") CEVA的NeuPro-M AI處理器有助于提高能效
CEVA的NeuPro-M AI處理器有助于提高能效

AI 技術(shù)愈來愈受歡迎,在汽車、視覺處理和電信等領(lǐng)域的應(yīng)用也越來越多。目前,AI 正在通過實現(xiàn)眾多新功能來取代許多傳統(tǒng)算法,例如為智能手機攝像頭提供去噪和圖像穩(wěn)定功能。
在眾多實施 AI 的產(chǎn)品都將數(shù)據(jù)發(fā)送到云數(shù)據(jù)中心的同時,也凸顯出一些主要缺點:延遲增加、隱私風(fēng)險以及需要互聯(lián)網(wǎng)連接。
設(shè)計人員希望創(chuàng)建一些 AI 系統(tǒng),使其在通常采用電池供電的邊緣設(shè)備上運行,但這也帶來了新的挑戰(zhàn),既實現(xiàn)需求的性能和功能與功耗之間的平衡,尤其是在持續(xù)快速且越來越多的需要更多計算能力的情況下。
AI 處理挑戰(zhàn)
雖然眾多不同邊緣設(shè)備的要求都各不相同,但它們基本上都是為了最大程度地提高性能,降低功耗,并盡量減少所需的物理空間。設(shè)計工程師如何作出合適的權(quán)衡才能應(yīng)對這些挑戰(zhàn)?
現(xiàn)有 AI 處理器的性能往往受到帶寬限制,并且在將數(shù)據(jù)移入和移出外部內(nèi)存時也會遇到瓶頸,導(dǎo)致系統(tǒng)利用率低,這也就意味著性能/功率數(shù)值(以 TOPS/Watt 為單位)受到限制。
另一個重要問題是如何提前計劃滿足未來需求。由于 AI 處理器芯片的部署周期通常較長,因此 AI 解決方案必須能夠適應(yīng)未來的新要求,包括支持尚未定義的新神經(jīng)網(wǎng)絡(luò)。這意味著所有解決方案都必須足夠靈活、可擴展,才能隨著性能需求的增加而提升。
AI 系統(tǒng)還必須安全,并且必須符合最高的質(zhì)量和安全標(biāo)準(zhǔn),尤其是對于汽車應(yīng)用和其他人工智能系統(tǒng)可能涉及生命攸關(guān)的決策的應(yīng)用。例如,如果一位行人走到自動駕駛汽車前面,留給司機的反應(yīng)時間是非常短的。
為了幫助克服這些挑戰(zhàn),就需要一個全面的軟件工具鏈,簡化客戶實施,減少開發(fā)時間。
AI 處理器逐步提升
讓我們以視覺機器學(xué)習(xí)為例,看看 AI 解決方案提供商如何應(yīng)對這些挑戰(zhàn)。
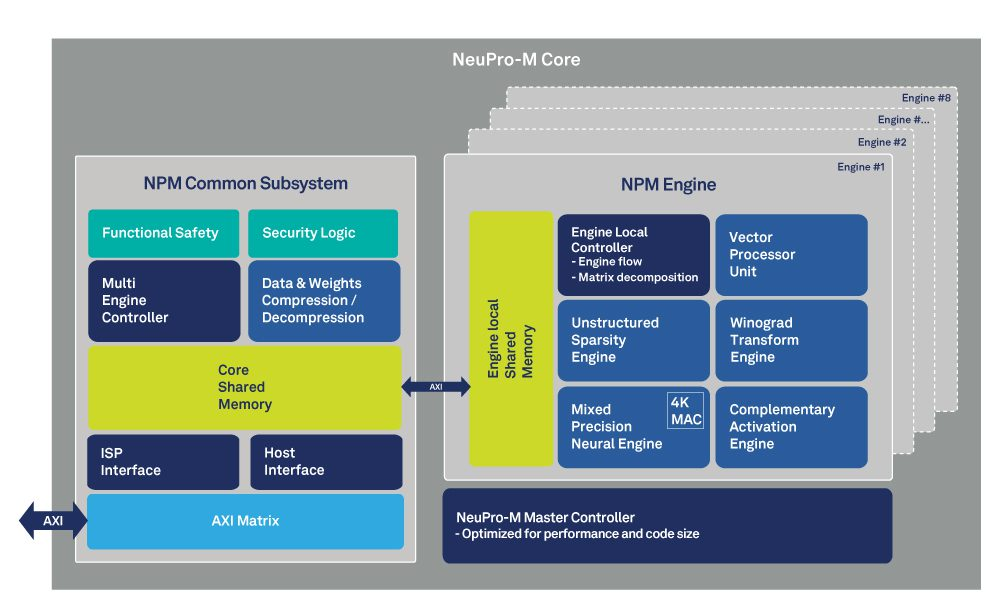
圖 1:NeuPro-M AI 處理器框圖,顯示內(nèi)存架構(gòu)
首先,如果我們考慮帶寬限制性能和內(nèi)存訪問權(quán)限問題,可以通過動態(tài)配置的兩級內(nèi)存體系架構(gòu)來加以解決(參見圖 1)。這樣可以最大限度地降低與外部 SDRAM 進行數(shù)據(jù)傳輸產(chǎn)生的功耗。通過以分層方式使用本地內(nèi)存資源,實現(xiàn) 90% 以上的利用率,防止協(xié)處理器和加速器出現(xiàn)“數(shù)據(jù)匱乏”情形,同時還可使每個引擎獨立處理。
優(yōu)化 AI 處理的另一種方法是通過使處理器架構(gòu)支持混合精度的神經(jīng)引擎。這種方法可以處理 2 到 16 位的數(shù)據(jù),減少系統(tǒng)帶寬消耗,除此之外,還能按每個用例靈活運行混合精度網(wǎng)絡(luò)。此外,當(dāng)數(shù)據(jù)從外部內(nèi)存寫入或讀取時,數(shù)據(jù)壓縮之類的帶寬減少機制還能實時壓縮數(shù)據(jù)和權(quán)重。這種方法減少了所需的內(nèi)存帶寬,進一步提高了性能,顯著降低了總功耗。
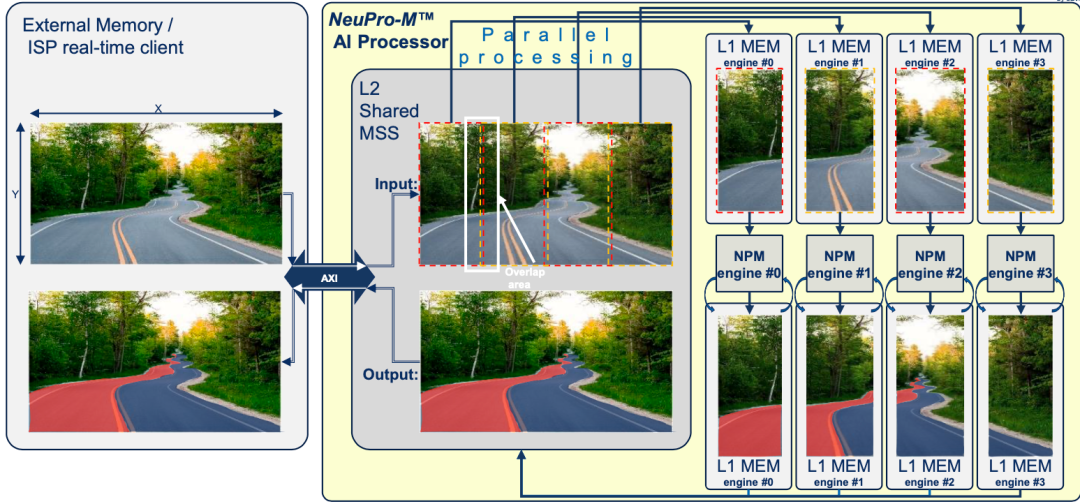
圖2:四引擎內(nèi)核細分
這是 CEVA 的 NeuPro-M AI 處理器采用的方法,是一種用于 AI/ML 推理工作負載的獨立異構(gòu)處理器架構(gòu)。以此解決方案為例,圖 2 顯示了如何在四 AI 引擎之間分割機器視覺應(yīng)用,在本案例中是對前方道路進行車道檢測。圖像數(shù)據(jù)從外部內(nèi)存或外部接口加載,然后分成四個拼圖,每個拼圖由不同的引擎處理。換句話說,每個引擎可以各自承擔(dān)一個子圖或不同的任務(wù),例如物體檢測和車道識別,以便優(yōu)化特定應(yīng)用的性能。
每個引擎都有自己的片上 L1 內(nèi)存,以便最大程度地減少瓶頸或延遲。這也意味著,一旦配置好,AI 處理器就幾乎可以完全獨立地運行了,并且在大多數(shù)情況下,可以運行“從頭到尾”的“融合”操作流水線,完全無需訪問內(nèi)部內(nèi)存且?guī)缀鹾苌僭L問外部內(nèi)存。如此一來,AI 處理器將變得更加靈活,并有助于提高能效。
我們在本文開始時討論的要求還包括提供面向未來的靈活解決方案。完全可編程的矢量處理單元 (VPU) 可以在同一引擎 L1 數(shù)據(jù)上與協(xié)處理器并行工作,確保新的神經(jīng)網(wǎng)絡(luò)拓撲以軟件方式提供支持
機器視覺優(yōu)化
有許多優(yōu)化可以提升特定 AI 應(yīng)用的性能。在視覺處理過程中,Winograd 轉(zhuǎn)換就屬于這種優(yōu)化之一。這是執(zhí)行卷積(例如傅里葉變換)的另一種高效方法,只需使用以前所需的 MAC(乘累加運算)數(shù)量的一半。
對于 3x3 卷積層而言,Winograd 轉(zhuǎn)換可以將性能提高一倍,同時保持與原始卷積方法相同的精度。
另一個基本的優(yōu)化是使用稀疏化,即能夠忽略數(shù)據(jù)或權(quán)重中的零。通過避免乘以零,性能得到了改善,同時保持了準(zhǔn)確性。雖然某些處理器需要結(jié)構(gòu)化數(shù)據(jù)才能享受稀疏化帶來的好處,但使用完全支持非結(jié)構(gòu)化稀疏化的處理器可以獲得更好的結(jié)果。
通常,AI 系統(tǒng)需要將某些優(yōu)化功能或網(wǎng)絡(luò)固有操作(如 Winograd 轉(zhuǎn)換、稀疏機制、自關(guān)注操作和縮放)交給專門的引擎。這意味著需要先卸載數(shù)據(jù),然后在處理后再重新加載數(shù)據(jù),這樣一來就會增加延遲并降低性能。對比之下,更好的選擇就是將加速器直接連接到引擎本地共享 L1 內(nèi)存,或者在大多數(shù)情況下,進行融合操作,即從一個協(xié)處理器到另一個協(xié)處理器的即時端到端處理,而不需要在執(zhí)行過程中訪問任何內(nèi)存。
這些優(yōu)化有多重要?圖 3 顯示,與 CEVA 的上一代 AI 處理器相比,單引擎 NPM11 內(nèi)核在典型的 ResNet50 實施中實現(xiàn)了性能提升。您可以看到,基本的、原生的操作實現(xiàn)了近五倍的性能提升。
添加 Winograd 轉(zhuǎn)換,然后添加稀疏引擎可以進一步提高性能,最高可達上一代處理器的 9.3 倍。最后,對一些網(wǎng)絡(luò)層使用混合精度(8x8 和低分辨率 4x4)權(quán)重和激活,在可以忽略不計的精度損失的情況下,進一步提高了性能--實現(xiàn)了比上一代處理器近15倍的性能提升,比原生處理快 2.9 倍。
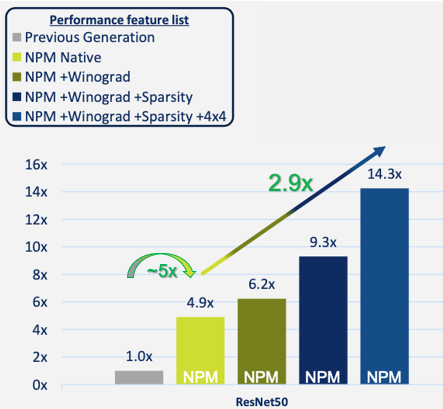
圖 3:NPM11(單引擎內(nèi)核)性能改進
結(jié)論
我們已經(jīng)看到了新內(nèi)存架構(gòu)和本地“負載平衡”控制實現(xiàn)(流水線處理對比連續(xù)處理相同數(shù)據(jù)),最大限度地減少外部訪問的情形,并充分利用了硬件,可以在不需要更多功耗的情況下提高性能,以及 Winograd 轉(zhuǎn)換和稀疏性等優(yōu)化進一步提升性能的方法。
總而言之,現(xiàn)代 AI 處理器可以提供完全可編程的硬件/軟件開發(fā)環(huán)境,具有要求苛刻的邊緣 AI 應(yīng)用所需的性能、能效和靈活性,這使設(shè)計工程師能夠從其系統(tǒng)內(nèi)的有效AI實現(xiàn)中受益,而不會增加超出其便攜式邊緣設(shè)備預(yù)算的功耗。
-
dsp
+關(guān)注
關(guān)注
561文章
8244瀏覽量
366687 -
藍牙
+關(guān)注
關(guān)注
119文章
6313瀏覽量
178742 -
帶寬
+關(guān)注
關(guān)注
3文章
1040瀏覽量
43375 -
CEVA
+關(guān)注
關(guān)注
1文章
197瀏覽量
77198 -
AI處理器
+關(guān)注
關(guān)注
0文章
94瀏覽量
10026
原文標(biāo)題:CEVA的NeuPro-M AI 處理器如何迎接邊緣 AI 挑戰(zhàn)
文章出處:【微信號:CEVA-IP,微信公眾號:CEVA】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Cortex-M0 處理器介紹
Ceva 添加 Sensory 的 TrulyHandsfree 語音激活功能, 增強 NeuPro-Nano NPU 生態(tài)系統(tǒng)

Ceva在恩智浦的軟件定義車輛處理器上實現(xiàn) 實時人工智能加速

瑞芯微SOC智能視覺AI處理器
AMD推出 EPYC 嵌入式 2005 系列處理器 滿足長期部署需求

基于E203 NICE協(xié)處理器擴展指令
基于E203 NICE協(xié)處理器擴展指令2.0
Cortex-M0+處理器的HardFault錯誤介紹
安謀科技發(fā)布“星辰”STAR-MC3,提升MCU AI處理能力
瑞薩電子RZ/V系列微處理器助力邊緣AI開發(fā)

TLM1211F-121LE大功率貼片功率電感器現(xiàn)貨庫存
AMD嵌入式處理器為您的應(yīng)用添能助力
優(yōu)化電機控制以提高能效
光子 AI 處理器的核心原理及突破性進展
如何基于Kahn處理網(wǎng)絡(luò)定義AI引擎圖形編程模型



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論