") 序列數(shù)據(jù)和文本的深度學(xué)習(xí)
序列數(shù)據(jù)和文本的深度學(xué)習(xí)

?用于構(gòu)建深度學(xué)習(xí)模型的不同文本數(shù)據(jù)表示法:
?理解遞歸神經(jīng)網(wǎng)絡(luò)及其不同實(shí)現(xiàn),例如長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)和門控循環(huán)單元(Gated Recurrent Unit,GRU),它們?yōu)榇蠖鄶?shù)深度學(xué)習(xí)模型提供文本和序列化數(shù)據(jù);
?為序列化數(shù)據(jù)使用一維卷積。
可以使用RNN構(gòu)建的一些應(yīng)用程序如下所示。
?文檔分類器:識(shí)別推文或評(píng)論的情感,對(duì)新聞文章進(jìn)行分類。
?序列到序列的學(xué)習(xí):例如語(yǔ)言翻譯,將英語(yǔ)轉(zhuǎn)換成法語(yǔ)等任務(wù)。
?時(shí)間序列預(yù)測(cè):根據(jù)前幾天商店銷售的詳細(xì)信息,預(yù)測(cè)商店未來(lái)的銷售情況。
1使用文本數(shù)據(jù)
文本是常用的序列化數(shù)據(jù)類型之一。文本數(shù)據(jù)可以看作是一個(gè)字符序列或詞的序列。對(duì)大多數(shù)問(wèn)題,我們都將文本看作詞序列。深度學(xué)習(xí)序列模型(如RNN及其變體)能夠從文本數(shù)據(jù)中學(xué)習(xí)重要的模式。這些模式可以解決類似以下領(lǐng)域中的問(wèn)題:
?自然語(yǔ)言理解;
?文獻(xiàn)分類;
?情感分類。
這些序列模型還可以作為各種系統(tǒng)的重要構(gòu)建塊,例如問(wèn)答(Question and Answering,QA)系統(tǒng)。
雖然這些模型在構(gòu)建這些應(yīng)用時(shí)非常有用,但由于語(yǔ)言固有的復(fù)雜性,模型并不能真正理解人類的語(yǔ)言。這些序列模型能夠成功地找到可執(zhí)行不同任務(wù)的有用模式。將深度學(xué)習(xí)應(yīng)用于文本是一個(gè)快速發(fā)展的領(lǐng)域,每月都會(huì)有許多新技術(shù)出現(xiàn)。我們將會(huì)介紹為大多數(shù)現(xiàn)代深度學(xué)習(xí)應(yīng)用提供支持的基本組件。
與其他機(jī)器學(xué)習(xí)模型一樣,深度學(xué)習(xí)模型并不能理解文本,因此需要將文本轉(zhuǎn)換為數(shù)值的表示形式。將文本轉(zhuǎn)換為數(shù)值表示形式的過(guò)程稱為向量化過(guò)程,可以用不同的方式來(lái)完成,概括如下:
?將文本轉(zhuǎn)換為詞并將每個(gè)詞表示為向量;
?將文本轉(zhuǎn)換為字符并將每個(gè)字符表示為向量;
?創(chuàng)建詞的n-gram并將其表示為向量。
文本數(shù)據(jù)可以分解成上述的這些表示。每個(gè)較小的文本單元稱為token,將文本分解成token的過(guò)程稱為分詞(tokenization)。在Python中有很多強(qiáng)大的庫(kù)可以用來(lái)進(jìn)行分詞。一旦將文本數(shù)據(jù)轉(zhuǎn)換為token序列,那么就需要將每個(gè)token映射到向量。one-hot(獨(dú)熱)編碼和詞向量是將token映射到向量最流行的兩種方法。圖6.1總結(jié)了將文本轉(zhuǎn)換為向量表示的步驟。
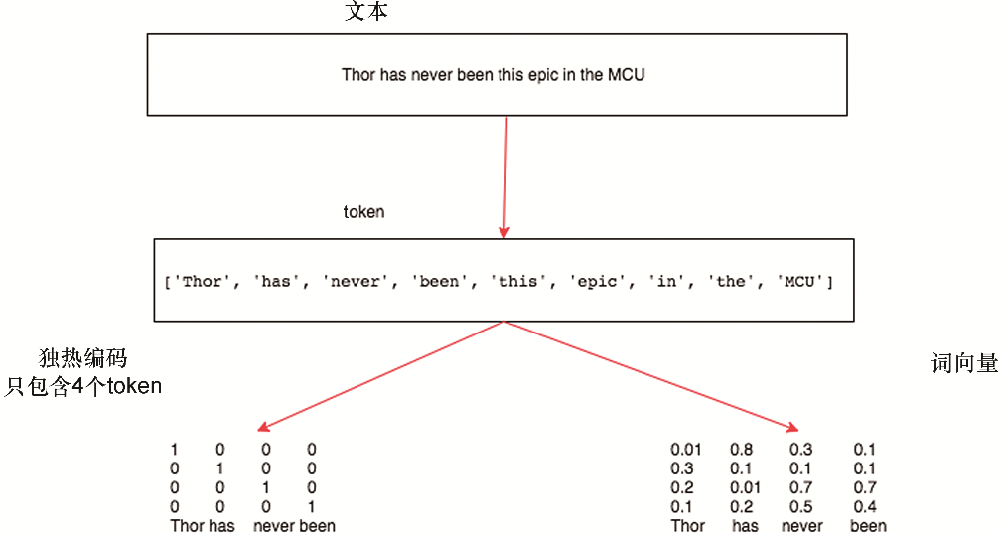
圖6.1
下面介紹分詞、n-gram表示法和向量化的更多細(xì)節(jié)。
6.1.1分詞
將給定的一個(gè)句子分為字符或詞的過(guò)程稱為分詞。諸如spaCy等一些庫(kù),它們?yōu)榉衷~提供了復(fù)雜的解決方案。讓我們使用簡(jiǎn)單的Python函數(shù)(如split和list)將文本轉(zhuǎn)換為token。
為了演示分詞如何作用于字符和詞,讓我們看一段關(guān)于電影Thor:Ragnarok的小評(píng)論。我們將對(duì)這段文本進(jìn)行分詞處理:
The action scenes were top notch in this movie. Thor has never been this epic in the MCU.He does some pretty epic sh*t in this movie and he is definitely not under-powered anymore.Thor in unleashed in this, I love that.
1.將文本轉(zhuǎn)換為字符
Python的list函數(shù)接受一個(gè)字符串并將其轉(zhuǎn)換為單個(gè)字符的列表。這樣做就將文本轉(zhuǎn)換為了字符。下面是使用的代碼和結(jié)果:
以下是結(jié)果:
結(jié)果展示了簡(jiǎn)單的Python函數(shù)如何將文本轉(zhuǎn)換為token。
2.將文本轉(zhuǎn)換為詞
我們將使用Python字符串對(duì)象函數(shù)中的split函數(shù)將文本分解為詞。split函數(shù)接受一個(gè)參數(shù),并根據(jù)該參數(shù)將文本拆分為token。在我們的示例中將使用空格作為分隔符。以下代碼段演示了如何使用Python的split函數(shù)將文本轉(zhuǎn)換為詞:
在前面的代碼中,我們沒(méi)有使用任何的分隔符,默認(rèn)情況下,split函數(shù)使用空格來(lái)分隔。
3.n-gram表示法
我們已經(jīng)看到文本是如何表示為字符和詞的。有時(shí)一起查看兩個(gè)、三個(gè)或更多的單詞非常有用。n-gram是從給定文本中提取的一組詞。在n-gram中,n表示可以一起使用的詞的數(shù)量。看一下bigram(當(dāng)n= 2時(shí))的例子,我們使用Python的nltk包為thor_review生成一個(gè)bigram,以下代碼塊顯示了bigram的結(jié)果以及用于生成它的代碼:
ngrams函數(shù)接受一個(gè)詞序列作為第一個(gè)參數(shù),并將組中詞的個(gè)數(shù)作為第二個(gè)參數(shù)。以下代碼塊顯示了trigram表示的結(jié)果以及用于實(shí)現(xiàn)它的代碼:
在上述代碼中唯一改變的只有函數(shù)的第二個(gè)參數(shù)n的值。
許多有監(jiān)督的機(jī)器學(xué)習(xí)模型,例如樸素貝葉斯(Naive Bayes),都是使用n-gram來(lái)改善它的特征空間。n-gram同樣也可用于拼寫校正和文本摘要的任務(wù)。
n-gram表示法的一個(gè)問(wèn)題在于它失去了文本的順序性。通常它是和淺層機(jī)器學(xué)習(xí)模型一起使用的。這種技術(shù)很少用于深度學(xué)習(xí),因?yàn)镽NN和Conv1D等架構(gòu)會(huì)自動(dòng)學(xué)習(xí)這些表示法。
6.1.2向量化
將生成的token映射到數(shù)字向量有兩種流行的方法,稱為獨(dú)熱編碼和詞向量(word embedding,也稱之為詞嵌入)。讓我們通過(guò)編寫一個(gè)簡(jiǎn)單的Python程序來(lái)理解如何將token轉(zhuǎn)換為這些向量表示。我們還將討論每種方法的各種優(yōu)缺點(diǎn)。
1.獨(dú)熱編碼
在獨(dú)熱編碼中,每個(gè)token都由長(zhǎng)度為N的向量表示,其中N是詞表的大小。詞表是文檔中唯一詞的總數(shù)。讓我們用一個(gè)簡(jiǎn)單的句子來(lái)觀察每個(gè)token是如何表示為獨(dú)熱編碼的向量的。下面是句子及其相關(guān)的token表示:
An apple a day keeps doctor away said the doctor.
上面句子的獨(dú)熱編碼可以用表格形式進(jìn)行表示,如下所示。
An 100000000
apple 010000000
a 001000000
day 000100000
keeps 000010000
doctor 000001000
away 000000100
said 000000010
the 000000001
該表描述了token及其獨(dú)熱編碼的表示。因?yàn)榫渥又杏?個(gè)唯一的單詞,所以這里的向量長(zhǎng)度為9。許多機(jī)器學(xué)習(xí)庫(kù)已經(jīng)簡(jiǎn)化了創(chuàng)建獨(dú)熱編碼變量的過(guò)程。我們將編寫自己的代碼來(lái)實(shí)現(xiàn)這個(gè)過(guò)程以便更易于理解,并且我們可以使用相同的實(shí)現(xiàn)來(lái)構(gòu)建后續(xù)示例所需的其他功能。以下代碼包含Dictionary類,這個(gè)類包含了創(chuàng)建唯一詞詞表的功能,以及為特定詞返回其獨(dú)熱編碼向量的函數(shù)。讓我們來(lái)看代碼,然后詳解每個(gè)功能:
上述代碼提供了3個(gè)重要功能。
?初始化函數(shù)__init__創(chuàng)建一個(gè)word2idx字典,它將所有唯一詞與索引一起存儲(chǔ)。idx2word列表存儲(chǔ)的是所有唯一詞,而length變量則是文檔中唯一詞的總數(shù)。
?在詞是唯一的前提下,add_word函數(shù)接受一個(gè)單詞,并將它添加到word2idx和idx2word中,同時(shí)增加詞表的長(zhǎng)度。
?onehot_encoded函數(shù)接受一個(gè)詞并返回一個(gè)長(zhǎng)度為N,除當(dāng)前詞的索引外其余位置全為0的向量。比如傳如的單詞的索引是2,那么向量在索引2處的值是1,其他索引處的值全為0。
在定義好了Dictionary類后,準(zhǔn)備在thor_review數(shù)據(jù)上使用它。以下代碼演示了如何構(gòu)建word2idx以及如何調(diào)用onehot_encoded函數(shù):
上述代碼的輸出如下:
單詞were的獨(dú)熱編碼如下所示:
獨(dú)熱表示的問(wèn)題之一就是數(shù)據(jù)太稀疏了,并且隨著詞表中唯一詞數(shù)量的增加,向量的大小迅速增加,這也是它的一種限制,因此獨(dú)熱很少在深度學(xué)習(xí)中使用。
2.詞向量
詞向量是在深度學(xué)習(xí)算法所解決的問(wèn)題中,一種非常流行的用于表示文本數(shù)據(jù)的方式。詞向量提供了一種用浮點(diǎn)數(shù)填充的詞的密集表示。向量的維度根據(jù)詞表的大小而變化。通常使用維度大小為50、100、256、300,有時(shí)為1000的詞向量。這里的維度大小是在訓(xùn)練階段需要使用的超參數(shù)。
如果試圖用獨(dú)熱表示法來(lái)表示大小為20000的詞表,那么將得到20000×20000個(gè)數(shù)字,并且其中大部分都為0。同樣的詞表可以用詞向量表示為20000×維度大小,其中維度的大小可以是10、50、300等。
一種方法是為每個(gè)包含隨機(jī)數(shù)字的token從密集向量開始創(chuàng)建詞向量,然后訓(xùn)練諸如文檔分類器或情感分類器的模型。表示token的浮點(diǎn)數(shù)以一種可以使語(yǔ)義上更接近的單詞具有相似表示的方式進(jìn)行調(diào)整。為了理解這一點(diǎn),我們來(lái)看看圖6.2,它畫出了基于5部電影的二維點(diǎn)圖的詞向量。

圖6.2
圖6.2顯示了如何調(diào)整密集向量,以使其在語(yǔ)義上相似的單詞具有較小的距離。由于Superman、Thor和Batman等電影都是基于漫畫的動(dòng)作電影,所以這些電影的向量更為接近,而電影Titanic的向量離動(dòng)作電影較遠(yuǎn),離電影Notebook更近,因?yàn)樗鼈兌际抢寺碗娪啊?br />
在數(shù)據(jù)太少時(shí)學(xué)習(xí)詞向量可能是行不通的,在這種情況下,可以使用由其他機(jī)器學(xué)習(xí)算法訓(xùn)練好的詞向量。由另一個(gè)任務(wù)生成的向量稱為預(yù)訓(xùn)練詞向量。下面將學(xué)習(xí)如何構(gòu)建自己的詞向量以及使用預(yù)訓(xùn)練詞向量。
審核編輯 黃昊宇
-
序列
+關(guān)注
關(guān)注
0文章
70瀏覽量
20207 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5598瀏覽量
124396
發(fā)布評(píng)論請(qǐng)先 登錄
深度解析DS1830/A復(fù)位序列器:特性、操作與應(yīng)用
自然語(yǔ)言處理NLP的概念和工作原理

機(jī)器學(xué)習(xí)和深度學(xué)習(xí)中需避免的 7 個(gè)常見(jiàn)錯(cuò)誤與局限性

穿孔機(jī)頂頭檢測(cè)儀 機(jī)器視覺(jué)深度學(xué)習(xí)
一文讀懂LSTM與RNN:從原理到實(shí)戰(zhàn),掌握序列建模核心技術(shù)

如何深度學(xué)習(xí)機(jī)器視覺(jué)的應(yīng)用場(chǎng)景

如何實(shí)現(xiàn)"可用匿名數(shù)據(jù)"# AI# 人工智能# 隱私保護(hù)# 圖像處理# 黑科技# 安全 #深度學(xué)習(xí) #數(shù)據(jù)
如何在機(jī)器視覺(jué)中部署深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)

深度學(xué)習(xí)對(duì)工業(yè)物聯(lián)網(wǎng)有哪些幫助
自動(dòng)駕駛中Transformer大模型會(huì)取代深度學(xué)習(xí)嗎?

飛書開源“RTV”富文本組件 重塑鴻蒙應(yīng)用富文本渲染體驗(yàn)
提高IT運(yùn)維效率,深度解讀京東云AIOps落地實(shí)踐(異常檢測(cè)篇)
嵌入式AI技術(shù)之深度學(xué)習(xí):數(shù)據(jù)樣本預(yù)處理過(guò)程中使用合適的特征變換對(duì)深度學(xué)習(xí)的意義
把樹莓派打造成識(shí)別文本的“神器”!




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論