") Meta開發(fā)AITemplate,大幅簡(jiǎn)化多GPU后端部署
Meta開發(fā)AITemplate,大幅簡(jiǎn)化多GPU后端部署

眾所周知,GPU 在各種視覺、自然語言和多模態(tài)模型推理任務(wù)中都占據(jù)重要位置。然而,對(duì)于高性能 GPU 推理引擎,AI 從業(yè)者幾乎沒有選擇權(quán),必須使用一些平臺(tái)專有的黑盒系統(tǒng)。這意味著如果要切換 GPU 供應(yīng)商,就必須重新實(shí)現(xiàn)一遍部署系統(tǒng)。在生產(chǎn)環(huán)境中當(dāng)涉及復(fù)雜的依賴狀況時(shí),這種靈活性的缺失使維護(hù)迭代成本變得更加高昂。
在 AI 產(chǎn)品落地過程中,經(jīng)常需要模型快速迭代。盡管一些閉源系統(tǒng)(如 TensorRT)提供了一些定制化功能,但這些定制化功能完全不能滿足需求。更進(jìn)一步來說,這些閉源專有的解決方案,會(huì)使 debug 更加困難,對(duì)開發(fā)敏捷性造成影響。
針對(duì)這些業(yè)界難題,Meta AI 開發(fā)了擁有 NVIDIA GPU 和 AMD GPU 后端的統(tǒng)一推理引擎——AITemplate。
AITemplate 在 CNN、Transformer 和 Diffusion 模型上都能提供接近硬件上限的 TensorCore (NVIDIA GPU) 和 MatrixCore (AMD GPU) 性能。使用 AITemplate 后,在 NVIDIA GPU 上對(duì)比 PyTorch Eager 的提速最高能達(dá)到 12 倍,在 AMD GPU 上對(duì)比 PyTorch Eager 的提速達(dá)到 4 倍。
這意味著,當(dāng)應(yīng)用于超大規(guī)模集群時(shí),AITemplate 能夠節(jié)約的成本數(shù)額將是驚人的。
具體而言,AITemplate 是一個(gè)能把 AI 模型轉(zhuǎn)換成高性能 C++ GPU 模板代碼的 Python 框架。該框架在設(shè)計(jì)上專注于性能和簡(jiǎn)化系統(tǒng)。AITemplate 系統(tǒng)一共分為兩層:前段部分進(jìn)行圖優(yōu)化,后端部分針對(duì)目標(biāo) GPU 生成 C++ 模板代碼。AITemplate 不依賴任何額外的庫或 Runtime,如 cuBLAS、cudnn、rocBLAS、MIOpen、TensorRT、MIGraphX 等。任何 AITemplate 編譯的模型都是自洽的。
AITemplate 中提供了大量性能提升創(chuàng)新,包括更先進(jìn)的 GPU Kernel fusion,和一些專門針對(duì) Transformer 的先進(jìn)優(yōu)化。這些優(yōu)化極大提升了 NVIDIA TensorCore 和 AMD MatrixCore 的利用率。
目前,AITemplate 支持 NVIDIA A100 和 MI-200 系列 GPU,兩種 GPU 都被廣泛應(yīng)用在科技公司、研究實(shí)驗(yàn)室和云計(jì)算提供商的數(shù)據(jù)中心。
團(tuán)隊(duì)對(duì) AITemplate 進(jìn)行了一系列測(cè)試。下圖的測(cè)試展示了 AITemplate 和 PyTorch Eager 在 NVIDIA A100 上的主流模型中的加速比。
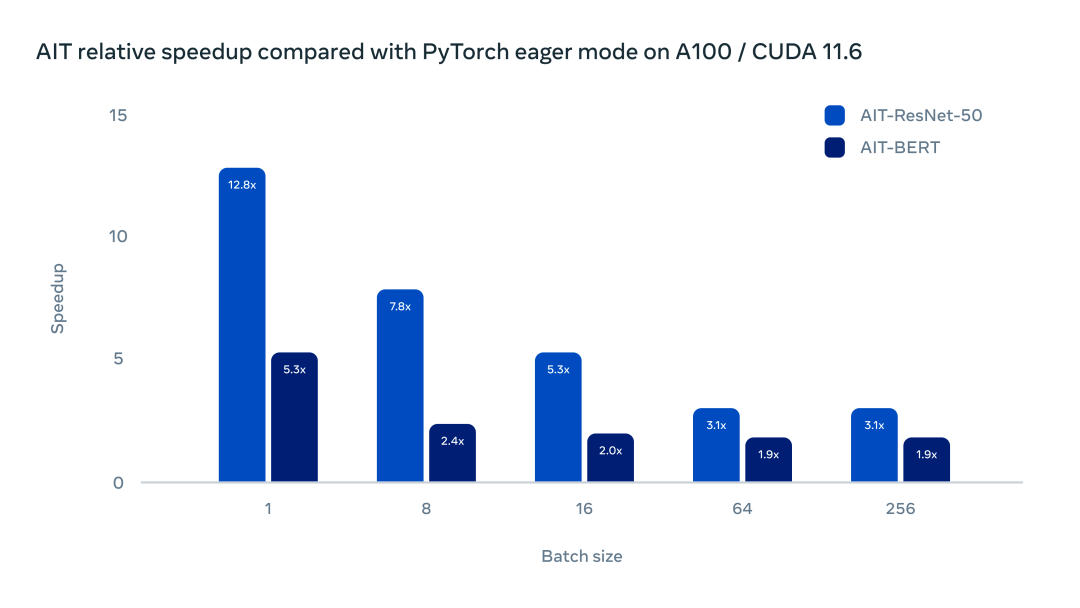
在帶有 Cuda 11.6 的 Nvidia A100 上運(yùn)行 BERT 和 ResNet-50,AITemplate 在 ResNet-50 中提供了 3 到 12 倍的加速,在 BERT 上提供了 2 到 5 倍的加速。
經(jīng)測(cè)試,AITemplate 在 AMD MI250 GPU 上較 PyTorch Eager 也有較大的加速比。
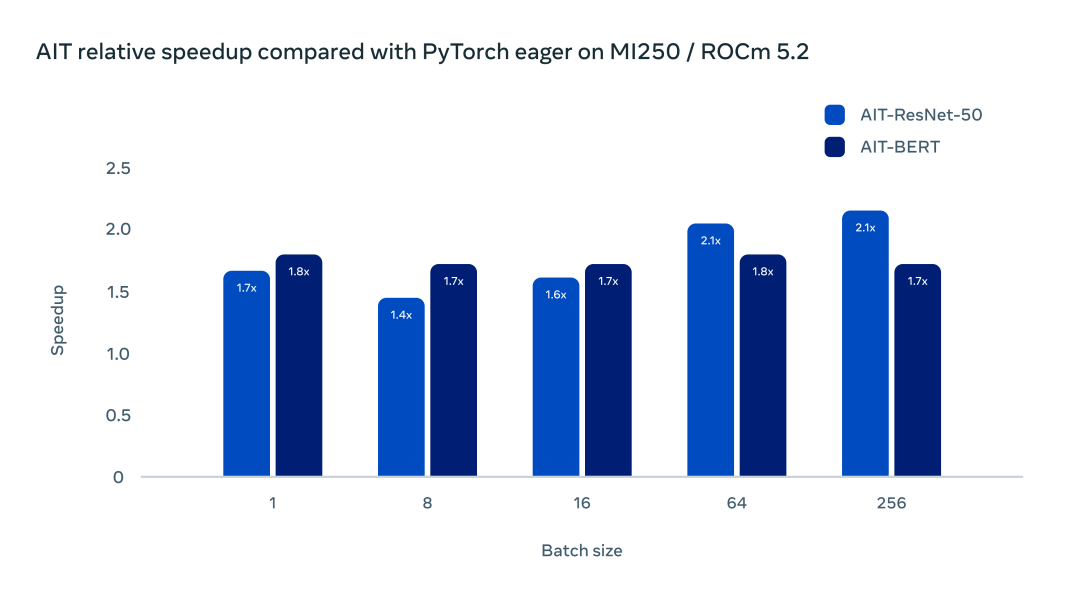
使用 ROCm 5.2 和 MI250 加速器,ResNet-50 和 BERT 的加速在 1.5-2 倍范圍內(nèi)。
AITemplate 的統(tǒng)一 GPU 后端支持,讓深度學(xué)習(xí)開發(fā)者在最小開銷的情況下,擁有了更多的硬件提供商選擇。下圖直觀展示了 AITemplate 在 NVIDIA A100 GPU 和 AMD MI250 GPU 上的加速對(duì)比:
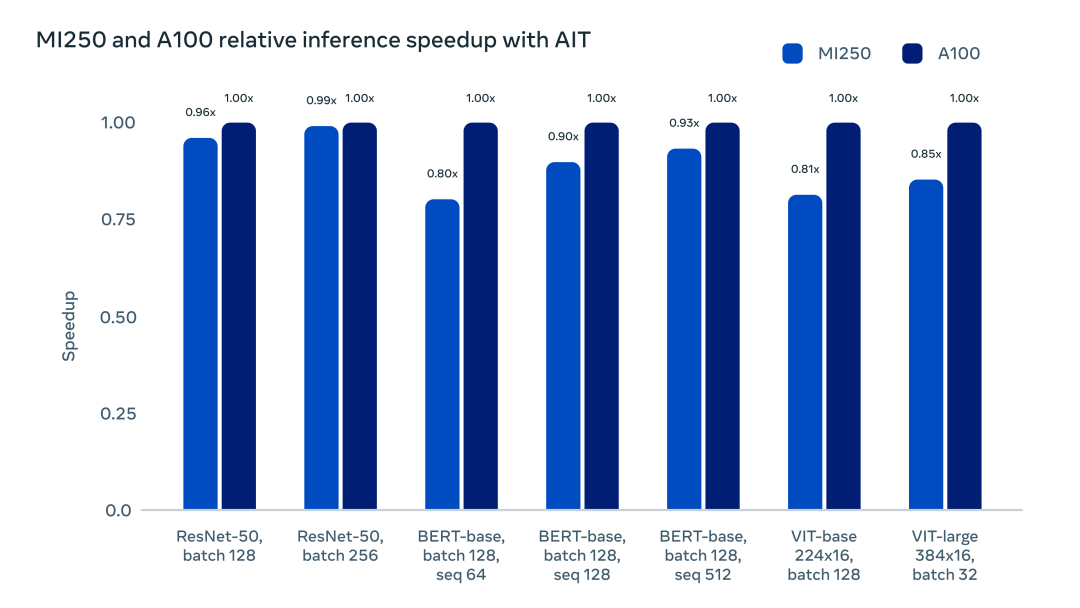
此外,AITemaplte 的部署較其他方案也更為簡(jiǎn)潔。由于 AI 模型被編譯成了自洽的二進(jìn)制文件并且不存在任何第三方庫的依賴,任何被編譯的二進(jìn)制文件都能在相同硬件、CUDA 11/ ROCm 5 或者更新的軟件環(huán)境中運(yùn)行,也不用擔(dān)心任何后向兼容問題。AITemplate 提供了開箱即用的模型樣例,如 Vision Transformer、BERT、Stable Diffusion、ResNet 和 MaskRCNN,使得部署 PyTorch 模型更加簡(jiǎn)單。
AITemplate 的優(yōu)化
AITemplate 提供了目前最先進(jìn)的 GPU Kernel 融合技術(shù):支持縱向、水平和內(nèi)存融合為一體的多維融合技術(shù)。縱向融合將同一條鏈上的操作進(jìn)行融合;水平融合將并行無依賴的操作進(jìn)行融合;內(nèi)存融合把所有內(nèi)存移動(dòng)操作和計(jì)算密集算子進(jìn)行融合。
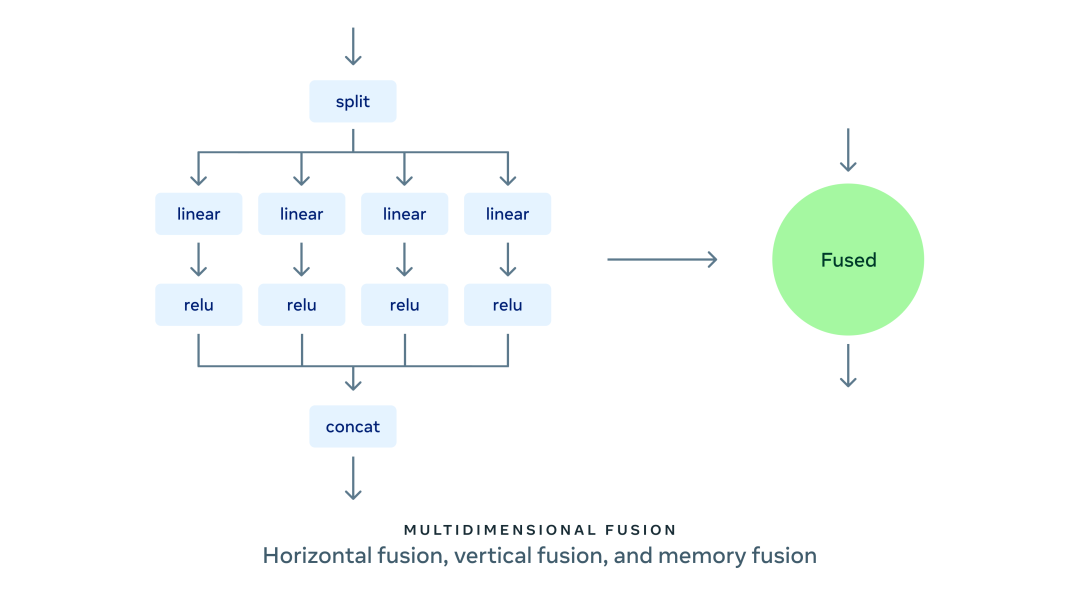
在水平融合中,AITemplate 目前可以把不同輸入形狀的矩陣乘法 (GEMM)、矩陣乘法和激活函數(shù),以及 LayerNorm、LayerNorm 和激活函數(shù)進(jìn)行融合。
在縱向融合中,AITemplate 支持超過傳統(tǒng)標(biāo)準(zhǔn)的 Elementwise 融合,包括:
通過 CUTLASS 和 Composable Kernel 支持了矩陣和 Elementwise 算子融合;
為 Transformer 的 Multi-head Attention 提供了矩陣乘法和內(nèi)存布局轉(zhuǎn)置融合;
通過張量訪問器對(duì)內(nèi)存操作,如 split、slice、concatenate 等進(jìn)行融合來消除內(nèi)存搬運(yùn)。
在標(biāo)準(zhǔn)的 Transformer Multi head attention 模塊,目前 AITemplate 在 CUDA 平臺(tái)使用了 Flash Attention,在 AMD 平臺(tái)上使用了 Composable Kernel 提供的通用背靠背矩陣乘法融合。兩種解決方案都能大幅減小內(nèi)存帶寬需求,在長(zhǎng)序列問題中,提升更為明顯。如下圖所示:
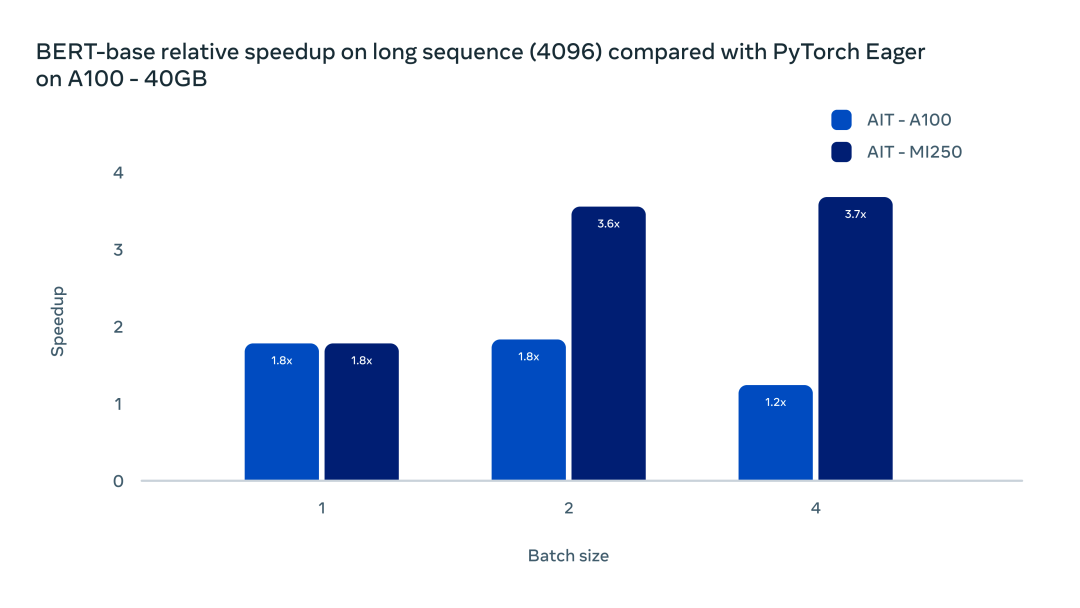
AITemplate 與 Composable Kernel 的廣義背靠背融合顯著提高了長(zhǎng)序列 Transformer 的推理效率。在 batch size 為 1 時(shí),使用 AITemplate 的兩張 GPU 均比原生框架加速了 80%。
開發(fā) AITemplate
AITemplate 有兩層模版系統(tǒng):第一層在 Python 中使用 Jinja2 模板,第二層在 GPU TensorCore/MatrixCore 中使用 C++ 模板(NVIDIA GPU 上使用 CUTLASS,AMD GPU 上使用 Composable Kernel)。AITemplate 在 Python 中找到性能最優(yōu)的 GPU 模板參數(shù),再通過 Jinja2 渲染出最終的 C++ 代碼。
在代碼生成后,就能使用 GPU C++ 編譯器(NVIDIA 平臺(tái)上的 NVCC 和 AMD 平臺(tái)上的 HIPCC)編譯出最終的二進(jìn)制代碼。AITemplate 提供了一套類似于 PyTorch 的前端,方便用戶直接將模型轉(zhuǎn)換到 AITemplate 而不是通過多層 IR 轉(zhuǎn)換。
總體來看,AITemplate 對(duì)當(dāng)前一代及下一代 NVIDIA GPU 和 AMD GPU 提供了 SOTA 性能并大幅簡(jiǎn)化了系統(tǒng)復(fù)雜度。
Meta 表示,這只是創(chuàng)建高性能多平臺(tái)推理引擎旅程的開始:「我們正在積極擴(kuò)展 AITemplate 的完全動(dòng)態(tài)輸入支持。我們也有計(jì)劃推廣 AITemplate 到其他平臺(tái),例如 Apple 的 M 系列 GPU,以及來自其他供應(yīng)商的 CPU 等等。」
此外,AITemplate 團(tuán)隊(duì)也正在開發(fā)自動(dòng) PyTorch 模型轉(zhuǎn)換系統(tǒng),使其成為開箱即用的 PyTorch 部署方案。「AITemplate 對(duì)支持 ONNX 和 Open-XLA 也持開放態(tài)度。我們希望能構(gòu)建一個(gè)更為綠色高效的 AI 推理系統(tǒng),能擁有更高的性能,更強(qiáng)的靈活性和更多的后端選擇。」團(tuán)隊(duì)表示。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
5176瀏覽量
135068 -
AI
+關(guān)注
關(guān)注
91文章
39485瀏覽量
300575
原文標(biāo)題:推理速度數(shù)倍提升,大幅簡(jiǎn)化多GPU后端部署:Meta發(fā)布全新推理引擎AITemplate
文章出處:【微信號(hào):3D視覺工坊,微信公眾號(hào):3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
借助NVIDIA CUDA Tile IR后端推進(jìn)OpenAI Triton的GPU編程
FPGA+GPU異構(gòu)混合部署方案設(shè)計(jì)
八通道智能驅(qū)動(dòng)器SiLM92108,集成驅(qū)動(dòng)與診斷,簡(jiǎn)化多電機(jī)系統(tǒng)設(shè)計(jì)

Hi9204 4.5~65V輸入高可靠性電源解決方案智芯一級(jí)代理聚能芯半導(dǎo)體原廠技術(shù)支持
在Python中借助NVIDIA CUDA Tile簡(jiǎn)化GPU編程

米爾RK3576部署端側(cè)多模態(tài)多輪對(duì)話,6TOPS算力驅(qū)動(dòng)30億參數(shù)LLM
基于米爾瑞芯微RK3576開發(fā)板的Qwen2-VL-3B模型NPU多模態(tài)部署評(píng)測(cè)
【米爾RK3576開發(fā)板免費(fèi)體驗(yàn)】1、開發(fā)環(huán)境、鏡像燒錄、QT開發(fā)環(huán)境搭建以及應(yīng)用部署
Say Hi to ERNIE!Imagination GPU率先完成文心大模型的端側(cè)部署

HarmonyOS5云服務(wù)技術(shù)分享--Serverless抽獎(jiǎng)模板部署
如何在Ollama中使用OpenVINO后端
極速部署!GpuGeek提供AI開發(fā)者的云端GPU最優(yōu)解
添越智創(chuàng)基于 RK3588 開發(fā)板部署測(cè)試 DeepSeek 模型全攻略
如何在Arm Ethos-U85上使用ExecuTorch
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 電子發(fā)燒友
- 關(guān)于我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 張迎輝:mikezhang@elecfans.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察

版權(quán)所有 ? 長(zhǎng)沙勒克斯教育咨詢有限公司
湖南省長(zhǎng)沙市開福區(qū)月湖街道匍園路20號(hào)聚恒科技園1棟2301-1房
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023036445號(hào)-105-1
工商網(wǎng)監(jiān)
湘ICP備2023036445號(hào)-105-1
評(píng)論