 對預訓練模型在召回與排序部分的應用做一個總結
對預訓練模型在召回與排序部分的應用做一個總結

本文對預訓練模型在召回(retrieval), 排序(re-ranking),以及其他部分的應用做一個總結。
1. 背景
搜索任務就是給定一個query或者QA中的question,去大規模的文檔庫中找到相似度較高的文檔,并返回一個按相關度排序的ranked list。
由于待訓練的模型參數很多(增加model capacity),而專門針對檢索任務的有標注數據集較難獲取,所以要使用預訓練模型。
2. 檢索模型的分類
檢索的核心,在于計算query和document的 相似度 。依此可以把信息檢索模型分為如下三類:
基于統計的檢索模型
使用exact-match來衡量
代表性的模型是BM25,用來衡量一個term在doc中的重要程度,其公式如下:
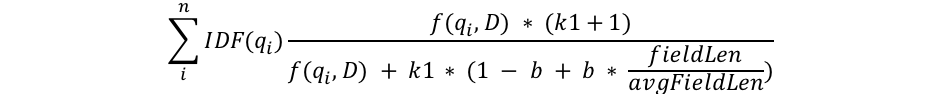 懲罰長文本、對詞頻做飽和化處理
懲罰長文本、對詞頻做飽和化處理
實際上,BM25是檢索模型的強baseline。基于exact-match的檢索模型是召回中必不可少的一路。
Learning-to-Rank模型
這類模型需要手動構造特征,包括
query端特征,如query類型、query長度(還可以加入意圖slot?);
document端特征(document長度,Pagerank值);
query-document匹配特征(BM25值,相似度,編輯距離等)。
其實,在現在常用的深度檢索模型中也經常增加這種人工構造的特征。根據損失函數又可分為pointwise(簡單的分類/回歸損失)、Pairwise(triplet hinge loss,cross-entropy loss)、Listwise。
深度模型
使用query和document的embedding進行端到端學習。可以分為
representation-focused models(用雙塔建模query和document,之后計算二者相似度,雙塔之間無交互,用于召回)
interaction-focused models(金字塔模型,計算每個query token和每個document token的相似度矩陣,用于精排。精排階段還可增加更多特征,如多模態特征、用戶行為特征、知識圖譜等)
3. 預訓練模型在倒排索引中的應用
基于倒排索引的召回方法仍是在第一步召回中必不可少的,因為在第一步召回的時候我們面對的是海量的文檔庫,基于exact-match召回速度很快。但是,其模型capacity不足,所以可以用預訓練模型來對其進行模型增強。
3.1 term re-weighting
代表論文: DeepCT (Deep Contextualized Term Weighting framework: Context-Aware Sentence/Passage Term Importance Estimation For First Stage Retrieval).
普通的exact-match中衡量一個詞在query/document中的重要程度就是通過詞頻(TF)或者TFIDF,或者TFIDF的改進版本--BM25,例如在建立倒排索引的時候,每個term在不同document的重要程度就是用TF來衡量的。
但是,一個詞在兩個document中出現頻率相同,就說明這個詞在兩個document中同樣重要嗎?其實詞的重要程度比詞頻要復雜的多。
所以,可以使用contextualized模型,例如BERT,Elmo等獲得每個詞的 上下文 表示,然后通過簡單的線性回歸模型得到每個詞在document中的重要程度。文檔真實詞語權重的估計如下,這個值作為我們訓練的label:
其中, 是與文檔 d 相關的查詢問題的集合; 是包含詞語 t 的查詢問題集合 的子集; 是文檔 d 中詞語 t 的權重。的取值范圍為,以此為label訓練。這樣,我們就得到了一個詞在document中的重要程度,可以替換原始TF-IDF或BM25的詞頻。對于query,也可以用同樣的方法得到每個詞的重要程度,用來替換TFIDF。
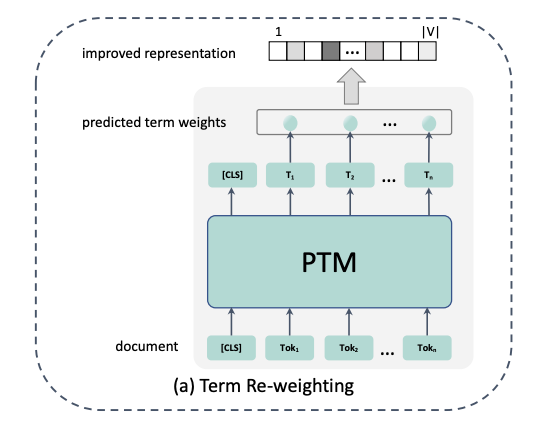
3.2 Document expansion
除了去估計不同term在document中的重要程度,還可以直接顯式地擴增document,這樣一來提升了重要詞語的權重,二來也能夠召回"詞不同意同"的文檔(解決lexical-mismatch問題)。
例如,可以對T5在query-document對上做微調,然后對每個document做文本生成,來生成對應的query,再加到document中。之后,照常對這個擴增好的document建倒排索引,用BM25做召回。代表工作:docTTTTTquery[3]
同樣地,也可以對query進行擴增。例如對于QA中的question,可以把訓練目標定為包含答案的句子、或者包含答案的文章title,然后用seq2seq模型訓練,再把模型生成的文本加到query后面,形成擴增的query。
3.3 term reweighting + document expansion
那么,我們可不可以同時做term reweighting和document expansion呢?這方面的代表工作是Sparterm[4]
此模型分為兩部分:重要度預測模塊(用來得到 整個vocab上 的重要程度)和門控模塊(得到二進制的門控信號,以此來得到最終保留的稀疏token,最終只能保留 個token)。由于重要度是針對整個vocab而言的,所以可以同時實現重要度評估+詞語擴增。
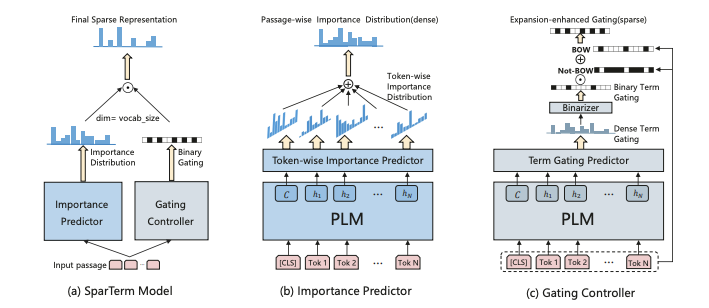
重要度預測模塊采用了類似MLM的思想,即先用BERT對句子做好contextualized embedding,然后乘上vocab embedding 矩陣 E ,得到這個詞對應的重要度分布:
這句話整體的重要度分布就是所有詞對應的重要度分布取relu(重要度不能是負數),然后加起來的和:
門控模塊和重要度評估模塊的計算方法類似,只是參數不再是 E , 而是另外的變換矩陣。得到gating distribution G 之后,先將其0/1化為 G' (如果G中元素>threshold則取1,否則取0);然后得到我們需要保留的詞語(exact-match必須保留,還增加一些擴增的token)。
通過端到端的方式訓練,訓練的損失函數有兩個,其中一個就是我們常見的ranking loss,即取
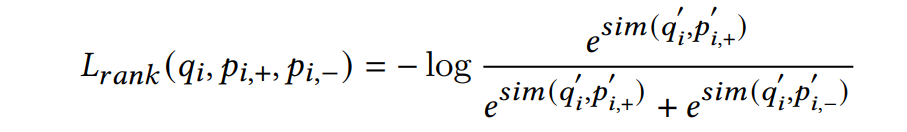
另一個loss專門對門控模塊做更新,訓練數據是
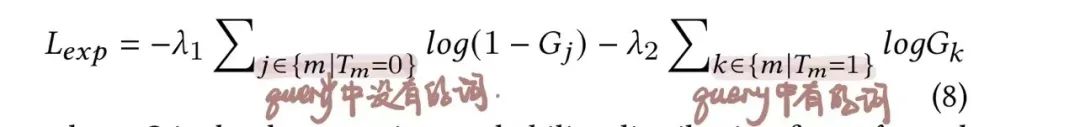
T為真實query的bag of words
審核編輯:劉清
-
矩陣
+關注
關注
1文章
448瀏覽量
36094 -
機器學習算法
+關注
關注
2文章
47瀏覽量
6844
原文標題:總結!語義信息檢索中的預訓練模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是大模型,智能體...?大模型100問,快速全面了解!

在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
基于大規模人類操作數據預訓練的VLA模型H-RDT

大模型時代的深度學習框架

恩智浦eIQ Time Series Studio工具使用教程之模型訓練
請問如何在imx8mplus上部署和運行YOLOv5訓練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

憶聯PCIe 5.0 SSD支撐大模型全流程訓練



 工商網監
工商網監
評論