 NVIDIA FasterTransformer庫的概述及好處
NVIDIA FasterTransformer庫的概述及好處

這是討論 NVIDIA FasterTransformer 庫的兩部分系列的第一部分,該庫是用于對任意大小(多達數萬億個參數)的 Transformer 進行分布式推理的最快庫之一。它提供了 FasterTransformer 的概述,包括使用該庫的好處。
使用 FasterTransformer 和 Triton 推理服務器部署 GPT-J 和 T5(第 2 部分)是一個指南,說明了使用 FasterTransformer 庫和 Triton 推理服務器以具有張量并行性的最佳方式為 T5-3B 和 GPT-J 6B 模型提供服務。
Transformers 是當今最具影響力的 AI 模型架構之一,正在塑造未來 AI 研發的方向。它們最初是作為自然語言處理 (NLP) 的工具而發明的,現在幾乎用于任何 AI 任務,包括計算機視覺、自動語音識別、分子結構分類和金融數據處理。考慮到如此廣泛使用的是注意力機制,它顯著提高了模型的計算效率、質量和準確性。
具有數千億參數的大型基于 Transformer 的模型的行為就像一個巨大的百科全書和大腦,其中包含有關它所學到的一切的信息。他們以獨特的方式對所有這些知識進行結構化、表示和總結。擁有具有大量先驗知識的此類模型使我們能夠使用新的強大的一次性或少量學習技術來解決許多 NLP 任務。
由于它們的計算效率,Transformer 可以很好地擴展——通過增加網絡的規模和訓練數據的數量,研究人員可以改善觀察并提高準確性。
然而,訓練如此大的模型并非易事。這些模型可能需要比一個 GPU 供應更多的內存——甚至是數百個 GPU。值得慶幸的是,NVIDIA 研究人員已經創建了強大的開源工具,例如 NeMo Megatron,可以優化訓練過程。
快速和優化的推理使企業能夠充分發揮這些大型模型的潛力。最新研究表明,增加模型和數據集的大小可以提高這種模型在不同領域(NLP、CV 等)下游任務上的質量。
同時,數據表明這種技術也適用于多域任務。(例如,參見 OpenAI 的 DALLE-2 和 Google 的 Imagen 等關于文本到圖像生成的研究論文。)依賴于大型模型的“凍結”拷貝的 p-tuning 等研究方向甚至增加了擁有穩定且優化的推理流程。此類大型模型的優化推理需要分布式多 GPU 多節點解決方案。
用于加速推斷大型 Transformer 的庫
NVIDIA FasterTransformer (FT) 是一個庫,用于實現基于 Transformer 的神經網絡推理的加速引擎,特別強調大型模型,以分布式方式跨越許多 GPU 和節點。
FasterTransformer 包含 Transformer 塊的高度優化版本的實現,其中包含編碼器和解碼器部分。
使用此模塊,您可以運行完整的編碼器-解碼器架構(如 T5)以及僅編碼器模型(如 BERT)或僅解碼器模型(如 GPT)的推理。它是用 C++/CUDA 編寫的,依賴于高度優化的 cuBLAS、cuBLASLt 和 cuSPARSELt 庫。這使您可以在 GPU 上構建最快的 Transformer 推理流程。
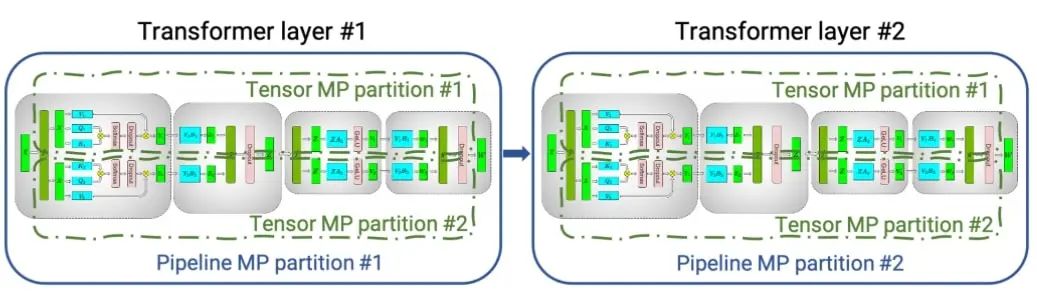
圖 1.使用張量并行(張量 MP 分區)和管道并行(管道 MP 分區),在四個 GPU 之間分布了幾個 transformer / attention 塊
與 NVIDIA TensorRT 等其他編譯器相比,FT 的顯著特點是它支持以分布式方式推斷大型 Transformer 模型。
上圖顯示了如何使用張量并行 (TP) 和流水線并行 (PP) 技術將具有多個經典 transformer/attention 的神經網絡拆分到多個 GPU 和節點上。
當每個張量被分成多個塊時,就會發生張量并行性,并且張量的每個塊都可以放置在單獨的 GPU 上。在計算過程中,每個塊在不同的 GPU 上單獨并行處理,并且可以通過組合來自多個 GPU 的結果來計算結果(最終張量)。
當模型被深度拆分并將不同的完整層放置到不同的 GPU/節點上時,就會發生流水線并行。
在底層,啟用節點間/節點內通信依賴于 MPI 和 NVIDIA NCCL。使用此軟件堆棧,您可以在多個 GPU 上以張量并行模式運行大型 Transformer,以減少計算延遲。
同時,TP 和 PP 可以結合在一起,在多 GPU 和多節點環境中運行具有數十億和數萬億個參數(相當于 TB 級權重)的大型 Transformer 模型。
除了 C 中的源代碼,FasterTransformer 還提供 TensorFlow 集成(使用 TensorFlow 操作)、PyTorch 集成(使用 PyTorch 操作)和 Triton 集成作為后端。
目前,TensorFlow op 僅支持單 GPU,而 PyTorch op 和 Triton 后端都支持多 GPU 和多節點。
為了避免為模型并行性而拆分模型的額外工作,FasterTransformer 還提供了一個工具,用于將模型從不同格式拆分和轉換為 FasterTransformer 二進制文件格式。然后 FasterTransformer 可以直接以二進制格式加載模型。
目前,FT 支持 Megatron-LM GPT-3、GPT-J、BERT、ViT、Swin Transformer、Longformer、T5 和 XLNet 等模型。您可以在 GitHub 上的 FasterTransformer 存儲庫中查看最新的支持矩陣。
FT 適用于計算能力 >= 7.0 的 GPU,例如 V100、A10、A100 等。
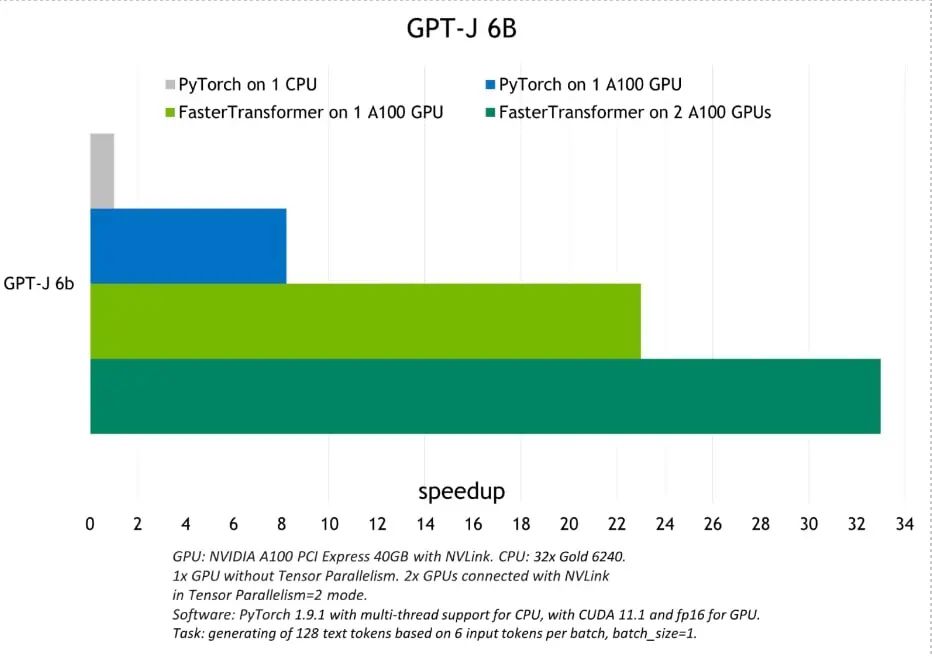
圖 2.GPT-J 6B 模型推斷和加速比較
FasterTransformer 中的優化
與深度學習訓練的通用框架相比,FT 使您能夠獲得更快的推理管道,并且基于 Transformer 的 NN 具有更低的延遲和更高的吞吐量。
允許 FT 對 GPT-3 和其他大型 Transformer 模型進行最快推理的一些優化技術包括:
層融合——預處理階段的一組技術,將多層神經網絡組合成一個單一的神經網絡,將使用一個單一的內核進行計算。這種技術減少了數據傳輸并增加了數學密度,從而加速了推理階段的計算。例如,multi-head attention 塊中的所有操作都可以合并到一個內核中。
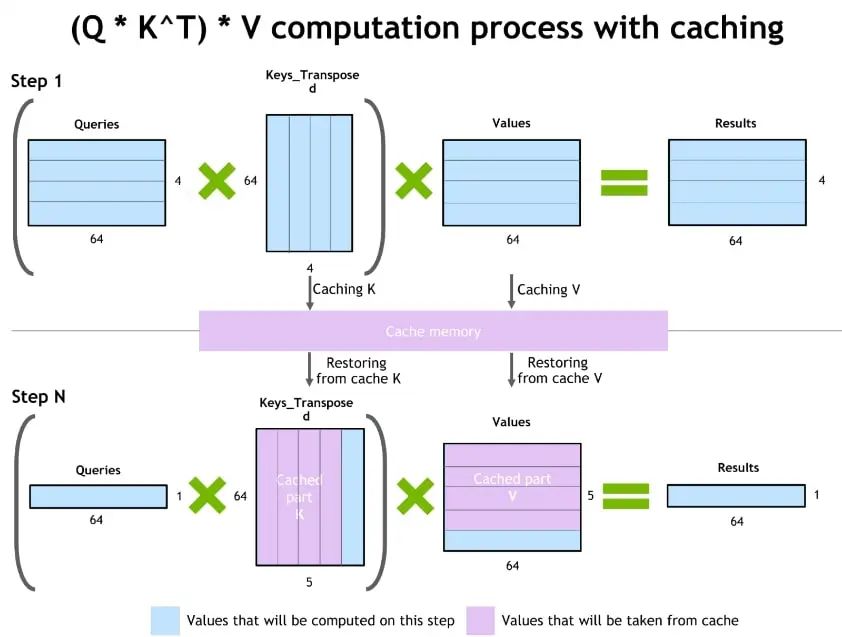
圖 3. NVIDIA Faster transformer 庫中緩存機制的演示
自回歸模型/激活緩存的推理優化
為了防止通過 Transformer 重新計算每個新 token 生成器的先前鍵和值,FT 分配一個緩沖區來在每一步存儲它們。
雖然需要一些額外的內存使用,但 FT 可以節省重新計算的成本、在每一步分配緩沖區以及連接的成本。該過程的方案上圖 所示。相同的緩存機制用于 NN 的多個部分。
內存優化
與 BERT 等傳統模型不同,大型 Transformer 模型具有多達數萬億個參數,占用數百 GB 存儲空間。即使我們以半精度存儲模型,GPT-3 175b 也需要 350 GB。因此有必要減少其他部分的內存使用。
例如,在 FasterTransformer 中,我們在不同的解碼器層重用了激活/輸出的內存緩沖區。由于 GPT-3 中的層數為 96,因此我們只需要 1/96 的內存量用于激活。
使用 MPI 和 NCCL 實現節點間/節點內通信并支持模型并行性
在 GPT 模型中,FasterTransormer 同時提供張量并行和流水線并行。對于張量并行性,FasterTransformer 遵循了 Megatron 的思想。對于自注意力塊和前饋網絡塊,FT 按行拆分第一個矩陣的權重,并按列拆分第二個矩陣的權重。通過優化,FT 可以將每個 Transformer 塊的歸約操作減少到兩倍。
對于流程并行性,FasterTransformer 將整批請求拆分為多個微批,隱藏了通信的泡沫。FasterTransformer 會針對不同情況自動調整微批量大小。
MatMul 內核自動調整(GEMM 自動調整)
矩陣乘法是基于 Transformer 的神經網絡中主要和最繁重的操作。FT 使用來自 CuBLAS 和 CuTLASS 庫的功能來執行這些類型的操作。重要的是要知道 MatMul 操作可以在“硬件”級別使用不同的低級算法以數十種不同的方式執行。
GemmBatchedEx 函數實現 MatMul 操作,并以“cublasGemmAlgo_t”作為輸入參數。使用此參數,您可以選擇不同的底層算法進行操作。
FasterTransformer 庫使用此參數對所有底層算法進行實時基準測試,并為模型的參數和您的輸入數據(注意層的大小、注意頭的數量、隱藏層的大小)選擇最佳的一個。此外,FT 對網絡的某些部分使用硬件加速的底層函數,例如 __expf、__shfl_xor_sync。
精度較低的推理
FT 的內核支持使用 fp16 和 int8 中的低精度輸入數據進行推理。由于較少的數據傳輸量和所需的內存,這兩種機制都允許加速。同時,int8 和 fp16 計算可以在特殊硬件上執行,例如張 Tensor Core(適用于從 Volta 開始的所有 GPU 架構),以及即將推出的 Hopper GPU 中的 Transformer 引擎。
更多
快速的 C++ BeamSearch 實現
針對 TensorParallelism 8 模式優化 all-reduce 當模型的權重部分在 8 個 GPU 之間拆分時
具有 FasterTransformer 后端的 NVIDIA Triton 推理服務器
NVIDIA Triton 推理服務器是一款開源推理服務軟件,有助于標準化模型部署和執行,在生產中提供快速且可擴展的 AI。Triton 穩定且快速,允許您使用準備好的 Docker 容器以簡單的方式運行 ML/DL 模型的推理,該容器僅使用一行代碼和簡單的類似 JSON 的配置。
Triton 支持使用多個后端的模型,例如 PyTorch、TorchScript、Tensorflow、ONNXRuntime 和 OpenVINO。Triton 采用您在其中一個框架中訓練的導出模型,并使用相應的后端為您透明地運行該模型進行推理。它也可以使用自定義后端進行擴展。Triton 使用 HTTP/gRPC API 包裝您的模型,并為多種語言提供客戶端庫。
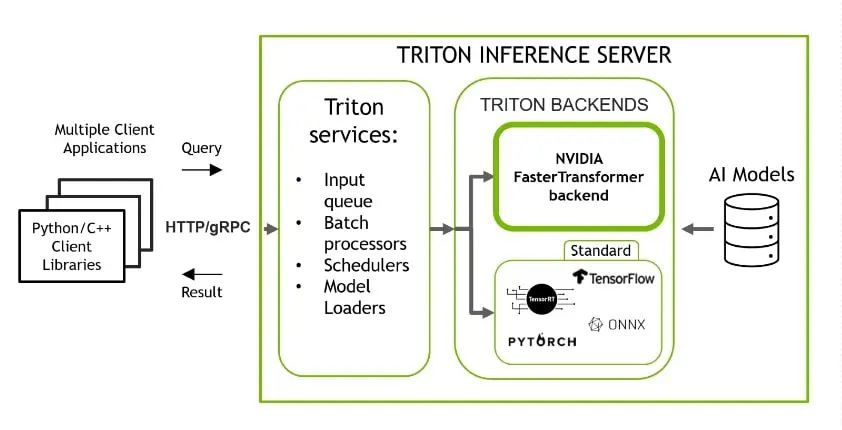
圖 4. Triton 推理服務器,具有多個后端,用于對使用不同框架訓練的模型進行推理
Triton 包含 FasterTransformer 庫作為后端(圖 4),該庫支持使用 TP 和 PP 運行大型 Transformer 模型的分布式多 GPU、多節點推理。今天,帶有 FasterTransformer 后端的 Triton 支持 GPT-J、GPT-Megatron 和 T5 模型。
有關演示使用 NVIDIA Triton 和 NVIDIA FasterTransformer 在優化推理中運行 T5-3B 和 GPT-J 6B 模型的過程的指南,請參閱使用 FasterTransformer 和 Triton 推理服務器部署 GPT-J 和 T5。
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109719 -
服務器
+關注
關注
14文章
10251瀏覽量
91480 -
Triton
+關注
關注
0文章
28瀏覽量
7320
原文標題:使用 FasterTransformer 和 Triton 推理服務器加速大型 Transformer 模型的推理
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用NORDIC AI的好處

基于NVIDIA Isaac庫開發的機器人調酒師ADAM亮相國際賽場
利用NVIDIA Cosmos開放世界基礎模型加速物理AI開發
NVIDIA 利用全新開源模型與仿真庫加速機器人研發進程

Cadence 借助 NVIDIA DGX SuperPOD 模型擴展數字孿生平臺庫,加速 AI 數據中心部署與運營
NVIDIA通過全新 Omniverse庫、Cosmos物理AI模型及AI計算基礎設施,為機器人領域開啟新篇章

NVIDIA Jetson AGX Thor開發者套件概述
NVIDIA Isaac Sim與NVIDIA Isaac Lab的更新
借助NVIDIA技術加速半導體芯片制造
英偉達GTC2025亮點:Oracle與NVIDIA合作助力企業加速代理式AI推理

NVIDIA Blackwell白皮書:NVIDIA Blackwell Architecture Technical Brief
NVIDIA Blackwell數據手冊與NVIDIA Blackwell架構技術解析
Oracle 與 NVIDIA 合作助力企業加速代理式 AI 推理




 工商網監
工商網監
評論