") NVIDIA H100 Tensor Core GPU性能比上一代GPU高出4.5 倍
NVIDIA H100 Tensor Core GPU性能比上一代GPU高出4.5 倍

在行業(yè)標(biāo)準(zhǔn) AI 推理測(cè)試中,NVIDIA H100 GPU 創(chuàng)造多項(xiàng)世界紀(jì)錄、A100 GPU 在主流性能方面展現(xiàn)領(lǐng)先優(yōu)勢(shì)、Jetson AGX Orin 在邊緣計(jì)算方面處于領(lǐng)先地位。
在 MLPerf 行業(yè)標(biāo)準(zhǔn) AI 基準(zhǔn)測(cè)試中首次亮相的 NVIDIA H100 Tensor Core GPU 在所有工作負(fù)載推理中均創(chuàng)造了世界紀(jì)錄,其性能比上一代 GPU 高出 4.5 倍。
這些測(cè)試結(jié)果表明,對(duì)于那些需要在高級(jí) AI 模型上獲得最高性能的用戶來(lái)說(shuō),Hopper 是最優(yōu)選擇。
此外,NVIDIA A100 Tensor Core GPU 和用于 AI 機(jī)器人的 NVIDIA Jetson AGX Orin 模塊在所有 MLPerf 測(cè)試中繼續(xù)表現(xiàn)出整體領(lǐng)先的推理性能,包括圖像和語(yǔ)音識(shí)別自然語(yǔ)言處理和推薦系統(tǒng)。
H100 (又名 Hopper)提高了本輪測(cè)試所有六個(gè)神經(jīng)網(wǎng)絡(luò)中的單加速器性能標(biāo)桿。它在單個(gè)服務(wù)器和離線場(chǎng)景中展現(xiàn)出吞吐量和速度方面的領(lǐng)先優(yōu)勢(shì)。
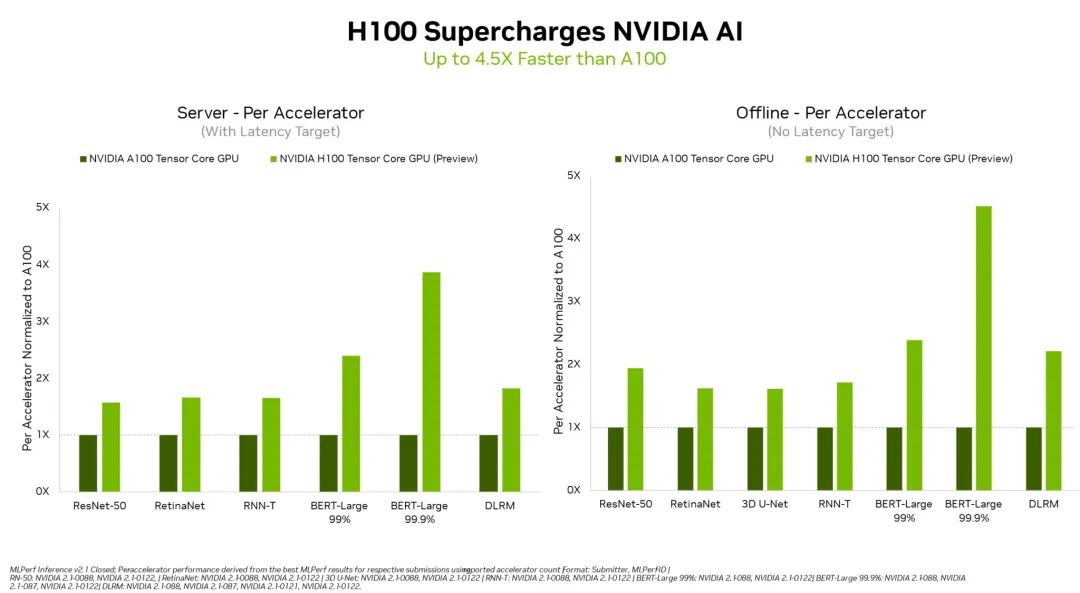
NVIDIA H100 GPU 在數(shù)據(jù)中心類別的所有工作負(fù)載上都樹(shù)立了新標(biāo)桿
NVIDIA Hopper 架構(gòu)的性能比 NVIDIA Ampere 架構(gòu)高出 4.5 倍;Ampere 架構(gòu) GPU 在 MLPerf 結(jié)果中繼續(xù)保持全方位領(lǐng)先地位。
Hopper 在流行的用于自然語(yǔ)言處理的 BERT 模型上表現(xiàn)出色部分歸功于其 Transformer Engine。BERT 是 MLPerf AI 模型中規(guī)模最大、對(duì)性能要求最高的的模型之一。
這些推理基準(zhǔn)測(cè)試標(biāo)志著 H100 GPU 的首次公開(kāi)亮相,它將于今年晚些時(shí)候上市。H100 GPU 還將參加未來(lái)的 MLPerf 訓(xùn)練基準(zhǔn)測(cè)試。
A100 GPU 展現(xiàn)領(lǐng)先優(yōu)勢(shì)
在最新測(cè)試中,NVIDIA A100 GPU 繼續(xù)在主流 AI 推理性能方面展現(xiàn)出全方位領(lǐng)先,目前主要的云服務(wù)商和系統(tǒng)制造商均提供 A100 GPU。
在數(shù)據(jù)中心和邊緣計(jì)算類別與場(chǎng)景中,A100 GPU 贏得的測(cè)試項(xiàng)超過(guò)了任何其他提交的結(jié)果。A100 還在 6 月的 MLPerf 訓(xùn)練基準(zhǔn)測(cè)試中取得了全方位的領(lǐng)先,展現(xiàn)了其在整個(gè) AI 工作流中的能力。
自 2020 年 7 月在 MLPerf 上首次亮相以來(lái)由于 NVIDIA AI 軟件的不斷改進(jìn),A100 GPU 的性能已經(jīng)提升了 6 倍。
NVIDIA AI 是唯一能夠在數(shù)據(jù)中心和邊緣計(jì)算中運(yùn)行所有 MLPerf 推理工作負(fù)載和場(chǎng)景的平臺(tái)。
用戶需要通用性能
NVIDIA GPU 在所有主要 AI 模型上的領(lǐng)先性能,使用戶成為真正的贏家。用戶在實(shí)際應(yīng)用中通常會(huì)采用許多不同類型的神經(jīng)網(wǎng)絡(luò)。
例如,一個(gè)AI 應(yīng)用可能需要理解用戶的語(yǔ)音請(qǐng)求、對(duì)圖像進(jìn)行分類、提出建議,然后以人聲作為語(yǔ)音信息提供回應(yīng)。每個(gè)步驟都需要用到不同類型的 AI 模型。
MLPerf 基準(zhǔn)測(cè)試涵蓋了所有這些和其他流行的 AI 工作負(fù)載與場(chǎng)景,比如計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理、推薦系統(tǒng)、語(yǔ)音識(shí)別等。這些測(cè)試確保用戶將獲得可靠且部署靈活的性能。
MLPerf 憑借其透明性和客觀性使用戶能夠做出明智的購(gòu)買決定。該基準(zhǔn)測(cè)試得到了包括亞馬遜、Arm、百度、谷歌、哈佛大學(xué)、英特爾、Meta、微軟、斯坦福大學(xué)和多倫多大學(xué)在內(nèi)的廣泛支持。
Orin 在邊緣計(jì)算領(lǐng)域保持領(lǐng)先
在邊緣計(jì)算方面,NVIDIA Orin 運(yùn)行了所有 MLPerf 基準(zhǔn)測(cè)試,是所有低功耗系統(tǒng)級(jí)芯片中贏得測(cè)試最多的芯片。并且,與 4 月在 MLPerf 上的首次亮相相比,其能效提高了50%。
在上一輪基準(zhǔn)測(cè)試中,Orin 的運(yùn)行速度和平均能效分別比上一代 Jetson AGX Xavier 模塊高出 5 倍和 2 倍。
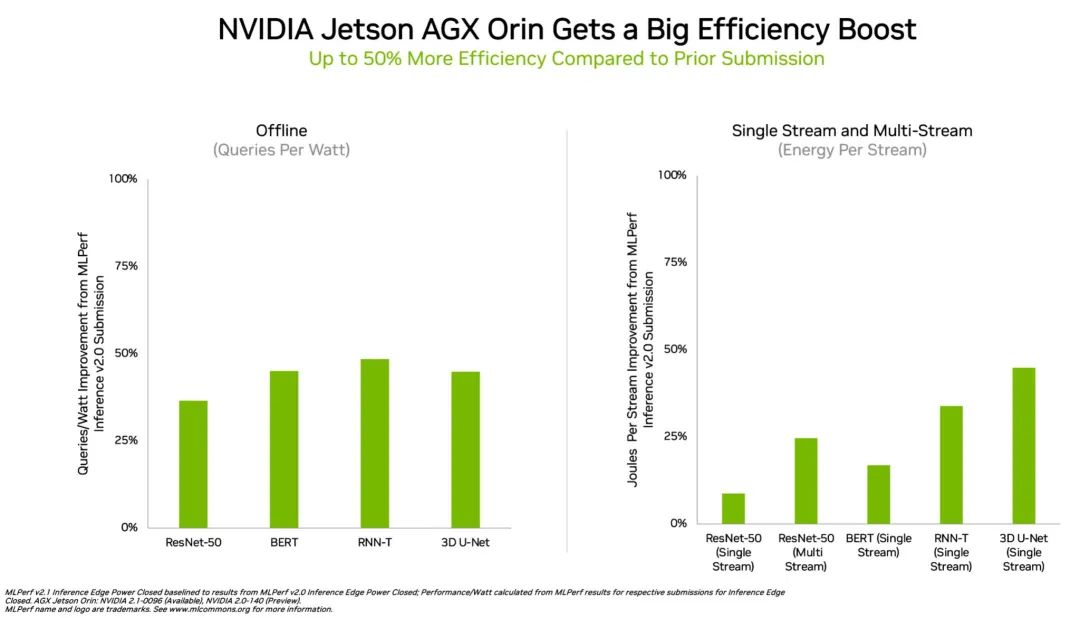
在能效方面,Orin 邊緣 AI 推理性能提升多達(dá) 50%
Orin 將 NVIDIA Ampere 架構(gòu) GPU 和強(qiáng)大的 Arm CPU 內(nèi)核集成到一塊芯片中。目前,Orin 現(xiàn)已被用在 NVIDIA Jetson AGX Orin 開(kāi)發(fā)者套件以及機(jī)器人和自主系統(tǒng)生產(chǎn)模塊,并支持完整的 NVIDIA AI 軟件堆棧,,包括自動(dòng)駕駛汽車平臺(tái)(NVIDIA Hyperion)、醫(yī)療設(shè)備平臺(tái)(Clara Holoscan)和機(jī)器人平臺(tái)(Isaac)。
廣泛的 NVIDIA AI 生態(tài)系統(tǒng)
MLPerf 結(jié)果顯示,NVIDIA AI 得到了業(yè)界最廣泛的機(jī)器學(xué)習(xí)生態(tài)系統(tǒng)的支持。
在這一輪基準(zhǔn)測(cè)試中,有超過(guò) 70 項(xiàng)提交結(jié)果在 NVIDIA 平臺(tái)上運(yùn)行。例如,Microsoft Azure 提交了在其云服務(wù)上運(yùn)行 NVIDIA AI 的結(jié)果。
此外,10 家系統(tǒng)制造商的 19 個(gè) NVIDIA 認(rèn)證系統(tǒng)參加了本輪基準(zhǔn)測(cè)試,包括華碩、戴爾科技、富士通、技嘉、慧與、聯(lián)想、和超微等。
它們的結(jié)果表明,無(wú)論是在云端還是在自己數(shù)據(jù)中心運(yùn)行的服務(wù)器中,用戶都可以借助 NVIDIA AI 獲得出色的性能。
NVIDIA 的合作伙伴參與 MLPerf 是因?yàn)樗麄冎肋@是一個(gè)為客戶評(píng)估 AI 平臺(tái)和廠商的重要工具。最新一輪結(jié)果表明,他們目前向用戶提供的性能將隨著 NVIDIA 平臺(tái)的發(fā)展而增長(zhǎng)。
用于這些測(cè)試的所有軟件都可以從 MLPerf 庫(kù)中獲得,因此任何人都可以獲得這些世界級(jí)成果。NGC( NVIDIA 的 GPU 加速軟件目錄)上正在源源不斷地增加以容器化形式提供的優(yōu)化。在這里,你還會(huì)發(fā)現(xiàn) NVIDIA TensorRT,本輪測(cè)試的每此提交都使用它來(lái)優(yōu)化 AI 推斷。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
31079瀏覽量
222274 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5594瀏覽量
109754 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135467 -
英偉達(dá)
+關(guān)注
關(guān)注
23文章
4087瀏覽量
99195 -
H100
+關(guān)注
關(guān)注
0文章
33瀏覽量
588
原文標(biāo)題:NVIDIA Hopper 首次亮相 MLPerf,在 AI 推理基準(zhǔn)測(cè)試中一騎絕塵
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
借助NVIDIA CUDA Tile IR后端推進(jìn)OpenAI Triton的GPU編程
曦望發(fā)布新一代推理GPU芯片,單位Token推理成本降低90%
NVIDIA RTX PRO 5000 Blackwell GPU的深度評(píng)測(cè)

NVIDIA RTX PRO 4000 Blackwell GPU性能測(cè)試

在Python中借助NVIDIA CUDA Tile簡(jiǎn)化GPU編程

NVIDIA RTX PRO 2000 Blackwell GPU性能測(cè)試

英偉達(dá) H100 GPU 掉卡?做好這五點(diǎn),讓算力穩(wěn)如泰山!

NVIDIA RTX PRO 4500 Blackwell GPU測(cè)試分析

NVIDIA桌面GPU系列擴(kuò)展新產(chǎn)品
別讓 GPU 故障拖后腿,捷智算GPU維修室來(lái)救場(chǎng)!
NVIDIA Blackwell GPU優(yōu)化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場(chǎng)景中的性能紀(jì)錄

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】+NVlink技術(shù)從應(yīng)用到原理
iTOP-3588S開(kāi)發(fā)板四核心架構(gòu)GPU內(nèi)置GPU可以完全兼容0penGLES1.1、2.0和3.2。
GPU 維修干貨 | 英偉達(dá) GPU H100 常見(jiàn)故障有哪些?



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論