、降低功耗。

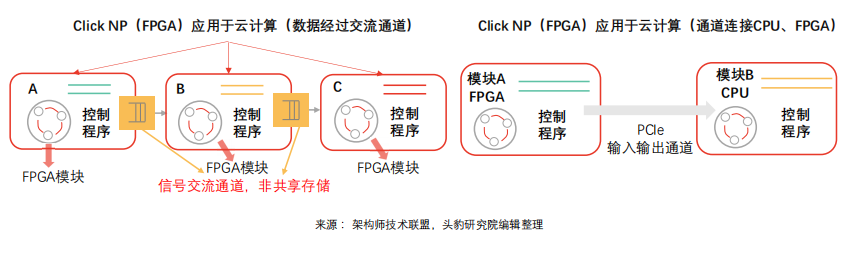
FPGA技術無需依靠指令、無需共享內存,在云計算網絡互連系統中提供低延遲流式通信功能,可廣泛滿足虛擬機之間、進程之間加速需求.
FPGA云計算任務執行流程:主流數據中心以FPGA為計算密集型任務加速卡,賽靈思及阿爾特拉推出基于OpenCL的高層次編程模型,模型依托CPU觸達DRAM,向FPGA傳輸任務,通知執行,FPGA完成計算并將執行結果傳輸至DRAM,最終傳輸至CPU。
FPGA云計算性能升級空間:受限于工程實現能力,當前數據中心FPGA與CPU之間通信多以DRAM為中介,通過燒寫DRAM、啟動kernel、讀取DRAM的流程完成通信(FPGADRAM相對CPU DRAM數據傳輸速度較慢),時延近2毫秒(OpenCL、多個kernel間共享內存)。CPU與FPGA間通信時延存在升級空間,可借助PCIe DMA實現高效直接通信,時延最低可降至1微秒。
FPGA云計算通信調度新型模式:新通信模式下,FPGA與CPU無需依托共享內存結構,可通過管道實現智行單元、主機軟件之間的高速通信。云計算數據中心任務較為單一,重復性強,主要包括虛擬平臺網絡構建和存儲(通信任務)以及機器學習、對稱及非對稱加密解密(計算任務),算法較為復雜。新型調度模式下,CPU計算任務趨于碎片化,遠期云平臺計算中心或以FPGA為主,并通過FPGA將復雜計算任務卸載至CPU(區別于傳統模式下CPU卸載任務至FPGA的模式)。
全球FPGA市場由四大巨頭Xilinx賽靈思,Intel英特爾(收購阿爾特拉)、Lattice萊迪思、Microsemi美高森美壟斷,四大廠商壟斷9,000余項專利技術,把握行業“制空權”。
FPGA芯片行業形成以來,全球范圍約有超70家企業參與競爭,新創企業層出不窮(如Achronix Semiconductor、MathStar等)。產品創新為行業發展提供動能,除傳統可編程邏輯裝置(純數字邏輯性質),新型可編程邏輯裝置(混訊性質、模擬性質)創新速度加快,具體如Cypress Semiconductor 研 發 具 有 可 組 態 性 混 訊 電 路 PSoC(Programmable System on Chip),再如Actel推出Fusion(可程序化混訊芯片)。此外,部分新創企業推出現場可編程模擬數組FPAA(Field Programmable Analog Array)等。
隨智能化市場需求變化演進,高度定制化芯片(SoC ASIC)因非重復投資規模大、研發周期長等特點導致市場風險劇增。相對而言,FPGA在并行計算任務領域具備優勢,在高性能、多通道領域可以代替部分ASIC。人工智能領域多通道計算任務需求推動FPGA技術向主流演進。
基于FPGA芯片在批量較小(流片5萬片為界限)、多通道計算專用設備(雷達、航天設備)領域的優勢,下游部分應用市場以FPGA取代ASIC應用方案。
中國FPGA芯片研發企業可以紫光同創、國微電子、成都華微電子、安路科技、智多晶、高云半導體、上海復旦微電子和京微齊力為例。從產品角度分析,中國FPGA硬件性能指標相較賽靈思、Intel等差距較大。紫光同創是當前中國市場唯一具備自主產權千萬門級高性能FPGA研發制造能力的企業。上海復旦微電子于2018年5月推出自主知識產權億門級FPGA產品。中國FPGA企業緊跟大廠步伐,布局人工智能、自動駕駛等市場,打造高、中、低端完整產品線。
中國FPGA企業競爭突破口現階段中國FPGA廠商芯片設計軟件、應用軟件不統一,易在客戶端造成資源浪費,頭部廠商可帶頭集中產業鏈資源,提高行業整體競爭力。
審核編輯:郭婷
-
FPGA
+關注
關注
1660文章
22408瀏覽量
636224 -
cpu
+關注
關注
68文章
11277瀏覽量
224946 -
機器視覺
+關注
關注
165文章
4797瀏覽量
126042
原文標題:收藏:FPGA知識及芯片技術
文章出處:【微信號:FPGA研究院,微信公眾號:FPGA研究院】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Altera全新推出MAX 10 FPGA封裝新選擇

英飛凌推出專為高功率與計算密集型應用而設計的400V和440V MOSFET
【產品介紹】Altair HPCWorks高性能計算管理平臺(HPC平臺)

【上海晶珩睿莓1開發板試用體驗】4、Coremark性能測試
CPU密集型任務開發指導
TaskPool和Worker的對比分析
上海貝嶺推出全新DDR5 SPD芯片BL5118
借助NVIDIA技術實現機器人裝配和接觸密集型操作

RDMA簡介1之RDMA開發必要性
睿擎多核 SMP 開發:極簡開發,超強性能——睿擎派開發板0元試用

Altera Agilex 5 D系列FPGA的性能和能效
告別性能瓶頸:使用 Google Coral TPU 為樹莓派注入強大AI計算力!




 工商網監
工商網監
評論