") 試圖打破CUDA統(tǒng)治的SYCL
試圖打破CUDA統(tǒng)治的SYCL

各式各樣的加速器在當(dāng)下的計(jì)算架構(gòu)中越來越普遍,HPC、數(shù)據(jù)中心等高端應(yīng)用開始追求更高的峰值性能,用到了專業(yè)GPU、AI加速器,而手機(jī)、嵌入式系統(tǒng)開始追求更高的能效,也在其SoC、MCU中加入一定的嵌入式加速硬件。但與此同時(shí),這樣復(fù)雜的多廠商、多架構(gòu)和多硬件生態(tài),為編程帶來了巨大的難題。但CUDA作為只面向英偉達(dá)GPU的封閉軟件生態(tài),其熱度卻水漲船高。
 ?
?
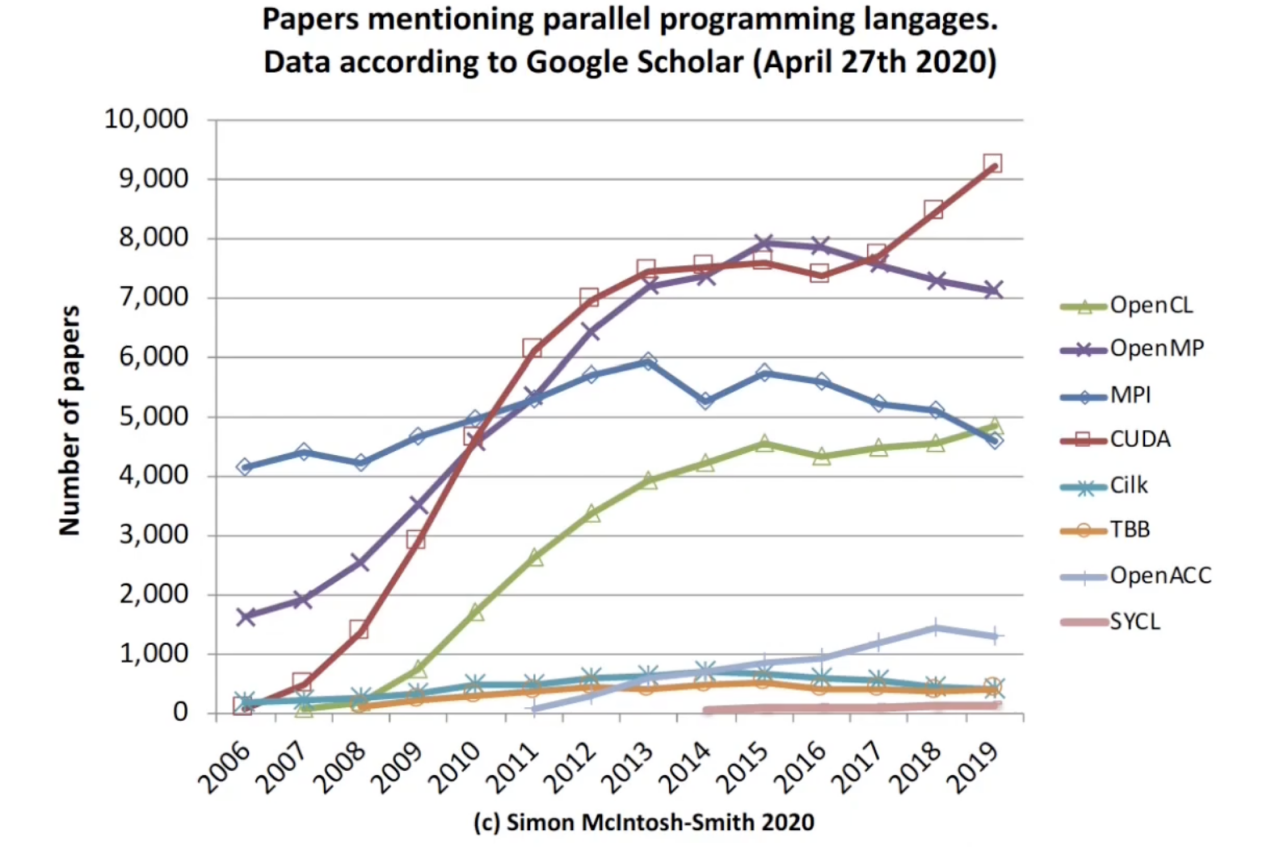
提及各大編程語言的論文數(shù)量/ 谷歌學(xué)術(shù)
在軟件開發(fā)中,一個(gè)開放的標(biāo)準(zhǔn)層就是開發(fā)者產(chǎn)品方案的接口規(guī)范,同樣的,處理器開發(fā)商們可以使用基于開放標(biāo)準(zhǔn)層的底層軟件驅(qū)動(dòng)創(chuàng)造解決方案。如此一來軟件開發(fā)者們無需捆綁在特定的硬件方案上,硬件開發(fā)者的硬件不僅可以兼顧自己維護(hù)的軟件,還能支持到更多的軟件開發(fā)人員。而且在普及之后,開發(fā)人員的技能更加具有普適性,他們可以方便地使用自己熟悉的開發(fā)工具。
對(duì)使用開放標(biāo)準(zhǔn)的軟硬件公司來說,此舉可以加快產(chǎn)品上市時(shí)間,減少長(zhǎng)期維護(hù)工作,而且在軟件方案廠商日益劇增的當(dāng)下,業(yè)界已經(jīng)普遍接受了開放標(biāo)準(zhǔn),就像RISC-V一樣,英特爾、AMD甚至是英偉達(dá)也都對(duì)開放標(biāo)準(zhǔn)的定義做出了貢獻(xiàn),對(duì)于一些初創(chuàng)企業(yè)來說就更是如此了。
SYCL出世
從市場(chǎng)反饋來看,開發(fā)者的需求很明顯了,他們想要一個(gè)標(biāo)準(zhǔn)的編程模型,擁有標(biāo)準(zhǔn)運(yùn)算庫(kù)、對(duì)Pytorch、Tensorflow等AI框架的支持、性能分析工具,以及對(duì)多個(gè)廠商不同硬件架構(gòu)的支持,而這些需求匯聚在一起,使得開放標(biāo)準(zhǔn)聯(lián)盟Khronos Group聯(lián)合旗下成員打造出了SYCL這一編程語言。
SYCL作為跨越CPU、GPU、FPGA和AI加速器等多種架構(gòu)的一致性編程語言,每個(gè)架構(gòu)能單獨(dú)或整合編程。SYCL編程語言與其API擴(kuò)展能用于不同的開發(fā)用例,比如負(fù)載加速或異構(gòu)計(jì)算應(yīng)用,將現(xiàn)有的C、C++或其他加速器語言代碼轉(zhuǎn)換成SYCL代碼。
 ?
?
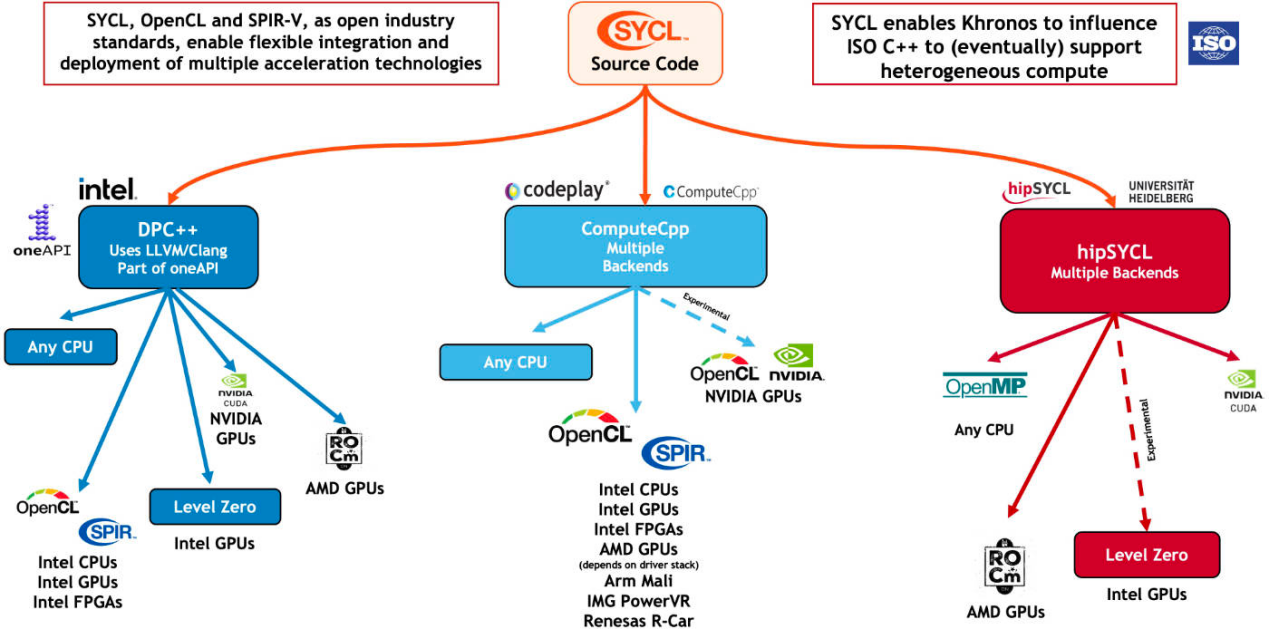
SYCL的支持情況/ Khronos Group
在不同廠商的支持下,SYCL的實(shí)施方式有多種,他們?cè)黾恿藢?duì)OpenCL以外不同加速API后端的支持,比如Codeplay的ComputeCpp、英特爾的DPC++、AMD的hipSYCL以及Xilinx的triSYCL等。
英特爾的SYCL之路
英特爾對(duì)于SYCL的重視可以說顯而易見了,自從宣布轉(zhuǎn)向XPU+oneAPI的路線之后,英特爾就已經(jīng)與SYCL深度綁定了。不僅微軟、谷歌等巨頭宣布支持oneAPI,英特爾也和中科院計(jì)算所在內(nèi)的大型研究所、國(guó)家實(shí)驗(yàn)室和大學(xué)合作成立了oneAPI卓越中心,借助他們的oneAPI開源代碼,進(jìn)一步擴(kuò)展oneAPI產(chǎn)品與規(guī)范。
oneAPI的核心則是其編程語言DPC++,英特爾的DPC++可以說是SYCL的超集,不僅包含了SYCL標(biāo)準(zhǔn),還包含一些功能擴(kuò)展,比如統(tǒng)一共享內(nèi)存等,不過目前其中不少擴(kuò)展也已經(jīng)并入了SYCL新版規(guī)范中。
不過SYCL遠(yuǎn)不僅是為了方便英特爾建設(shè)其跨架構(gòu)的軟件生態(tài),而是為了打破CUDA的統(tǒng)治,打造一個(gè)更加開放的軟硬件生態(tài),這點(diǎn)從英特爾在oneAPI的開發(fā)動(dòng)向就能看出。
此前英特爾對(duì)于CUDA并沒有任何動(dòng)作,反倒是其競(jìng)爭(zhēng)對(duì)手AMD推出了HIP,幫助開發(fā)者將CUDA代碼移植至AMD平臺(tái)上,畢竟AMD還得發(fā)展GPU生態(tài)。但隨著英特爾的硬件路線已經(jīng)不單單是CPU,而是CPU、GPU、FPGA、IPU和AI加速器的多硬件異構(gòu)生態(tài),這時(shí)候打造一個(gè)CUDA之外的軟件生態(tài)是提升其產(chǎn)品競(jìng)爭(zhēng)力的必經(jīng)之路了。
為了更好實(shí)現(xiàn)對(duì)CUDA代碼的移植,英特爾推出了DPC++兼容性工具(DPCT),目前版本的DPCT已經(jīng)可以將90%到95%的CUDA代碼轉(zhuǎn)換成SYCL。不過這只是一個(gè)理想范圍,具體數(shù)值還是取決于代碼對(duì)應(yīng)的工作負(fù)載。對(duì)于簡(jiǎn)單的CUDA程序來說,完成DPC++的移植只需要對(duì)CUDA源文件運(yùn)行這一轉(zhuǎn)換工具即可,相對(duì)復(fù)雜的CUDA程序還是需要一定的手動(dòng)編程優(yōu)化。
今年6月,英特爾公布消息,決定收購(gòu)Codeplay公司。要說對(duì)SYCL的研究,除了英特爾以外,最深入的當(dāng)屬Codeplay了,畢竟就連SYCL工作組的主席也是來自Codeplay的杰出工程師MichaelWong。Codeplay不僅提供了多種處理器上SYCL的支持,也支持將CUDA代碼移植為SYCL,同時(shí)保證SYCL代碼在英偉達(dá)GPU上的繼續(xù)運(yùn)行,還能調(diào)用一些CUDA庫(kù)。
Codeplay的方案支持覆蓋英特爾、AMD、英偉達(dá)的處理器,而且他們也開始了對(duì)汽車ADAS(瑞薩R-Car)、邊緣計(jì)算設(shè)備(ImaginationPowerVR)與RISC-V處理器(晶心科技NX27V)的支持開發(fā)工作。后三者恰好是SYCL當(dāng)前未曾開拓的市場(chǎng),但卻是英特爾正在發(fā)力的三大市場(chǎng),加上Codeplay本身在HPC、AI上的軟件開發(fā)實(shí)力,如此看來,英特爾收購(gòu)Codeplay完全符合其戰(zhàn)略目標(biāo)。
結(jié)語
盡管SYCL的構(gòu)想是好的,其發(fā)展路線也是傾向于開發(fā)者,但這并不代表著就一定能取代CUDA的位置,畢竟SYCL其實(shí)也才誕生沒多久,與CUDA、OpenCL或OpenMP相比生態(tài)發(fā)展還沒有成熟。再者就是統(tǒng)一各種硬件的編程并沒有那么簡(jiǎn)單,正如英偉達(dá)CEO黃仁勛曾經(jīng)提出的質(zhì)疑:時(shí)間會(huì)揭曉一個(gè)編程方法是否能兼容七種不同的處理器,至少歷史上從未出現(xiàn)過。
?提及各大編程語言的論文數(shù)量/ 谷歌學(xué)術(shù)
在軟件開發(fā)中,一個(gè)開放的標(biāo)準(zhǔn)層就是開發(fā)者產(chǎn)品方案的接口規(guī)范,同樣的,處理器開發(fā)商們可以使用基于開放標(biāo)準(zhǔn)層的底層軟件驅(qū)動(dòng)創(chuàng)造解決方案。如此一來軟件開發(fā)者們無需捆綁在特定的硬件方案上,硬件開發(fā)者的硬件不僅可以兼顧自己維護(hù)的軟件,還能支持到更多的軟件開發(fā)人員。而且在普及之后,開發(fā)人員的技能更加具有普適性,他們可以方便地使用自己熟悉的開發(fā)工具。
對(duì)使用開放標(biāo)準(zhǔn)的軟硬件公司來說,此舉可以加快產(chǎn)品上市時(shí)間,減少長(zhǎng)期維護(hù)工作,而且在軟件方案廠商日益劇增的當(dāng)下,業(yè)界已經(jīng)普遍接受了開放標(biāo)準(zhǔn),就像RISC-V一樣,英特爾、AMD甚至是英偉達(dá)也都對(duì)開放標(biāo)準(zhǔn)的定義做出了貢獻(xiàn),對(duì)于一些初創(chuàng)企業(yè)來說就更是如此了。
SYCL出世
從市場(chǎng)反饋來看,開發(fā)者的需求很明顯了,他們想要一個(gè)標(biāo)準(zhǔn)的編程模型,擁有標(biāo)準(zhǔn)運(yùn)算庫(kù)、對(duì)Pytorch、Tensorflow等AI框架的支持、性能分析工具,以及對(duì)多個(gè)廠商不同硬件架構(gòu)的支持,而這些需求匯聚在一起,使得開放標(biāo)準(zhǔn)聯(lián)盟Khronos Group聯(lián)合旗下成員打造出了SYCL這一編程語言。
SYCL作為跨越CPU、GPU、FPGA和AI加速器等多種架構(gòu)的一致性編程語言,每個(gè)架構(gòu)能單獨(dú)或整合編程。SYCL編程語言與其API擴(kuò)展能用于不同的開發(fā)用例,比如負(fù)載加速或異構(gòu)計(jì)算應(yīng)用,將現(xiàn)有的C、C++或其他加速器語言代碼轉(zhuǎn)換成SYCL代碼。
?SYCL的支持情況/ Khronos Group
英特爾的SYCL之路
英特爾對(duì)于SYCL的重視可以說顯而易見了,自從宣布轉(zhuǎn)向XPU+oneAPI的路線之后,英特爾就已經(jīng)與SYCL深度綁定了。不僅微軟、谷歌等巨頭宣布支持oneAPI,英特爾也和中科院計(jì)算所在內(nèi)的大型研究所、國(guó)家實(shí)驗(yàn)室和大學(xué)合作成立了oneAPI卓越中心,借助他們的oneAPI開源代碼,進(jìn)一步擴(kuò)展oneAPI產(chǎn)品與規(guī)范。
oneAPI的核心則是其編程語言DPC++,英特爾的DPC++可以說是SYCL的超集,不僅包含了SYCL標(biāo)準(zhǔn),還包含一些功能擴(kuò)展,比如統(tǒng)一共享內(nèi)存等,不過目前其中不少擴(kuò)展也已經(jīng)并入了SYCL新版規(guī)范中。
不過SYCL遠(yuǎn)不僅是為了方便英特爾建設(shè)其跨架構(gòu)的軟件生態(tài),而是為了打破CUDA的統(tǒng)治,打造一個(gè)更加開放的軟硬件生態(tài),這點(diǎn)從英特爾在oneAPI的開發(fā)動(dòng)向就能看出。
此前英特爾對(duì)于CUDA并沒有任何動(dòng)作,反倒是其競(jìng)爭(zhēng)對(duì)手AMD推出了HIP,幫助開發(fā)者將CUDA代碼移植至AMD平臺(tái)上,畢竟AMD還得發(fā)展GPU生態(tài)。但隨著英特爾的硬件路線已經(jīng)不單單是CPU,而是CPU、GPU、FPGA、IPU和AI加速器的多硬件異構(gòu)生態(tài),這時(shí)候打造一個(gè)CUDA之外的軟件生態(tài)是提升其產(chǎn)品競(jìng)爭(zhēng)力的必經(jīng)之路了。
為了更好實(shí)現(xiàn)對(duì)CUDA代碼的移植,英特爾推出了DPC++兼容性工具(DPCT),目前版本的DPCT已經(jīng)可以將90%到95%的CUDA代碼轉(zhuǎn)換成SYCL。不過這只是一個(gè)理想范圍,具體數(shù)值還是取決于代碼對(duì)應(yīng)的工作負(fù)載。對(duì)于簡(jiǎn)單的CUDA程序來說,完成DPC++的移植只需要對(duì)CUDA源文件運(yùn)行這一轉(zhuǎn)換工具即可,相對(duì)復(fù)雜的CUDA程序還是需要一定的手動(dòng)編程優(yōu)化。
今年6月,英特爾公布消息,決定收購(gòu)Codeplay公司。要說對(duì)SYCL的研究,除了英特爾以外,最深入的當(dāng)屬Codeplay了,畢竟就連SYCL工作組的主席也是來自Codeplay的杰出工程師MichaelWong。Codeplay不僅提供了多種處理器上SYCL的支持,也支持將CUDA代碼移植為SYCL,同時(shí)保證SYCL代碼在英偉達(dá)GPU上的繼續(xù)運(yùn)行,還能調(diào)用一些CUDA庫(kù)。
Codeplay的方案支持覆蓋英特爾、AMD、英偉達(dá)的處理器,而且他們也開始了對(duì)汽車ADAS(瑞薩R-Car)、邊緣計(jì)算設(shè)備(ImaginationPowerVR)與RISC-V處理器(晶心科技NX27V)的支持開發(fā)工作。后三者恰好是SYCL當(dāng)前未曾開拓的市場(chǎng),但卻是英特爾正在發(fā)力的三大市場(chǎng),加上Codeplay本身在HPC、AI上的軟件開發(fā)實(shí)力,如此看來,英特爾收購(gòu)Codeplay完全符合其戰(zhàn)略目標(biāo)。
結(jié)語
盡管SYCL的構(gòu)想是好的,其發(fā)展路線也是傾向于開發(fā)者,但這并不代表著就一定能取代CUDA的位置,畢竟SYCL其實(shí)也才誕生沒多久,與CUDA、OpenCL或OpenMP相比生態(tài)發(fā)展還沒有成熟。再者就是統(tǒng)一各種硬件的編程并沒有那么簡(jiǎn)單,正如英偉達(dá)CEO黃仁勛曾經(jīng)提出的質(zhì)疑:時(shí)間會(huì)揭曉一個(gè)編程方法是否能兼容七種不同的處理器,至少歷史上從未出現(xiàn)過。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
amd
+關(guān)注
關(guān)注
25文章
5684瀏覽量
139992 -
英特爾
+關(guān)注
關(guān)注
61文章
10301瀏覽量
180480 -
英偉達(dá)
+關(guān)注
關(guān)注
23文章
4087瀏覽量
99200
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
RV生態(tài)又一里程碑:英偉達(dá)官宣CUDA將兼容RISC-V架構(gòu)!
電子發(fā)燒友網(wǎng)報(bào)道(文/梁浩斌)英偉達(dá)生態(tài)護(hù)城河CUDA,從最初支持x86、Power?CPU架構(gòu),到2019年宣布支持Arm?CPU,不斷拓展在數(shù)據(jù)中心的應(yīng)用生態(tài)。 在2019年至今的六年
借助NVIDIA CUDA Tile IR后端推進(jìn)OpenAI Triton的GPU編程
NVIDIA CUDA Tile 是基于 GPU 的編程模型,其設(shè)計(jì)目標(biāo)是為 NVIDIA Tensor Cores 提供可移植性,從而釋放 GPU 的極限性能。CUDA Tile 的一大優(yōu)勢(shì)是允許開發(fā)者基于其構(gòu)建自定義的 DSL。
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法
本博文是系列課程的一部分,旨在幫助開發(fā)者學(xué)習(xí) NVIDIA CUDA Tile 編程,掌握構(gòu)建高性能 GPU 內(nèi)核的方法,并以矩陣乘法作為核心示例。

NVIDIA CUDA Tile的創(chuàng)新之處、工作原理以及使用方法
NVIDIA CUDA 13.1 推出 NVIDIA CUDA Tile,這是自 2006 年 NVIDIA CUDA 平臺(tái)發(fā)明以來,最大的一次技術(shù)進(jìn)步。這一令人振奮的創(chuàng)新引入了一套面向

在Python中借助NVIDIA CUDA Tile簡(jiǎn)化GPU編程
NVIDIA CUDA 13.1 版本新增了基于 Tile 的GPU 編程模式。它是自 CUDA 發(fā)明以來 GPU 編程最核心的更新之一。借助 GPU tile kernels,可以用比 SIMT

NVIDIA CUDA 13.1版本的新增功能與改進(jìn)
NVIDIA CUDA 13.1 是自 CUDA 二十年前發(fā)明以來,規(guī)模最大、內(nèi)容最全面的一次更新。
首款全國(guó)產(chǎn)訓(xùn)推一體AI芯片發(fā)布,兼容CUDA生態(tài)
CUDA生態(tài)體系。該芯片支持從單機(jī)多卡到千卡級(jí)集群的靈活擴(kuò)展,能效比達(dá)3.41 TFLOPS/W——在同等功

傳統(tǒng)格局將被打破?這款MEMS加速度計(jì)如何實(shí)現(xiàn)石英級(jí)精度
在慣性測(cè)量領(lǐng)域,高精度加速度計(jì)的市場(chǎng)格局似乎早已固化:石英加速度計(jì)憑借其卓越的穩(wěn)定性長(zhǎng)期占據(jù)著高端應(yīng)用的統(tǒng)治地位。然而,這一格局正在被悄然打破。ER-MA-6 MEMS加速度計(jì)的出現(xiàn),以其驚人的性能指標(biāo)向傳統(tǒng)發(fā)起挑戰(zhàn),讓業(yè)界不禁發(fā)問:MEMS技術(shù)真的能夠達(dá)到石英級(jí)精度嗎?

比亞迪仰望U9工程測(cè)試車打破全球電車極速紀(jì)錄
近日,仰望汽車宣布,仰望U9工程測(cè)試車在德國(guó)ATP測(cè)試場(chǎng)實(shí)現(xiàn)472.41km/h的最高時(shí)速成績(jī),打破全球電車極速紀(jì)錄,此舉是中國(guó)自主品牌首次在該領(lǐng)域問鼎世界。
英偉達(dá):CUDA 已經(jīng)開始移植到 RISC-V 架構(gòu)上
,著重介紹了將 CUDA 移植到 RISC-V 架構(gòu)的相關(guān)工作和計(jì)劃,展現(xiàn)了對(duì) RISC-V 架構(gòu)的高度重視與積極布局。 ? Frans Sijstermanns 首先回顧了英偉達(dá)與 RISC-V 之間
發(fā)表于 07-17 16:30
?3959次閱讀
進(jìn)迭時(shí)空同構(gòu)融合RISC-V AI CPU的Triton算子編譯器實(shí)踐
Pytorch已能做到100%替換CUDA,國(guó)內(nèi)也有智源研究院主導(dǎo)的FlagGems通用算子庫(kù)試圖構(gòu)建起不依賴CUDA的AI計(jì)算生態(tài),截至今日,F(xiàn)lagGems已進(jìn)入Pyto

Profinet轉(zhuǎn)CanOpen網(wǎng)關(guān),打破協(xié)議壁壘的關(guān)鍵技術(shù)
兩個(gè)使用不同方言的專家需要實(shí)時(shí)協(xié)作,此時(shí)開疆智能Profinet轉(zhuǎn)CanOpen網(wǎng)關(guān)便成為打破技術(shù)壁壘的關(guān)鍵樞紐。

半導(dǎo)體存儲(chǔ)器測(cè)試圖形技術(shù)解析
在半導(dǎo)體存儲(chǔ)器測(cè)試中,測(cè)試圖形(Test Pattern)是檢測(cè)故障、驗(yàn)證可靠性的核心工具。根據(jù)測(cè)試序列長(zhǎng)度與存儲(chǔ)單元數(shù)N的關(guān)系,測(cè)試圖形可分為N型、N2型和N3/?型三大類。
使用VirtualLab Fusion中分布式計(jì)算的AR波導(dǎo)測(cè)試圖像模擬
| 摘要
在這個(gè)用例中,一個(gè)完整的FOV測(cè)試圖像(在x和y方向分別采樣101個(gè)角度,總共有10,201個(gè)角度)通過波導(dǎo)設(shè)備傳播。一個(gè)具有數(shù)百個(gè)嚴(yán)格光柵評(píng)估的基本模擬大約需要7秒。這導(dǎo)致整個(gè)圖像的估計(jì)
發(fā)表于 04-10 08:48
使用NVIDIA CUDA-X庫(kù)加速科學(xué)和工程發(fā)展
NVIDIA GTC 全球 AI 大會(huì)上宣布,開發(fā)者現(xiàn)在可以通過 CUDA-X 與新一代超級(jí)芯片架構(gòu)的協(xié)同,實(shí)現(xiàn) CPU 和 GPU 資源間深度自動(dòng)化整合與調(diào)度,相較于傳統(tǒng)加速計(jì)算架構(gòu),該技術(shù)可使計(jì)算工程工具運(yùn)行速度提升至原來的 11 倍,計(jì)算規(guī)模增加至 5 倍。



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論