 輕量級視覺模型設計的新啟發
輕量級視覺模型設計的新啟發

計算機視覺兩大門派功力合體,給移動端視覺任務減負增速。
當下,計算機視覺領域最熱議的方向,莫過于近兩年越來越火的視覺Transformer(ViT)和傳統的卷積神經網絡(ConvNet),誰才能主宰計算機視覺的未來?
風頭正盛的ViT,是計算機視覺領域過去十年最矚目的研究突破之一。2020年,谷歌視覺大模型Vision Transformer(ViT)橫空出世,憑借碾壓各路ConvNet的性能表現,一舉掀起Transformer在計算機視覺領域的研究熱潮。
但“ConvNet派”還沒到低頭認輸的時候。2022年1月,Meta AI研究院、加州大學伯克利分校的研究人員發表了卷積神經網絡的“扛鼎之作”——ConvNeXt,基于純ConvNet新架構,取得了超過先進ViT的計算速度和精度。
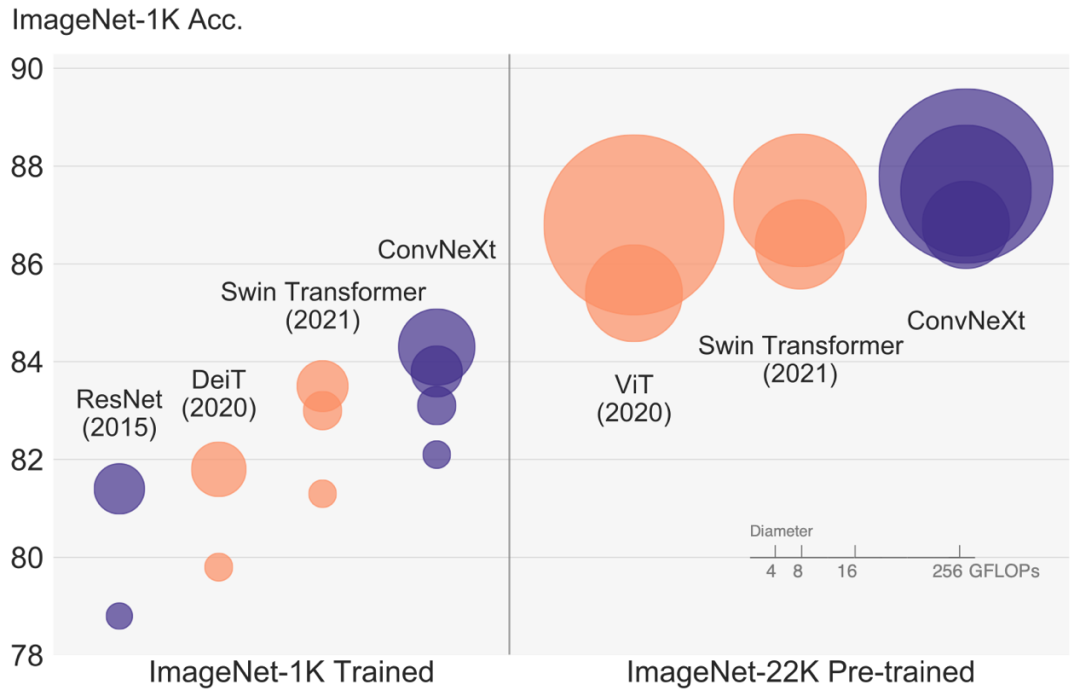
▲ConvNet與ViT模型圖像分類實驗結果對比
ViT論文:https://arxiv.org/abs/2010.11929
ConvNeXt論文:https://arxiv.org/abs/2201.03545
那如果將這兩類模型的優勢互補,會不會產生1+1》2的效果?
近日,基于這一思路的論文《ParC-Net:繼承ConvNet和Transformer優點的位置敏感的循環卷積》入選了計算機視覺頂會ECCV 2022,并引發國內外廣泛關注。
這篇論文提出了一種面向移動端、融入ViT優點的純卷積結構模型ParC-Net,能以更小的參數量,在常見視覺任務中實現比主流輕量級ConvNet更好的性能。

▲ParC-Net在三種視覺任務實驗中均以更小參數量取得最佳性能表現
值得一提的是,論文提出一種既有全局感受野、又對位置信息保持敏感的基礎卷積算子ParC,它能與現有主流網絡結構融合,兼顧模型性能和計算速度的提升,相關代碼現已開源。
具體是怎么實現的?我們聯系到論文第一作者張號逵博士,并與其進行深入交流。
ParC論文:https://arxiv.org/abs/2203.03952
源代碼:https://github.com/hkzhang91/ParC-Net
01.
取ViT的三個亮點,將純卷積結構變強
在計算機視覺領域,ViT模型性能彪悍,門檻和成本卻驚人,無論是龐大數據量,還是超高算力需求,都離不開“鈔能力”的支撐。
相比之下,輕量級ConvNet雖然性能難以與ViT媲美,但具有易訓練、參數量少、計算成本低、推理速度快等優勢,對硬件資源的需求不像ViT那么受限,可部署在各種移動或邊緣計算設備上。此前較流行的輕量級ConvNet有ShuffleNet、MobileNet、EfficientNet、TinyNet等等。
經對比,云天勵飛的研究人員借鑒ViT的優點,基于卷積結構設計了一個輕量級骨干模型ParC-Net。
論文作者認為,ViT和ConvNet有三個主要區別:ViT更擅長提取全局特征,采用meta-former結構,而且信息集成由數據驅動。ParC的設計思路便是從這三點著手來優化ConvNet。
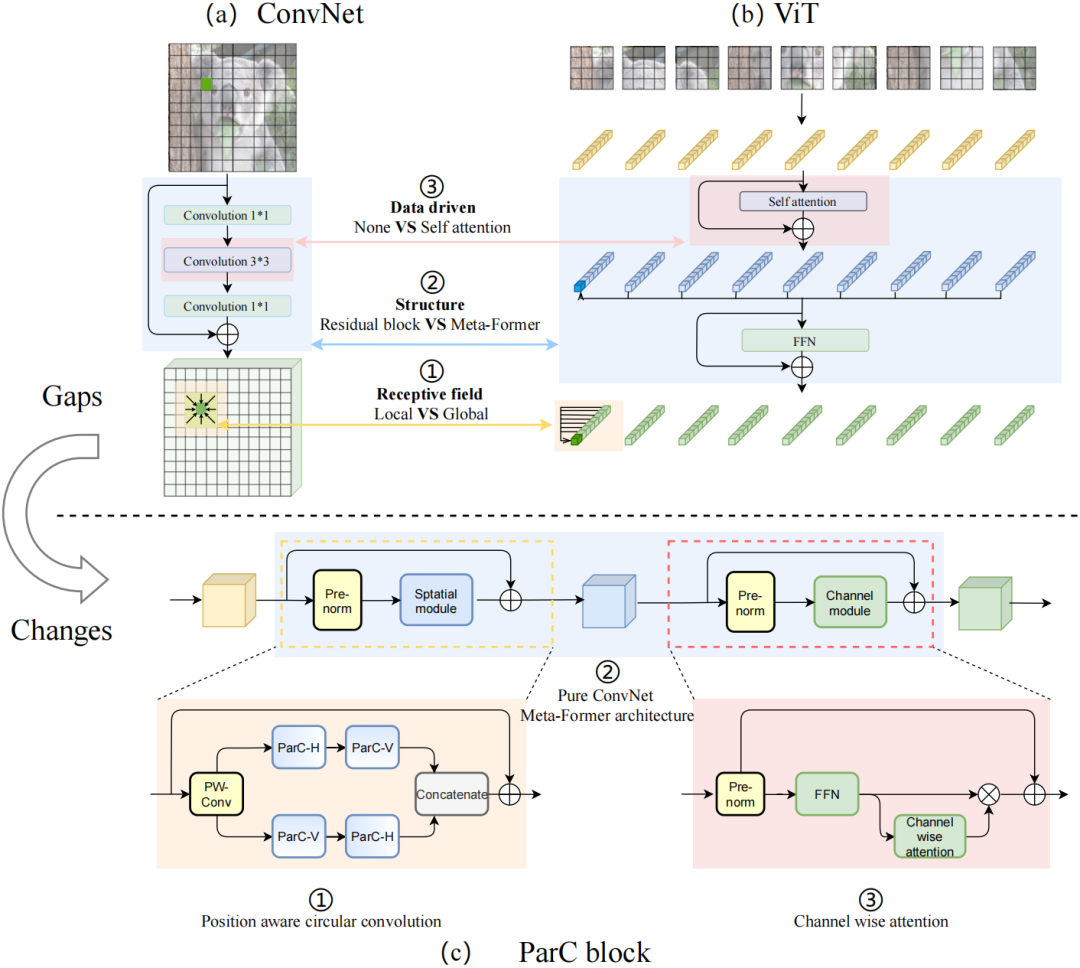
▲普通ConvNet和ViT之間的三個主要區別。(a) ConvNet常用的Residual block;(b) ViT中常用的Meta-Former 結構;(c) 本文提出的ParC block。
具體而言,研究人員設計了一種位置信息敏感的循環卷積(Position aware circular convolution, ParC)。這是一種簡單有效的輕量卷積運算算子,既擁有像ViT類結構的全局感受野,同時產生了像局部卷積那樣的位置敏感特征,能克服依賴自注意力結構提取全局特征的問題。
ParC結構主要包含三部分改動:1)結合circular padding和大感受野低秩分解卷積核提取全局特征;2)引入位置嵌入,保證輸出特征對于空間位置信息的敏感性;3)動態插值實時生成尺寸適配的卷積核和位置編碼,應對輸入分辨率變化情況,這增強了對不同尺寸輸入的適應能力。
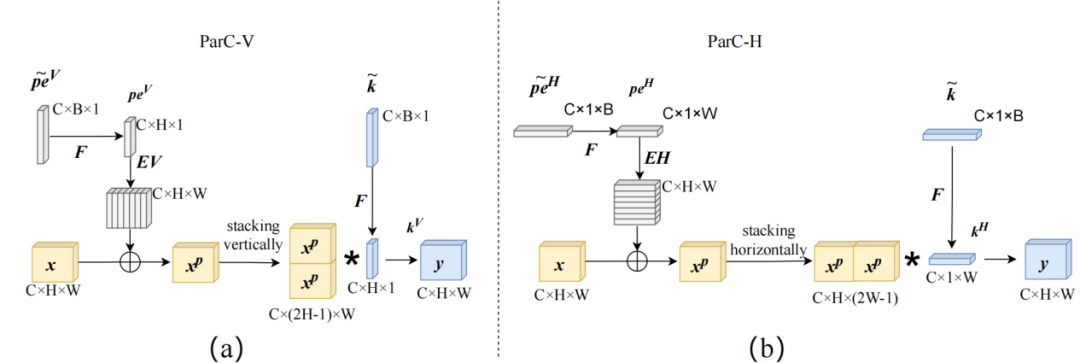
▲ParC結構示例
研究人員還將ParC和squeeze exictation(SE)操作結合起來,構建了一個純卷積結構的meta former結構。該結構舍棄了自注意力硬件支持不友好的操作,但保留了傳統Transformer塊提取全局特征的特點。
然后,研究人員在channel mixer部分引入硬件支持較友好的通道注意力機制,使其純卷積meta former結構也具備自注意力的特點。
基于ParC結構最終得到的ParC塊,可作為一個即插即用的基礎單元,替換現有ViT或ConvNet模型中的相關塊,從而提升精度,并降低計算成本,有效克服硬件支持的問題。
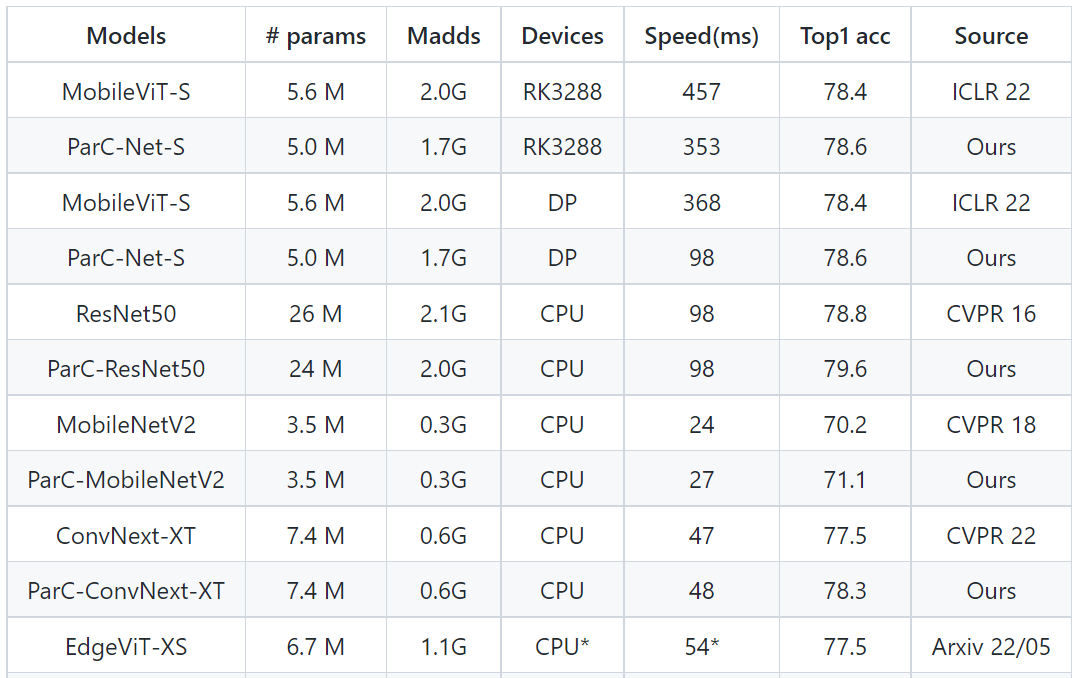
▲ParC實驗結果
02.
三大視覺任務表現出色 多項指標打敗蘋果MobileViT
“據我們所知,這是第一次嘗試結合ConvNet和ViT的優點來設計一個輕量級Pure-ConvNet的結構。”論文作者如此描述ParC-Net的開創性。
實驗結果表明,在圖像分類、物體檢測、語義分割這三類常見的視覺任務中,混合結構的模型性能表現普遍高于當前主流的一些純卷積結構、ViT結構的模型,其中ParC-Net模型取得了最好的整體性能表現。
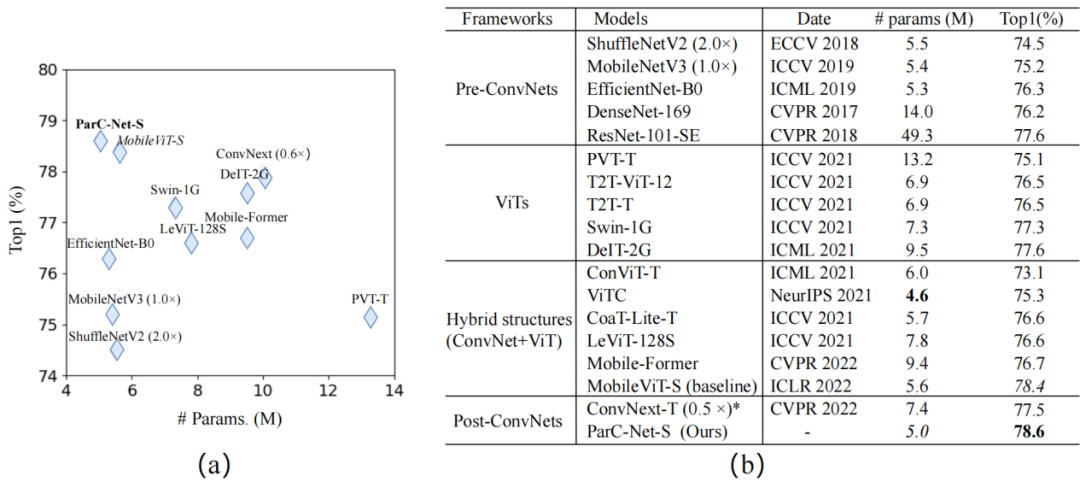
▲對于ImageNet-1k的圖像分類實驗結果
在圖像分類實驗中,對于ImageNet-1k的分類,ParC-Net使用的參數規模最小(大約500萬個參數),卻實現了最高準確率78.6%。
MobileViT是蘋果公司2022年在國際深度學習頂會ICLR22上提出的輕量級通用ViT模型。同樣部署在基于Arm的瑞芯微RK3288芯片上,相較基線模型MobileViT,ParC-Net節省了11%的參數和13%的計算成本,同時準確率提高了0.2%,推理速度提高了23%。

▲與基準模型的推理速度對比
與基于ViT結構的模型相比,ParC-Net的參數量只有Meta AI團隊DeiT模型參數的一半左右,準確率卻比DeiT提高了2.7%。
在MS-COCO物體檢測和PASCAL VOC分割任務中,ParC-Net同樣基于較少的參數,實現了更好的性能、更快的推理速度。
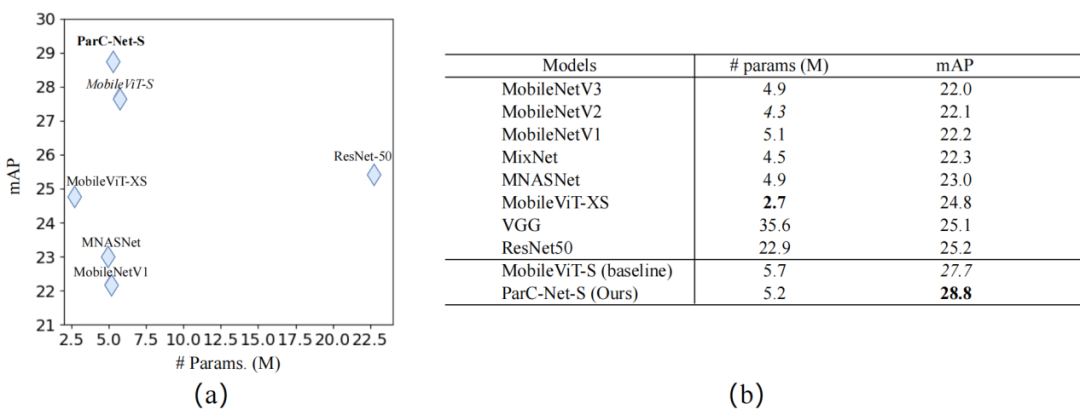
▲MS-COCO物體檢測實驗結果
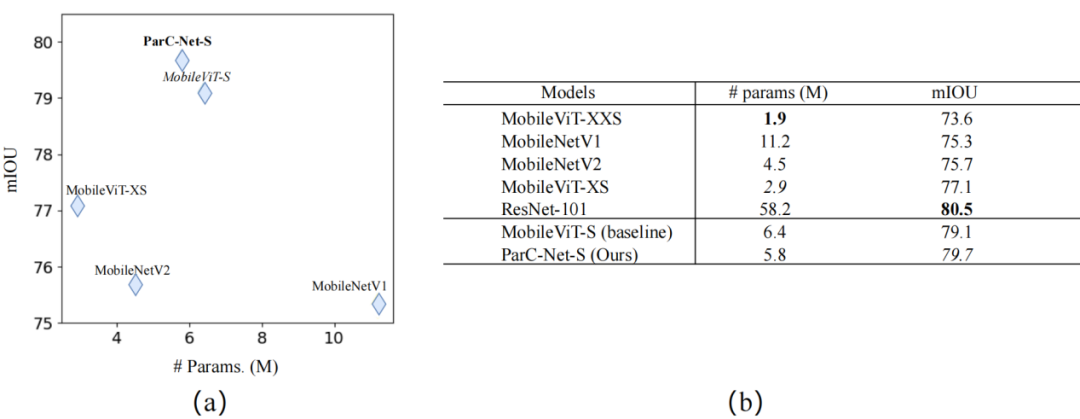
▲PASCAL VOC分割任務實驗結果
張號逵博士是ParC-Net論文的第一作者,現任深圳云天勵飛資深算法研究員,研究領域包括網絡結構搜索、深度估計、輕量化骨干模型、信息檢索及高光譜圖像分類等。
他告訴智東西,傳統ConvNet可以適應視覺任務中輸入分辨率的變化,而具有全局感受野的純卷積結構的缺陷是卷積核必須跟輸入分辨率保持一致,為了更好應對分辨率的變化,其團隊正在研究將模型做成動態卷積的形式,以提高魯棒性。
目前這項研究成果已經可以用在算力受限的移動端或邊緣設備中,實現更高準確率的視覺任務。如果進行一些小的改動,ParC-Net還可以被用于其他的視覺任務,例如6DOF姿態評估及其他dense prediction的任務。
03.
與自研芯片協同 運算速度可提升快3~4倍
那么ParC-Net模型的研究成果,具體如何在實際業務場景中發揮價值?
據介紹,一方面,ParC-Net模型可以集成到開源算法訓練平臺YMIR中,然后被部署至終端設備;另一方面,通過與云天勵飛自研芯片協同,它能將運算速度和精度進一步提升。
YMIR是一個高度自動化的AI模型開發平臺,能做到利用鼠標簡單操作就可以完成數據收集、模型訓練、數據挖掘、數據標注等功能。將擁有高運算效率的ParC-Net模型版本上傳至YMIR后,用戶可在該平臺上直接選用ParC-Net模型,也可以針對具體業務場景,添加相應的數據集對ParC-Net進行再訓練,從而獲得能更好滿足業務需求的模型。
以前有些對精度要求高或者采用ViT結構的移動端視覺任務,受限于計算效率問題,難以在攝像頭設備或手機上運行,而上傳到云端做運算,對有較高實時性要求的視覺任務不是很友好。
ParC-Net則較好地改善了這類問題,在模型精度和推理效率之間實現平衡,使得邊緣設備可以在本地運行一些對精度要求高的視覺任務。比如,人臉識別終端設備可運用ParC-Net直接對路過的人進行高質量特征值提取,無需將數據傳輸到云端,就能與數據庫進行檢索比對。
與云天勵飛自研芯片搭配后,ParC-Net模型的性能表現還能再上一個臺階。
張號逵博士談道,其團隊考慮到軟硬件設計協同問題,在研發之初參考了云天勵飛自研芯片工具鏈的設計及算子支持情況,然后進行模型網絡結構及算子的設計,以更好地發揮出芯片算力。
研究人員將ParC-Net和基線模型MobileVit均部署到自研低功耗芯片DP上進行推理速度測試。從實驗結果可以看到,ParC-Net的推理速度能夠達到MobileViT速度的3~4倍。

▲與基準模型在不同芯片平臺上的推理速度對比
這也是研究團隊決定選擇基于純卷積結構來設計ParC-Net的原因之一。ConvNet已經統治計算機視覺領域十年之久,而ViT在這一領域興起時間較短,很多現有的神經網絡加速器、硬件優化策略,都是圍繞卷積結構設計。因此部署在移動端時,純ConvNet往往能比ViT享有更好的軟硬件及工具鏈支持,并實現更快的推理速度。
即便搭載在對支持ViT更友好的芯片上,張號逵博士說,ParC-Net依然能取得比現有其他混合模型更好的性能表現。
絕大多數視覺任務可以分為兩類:一類對位置信息不敏感,如圖像分類等;另一類對位置信息較敏感,如物體檢測、3D姿態估計、AR試穿等。對于這些視覺任務,無論用在智能門禁、手機識圖還是自動駕駛汽車的攝像頭,ParC-Net都能夠發揮出其兼顧模型精度和計算效率的優勢,并且不會受部署終端設備配置的限制。
04.
結語:輕量級視覺模型設計的新啟發
當前ViT與ConvNet兩大研究方向在計算機視覺領域旗鼓相當,ViT在學術界四處屠榜,ConvNet則在工業界主導地位難以撼動,將兩者融合的相關研究也如雨后春筍般涌現。
此次入選ECCV頂會的ParC-Net模型,既顧及邊緣設備對模型規模的限制,基于純卷積結構,確保其具備易訓練、易部署、推理效率高、硬件更友好等特點,又吸納了ViT的設計特征,實現比其他ConvNet模型更高的精度。這可以給移動端視覺任務的模型設計帶來一些啟發。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107767 -
計算機視覺
+關注
關注
9文章
1715瀏覽量
47628 -
輕量級
+關注
關注
0文章
16瀏覽量
7581
原文標題:媒體關注丨云天勵飛論文入選ECCV2022,提出輕量級視覺模型新架構
文章出處:【微信號:IntelliFusion2,微信公眾號:云天勵飛】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
谷歌正式發布Gemma Scope 2模型
瑞芯微SOC智能視覺AI處理器
構建CNN網絡模型并優化的一般化建議
【新品上線】AI 智能視覺核心板:CORE-1126BJD4

【CW32】uart_obj_fw 輕量級串口框架
全新輕量級ViSTA-SLAM系統介紹
Crypto核心庫:顛覆傳統的數據安全輕量級加密方案
基于米爾瑞芯微RK3576開發板部署運行TinyMaix:超輕量級推理框架
如何在RK3576開發板上運行TinyMaix :超輕量級推理框架--基于米爾MYD-LR3576開發板

輕量級≠低效能:RK3506J核心板如何用性價比感動用戶?

成本狂降90%!國產芯片+開源模型如何改寫AI玩具規則
如何使用Docker部署大模型
樹莓派替代臺式計算機?樹莓派上七款最佳的輕量級操作系統!

?VLM(視覺語言模型)?詳細解析




 工商網監
工商網監
評論