") 使用NVIDIA DCGM構(gòu)建GPU監(jiān)控解決方案
使用NVIDIA DCGM構(gòu)建GPU監(jiān)控解決方案

對(duì)于基礎(chǔ)設(shè)施或站點(diǎn)可靠性工程( SRE )團(tuán)隊(duì)來(lái)說(shuō),監(jiān)控多個(gè) GPU 對(duì)于管理大型 GPU 集群以實(shí)現(xiàn) AI 或 HPC 工作負(fù)載至關(guān)重要。 GPU 指標(biāo)允許團(tuán)隊(duì)了解工作負(fù)載行為,從而優(yōu)化資源分配和利用率,診斷異常,并提高數(shù)據(jù)中心的整體效率。除了基礎(chǔ)設(shè)施團(tuán)隊(duì)之外,無(wú)論您是從事 GPU – 加速 ML 工作流的研究人員,還是喜歡了解 GPU 利用率和容量規(guī)劃飽和的數(shù)據(jù)中心設(shè)計(jì)師,您應(yīng)該都對(duì)指標(biāo)感興趣。
這些趨勢(shì)變得更為重要,因?yàn)?AI / ML 工作負(fù)載通過(guò)使用 Kubernetes 之類的容器管理平臺(tái)進(jìn)行容器化和擴(kuò)展。在這篇文章中,我們將概述 NVIDIA 數(shù)據(jù)中心 GPU 經(jīng)理( DCGM ),以及如何將其集成到諸如 Prometheus 和 Grafana 這樣的開(kāi)源工具中,從而為 Kubernetes 構(gòu)建一個(gè) GPU 監(jiān)控解決方案。
NVIDIA DCGM 公司
NVIDIA DCGM 公司 是一組用于在基于 Linux 的大規(guī)模集群環(huán)境中管理和監(jiān)視 NVIDIA GPUs 的工具。它是一個(gè)低開(kāi)銷的工具,可以執(zhí)行各種功能,包括主動(dòng)健康監(jiān)視、診斷、系統(tǒng)驗(yàn)證、策略、電源和時(shí)鐘管理、組配置和記帳。
DCGM 包括用于收集 GPU 遙測(cè)的 API。特別感興趣的是 GPU 利用率指標(biāo)(用于監(jiān)視張量核心、 FP64 單元等)、內(nèi)存指標(biāo)和互連流量指標(biāo)。 DCGM 為各種語(yǔ)言(如 C 和 Python )提供了綁定,這些都包含在安裝程序包中。為了與 Go 作為編程語(yǔ)言流行的容器生態(tài)系統(tǒng)集成,有基于 DCGM API 的 Go 綁定 。存儲(chǔ)庫(kù)包括示例和 restapi ,以演示如何使用 Go API 監(jiān)視 GPUs 。去看看 NVIDIA/gpu-monitoring-tools repo !
導(dǎo)出
監(jiān)控堆棧通常由一個(gè)收集器、一個(gè)存儲(chǔ)度量的時(shí)間序列數(shù)據(jù)庫(kù)和一個(gè)可視化層組成。一個(gè)流行的開(kāi)源堆棧是 Prometheus ,與 Grafana 一起作為可視化工具來(lái)創(chuàng)建豐富的儀表板。普羅米修斯還包括 Alertmanager 來(lái)創(chuàng)建和管理警報(bào)。 Prometheus 與 kube-state-metrics 和 node_exporter 一起部署,以公開(kāi) kubernetesapi 對(duì)象的集群級(jí)指標(biāo)和節(jié)點(diǎn)級(jí)指標(biāo),如 CPU 利用率。圖 1 顯示了普羅米修斯的一個(gè)架構(gòu)示例。
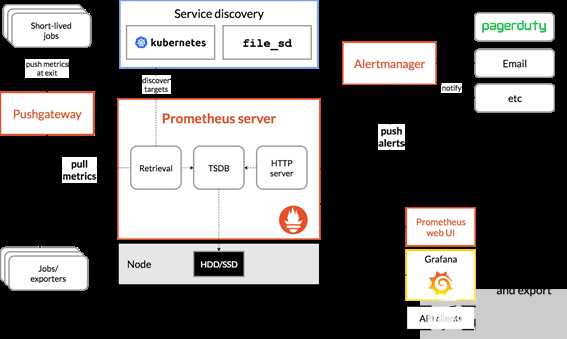
圖 1 參考普羅米修斯建筑。
在前面描述的 Go API 的基礎(chǔ)上,可以使用 DCGM 向 Prometheus 公開(kāi) GPU 度量。為此,我們建立了一個(gè)名為 dcgm-exporter 的項(xiàng)目。
dcgm-exporter 使用 Go 綁定 從 DCGM 收集 GPU 遙測(cè)數(shù)據(jù),然后為 Prometheus 公開(kāi)指標(biāo)以使用 http 端點(diǎn)(/metrics)進(jìn)行提取
dcgm-exporter 也是可配置的。您可以使用 .csv 格式的輸入配置文件,自定義 DCGM 要收集的 GPU 指標(biāo)。
Kubernetes 集群中的每個(gè) pod GPU 指標(biāo)
dcgm-exporter 收集節(jié)點(diǎn)上所有可用 GPUs 的指標(biāo)。然而,在 Kubernetes 中,當(dāng)一個(gè) pod 請(qǐng)求 GPU 資源時(shí),您不一定知道節(jié)點(diǎn)中的哪個(gè) GPUs 將被分配給一個(gè) pod 。從 v1 。 13 開(kāi)始, kubelet 添加了一個(gè)設(shè)備監(jiān)視功能,可以使用 pod 資源套接字找到分配給 pod — 的 pod 名稱、 pod 名稱空間和設(shè)備 ID 的設(shè)備。
dcgm-exporter 中的 http 服務(wù)器連接到 kubelet pod resources 服務(wù)器( /var/lib/kubelet/pod-resources ),以標(biāo)識(shí)在 pod 上運(yùn)行的 GPU 設(shè)備,并將 GPU 設(shè)備 pod 信息附加到收集的度量中。
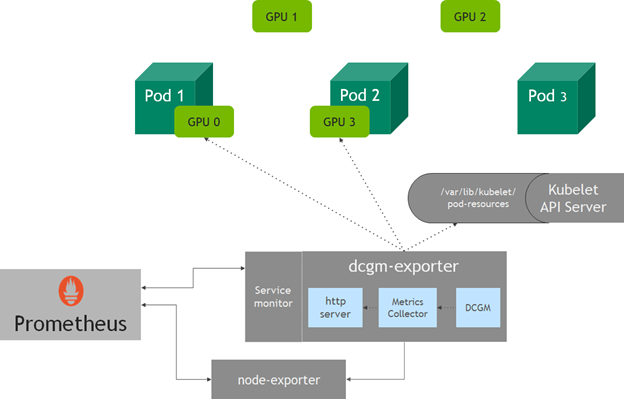
圖 2 GPU 在 Kubernetes 使用 dcgm exporter 進(jìn)行遙測(cè)。
設(shè)置 GPU 監(jiān)控解決方案
下面是一些設(shè)置 dcgm-exporter 的示例。如果您使用的是 NVIDIA GPU 操作員 ,那么 dcgm-exporter 是作為操作員的一部分部署的組件之一。
文檔包括 建立 Kubernetes 集群 的步驟。為了簡(jiǎn)潔起見(jiàn),請(qǐng)快速前進(jìn)到使用 NVIDIA 軟件組件運(yùn)行 Kubernetes 集群的步驟,例如,驅(qū)動(dòng)程序、容器運(yùn)行時(shí)和 Kubernetes 設(shè)備插件。您可以使用 Prometheus Operator 來(lái)部署 Prometheus ,它還可以方便地部署 Grafana 儀表板。在本文中,為了簡(jiǎn)單起見(jiàn),您將使用單節(jié)點(diǎn) Kubernetes 集群。
設(shè)置 普羅米修斯運(yùn)營(yíng)商目前提供的社區(qū)頭盔圖 時(shí),必須遵循 將 GPU 遙測(cè)技術(shù)集成到 Kubernetes 中 中的步驟。必須為外部訪問(wèn)公開(kāi) Grafana ,并且必須將 prometheusSpec.serviceMonitorSelectorNilUsesHelmValues 設(shè)置為 false 。
簡(jiǎn)而言之,設(shè)置監(jiān)視包括運(yùn)行以下命令:
$ helm repo add prometheus-community \ https://prometheus-community.github.io/helm-charts $ helm repo update $ helm inspect values prometheus-community/kube-prometheus-stack > /tmp/kube-prometheus-stack.values # Edit /tmp/kube-prometheus-stack.values in your favorite editor # according to the documentation # This exposes the service via NodePort so that Prometheus/Grafana # are accessible outside the cluster with a browser $ helm install prometheus-community/kube-prometheus-stack \ --create-namespace --namespace prometheus \ --generate-name \ --set prometheus.service.type=NodePort \ --set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
此時(shí),您的集群應(yīng)該看起來(lái)像下面這樣,其中所有的 Prometheus pods 和服務(wù)都在運(yùn)行:
$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-8f59968d4-zrsdt 1/1 Running 0 18m kube-system calico-node-c257f 1/1 Running 0 18m kube-system coredns-f9fd979d6-c52hz 1/1 Running 0 19m kube-system coredns-f9fd979d6-ncbdp 1/1 Running 0 19m kube-system etcd-ip-172-31-27-93 1/1 Running 1 19m kube-system kube-apiserver-ip-172-31-27-93 1/1 Running 1 19m kube-system kube-controller-manager-ip-172-31-27-93 1/1 Running 1 19m kube-system kube-proxy-b9szp 1/1 Running 1 19m kube-system kube-scheduler-ip-172-31-27-93 1/1 Running 1 19m kube-system nvidia-device-plugin-1602308324-jg842 1/1 Running 0 17m prometheus alertmanager-kube-prometheus-stack-1602-alertmanager-0 2/2 Running 0 92s prometheus kube-prometheus-stack-1602-operator-c4bc5c4d5-f5vzc 2/2 Running 0 98s prometheus kube-prometheus-stack-1602309230-grafana-6b4fc97f8f-66kdv 2/2 Running 0 98s prometheus kube-prometheus-stack-1602309230-kube-state-metrics-76887bqzv2b 1/1 Running 0 98s prometheus kube-prometheus-stack-1602309230-prometheus-node-exporter-rrk9l 1/1 Running 0 98s prometheus prometheus-kube-prometheus-stack-1602-prometheus-0 3/3 Running 1 92s $ kubectl get svc -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.96.0.1443/TCP 20m kube-system kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 20m kube-system kube-prometheus-stack-1602-coredns ClusterIP None 9153/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-controller-manager ClusterIP None 10252/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-etcd ClusterIP None 2379/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-proxy ClusterIP None 10249/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-scheduler ClusterIP None 10251/TCP 2m18s kube-system kube-prometheus-stack-1602-kubelet ClusterIP None 10250/TCP,10255/TCP,4194/TCP 2m12s prometheus alertmanager-operated ClusterIP None 9093/TCP,9094/TCP,9094/UDP 2m12s prometheus kube-prometheus-stack-1602-alertmanager ClusterIP 10.104.106.174 9093/TCP 2m18s prometheus kube-prometheus-stack-1602-operator ClusterIP 10.98.165.148 8080/TCP,443/TCP 2m18s prometheus kube-prometheus-stack-1602-prometheus NodePort 10.105.3.19 9090:30090/TCP 2m18s prometheus kube-prometheus-stack-1602309230-grafana ClusterIP 10.100.178.41 80/TCP 2m18s prometheus kube-prometheus-stack-1602309230-kube-state-metrics ClusterIP 10.100.119.13 8080/TCP 2m18s prometheus kube-prometheus-stack-1602309230-prometheus-node-exporter ClusterIP 10.100.56.74 9100/TCP 2m18s prometheus prometheus-operated ClusterIP None 9090/TCP 2m12s
安裝 DCGM-Exporter
下面是如何開(kāi)始安裝 dcgm-exporter 來(lái)監(jiān)視 GPU 的性能和利用率。您可以使用頭盔圖表來(lái)設(shè)置 dcgm-exporter 。首先,添加 Helm 回購(gòu):
$ helm repo add gpu-helm-charts \ https://nvidia.github.io/gpu-monitoring-tools/helm-charts
$ helm repo update
然后,使用 Helm 安裝圖表:
$ helm install \ --generate-name \ gpu-helm-charts/dcgm-exporter
可以使用以下命令觀察展開(kāi):
$ helm ls NAME NAMESPACE REVISION APP VERSION dcgm-exporter-1-1601677302 default 1 dcgm-exporter-1.1.0 2.0.10 nvidia-device-plugin-1601662841 default 1 nvidia-device-plugin-0.7.0 0.7.0
普羅米修斯和格拉法納的服務(wù)應(yīng)公開(kāi)如下:
$ kubectl get svc -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default dcgm-exporter ClusterIP 10.99.34.1289400/TCP 43d default kubernetes ClusterIP 10.96.0.1 443/TCP 20m kube-system kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 20m kube-system kube-prometheus-stack-1602-coredns ClusterIP None 9153/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-controller-manager ClusterIP None 10252/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-etcd ClusterIP None 2379/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-proxy ClusterIP None 10249/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-scheduler ClusterIP None 10251/TCP 2m18s kube-system kube-prometheus-stack-1602-kubelet ClusterIP None 10250/TCP,10255/TCP,4194/TCP 2m12s prometheus alertmanager-operated ClusterIP None 9093/TCP,9094/TCP,9094/UDP 2m12s prometheus kube-prometheus-stack-1602-alertmanager ClusterIP 10.104.106.174 9093/TCP 2m18s prometheus kube-prometheus-stack-1602-operator ClusterIP 10.98.165.148 8080/TCP,443/TCP 2m18s prometheus kube-prometheus-stack-1602-prometheus NodePort 10.105.3.19 9090:30090/TCP 2m18s prometheus kube-prometheus-stack-1602309230-grafana ClusterIP 10.100.178.41 80:32032/TCP 2m18s prometheus kube-prometheus-stack-1602309230-kube-state-metrics ClusterIP 10.100.119.13 8080/TCP 2m18s prometheus kube-prometheus-stack-1602309230-prometheus-node-exporter ClusterIP 10.100.56.74 9100/TCP 2m18s prometheus prometheus-operated ClusterIP None 9090/TCP 2m12s
使用在端口 32032 公開(kāi)的 Grafana 服務(wù),訪問(wèn) Grafana 主頁(yè)。使用普羅米修斯圖表中可用的憑據(jù)登錄到儀表板: prometheus.values 中的 adminPassword 字段。
現(xiàn)在要為 GPU 度量啟動(dòng) Grafana 儀表板,請(qǐng)從 數(shù)一數(shù)儀表板。 導(dǎo)入引用的 NVIDIA 儀表板。
使用 DCGM 儀表板
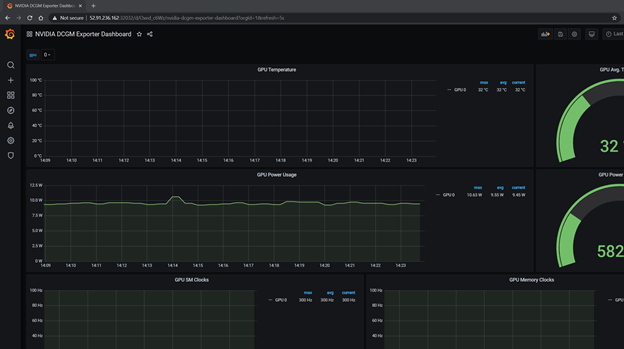
圖 3 參考 NVIDIA Grafana dashboard 。
現(xiàn)在運(yùn)行一些 GPU 工作負(fù)載。為此, DCGM 包括一個(gè)名為 dcgmproftester 的 CUDA 負(fù)載生成器。它可以用來(lái)生成確定性的 CUDA 工作負(fù)載,用于讀取和驗(yàn)證 GPU 度量。我們有一個(gè)集裝箱化的 dcgmproftester ,可以在 Docker 命令行上運(yùn)行。這個(gè)例子生成一個(gè)半精度( FP16 )矩陣乘法( GEMM ),并使用 GPU 上的張量核。
產(chǎn)生負(fù)載
要生成負(fù)載,必須首先下載 DCGM 并將其容器化。下面的腳本創(chuàng)建一個(gè)可用于運(yùn)行 dcgmproftester 的容器。此容器可在 NVIDIA DockerHub 存儲(chǔ)庫(kù)中找到。
#!/usr/bin/env bash set -exo pipefail mkdir -p /tmp/dcgm-docker pushd /tmp/dcgm-docker cat > Dockerfile <在將容器部署到 Kubernetes 集群之前,請(qǐng)嘗試在 Docker 中運(yùn)行它。在本例中,通過(guò)指定
-t 1004,使用張量核心觸發(fā) FP16 矩陣乘法,并運(yùn)行測(cè)試-d 45( 45 秒)。您可以通過(guò)修改-t參數(shù)來(lái)嘗試運(yùn)行其他工作負(fù)載。$ docker run --rm --gpus all --cap-add=SYS_ADMIN nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 --no-dcgm-validation -t 1004 -d 45 Skipping CreateDcgmGroups() since DCGM validation is disabled CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_MULTIPROCESSOR: 1024 CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT: 40 CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 65536 CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR: 7 CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR: 5 CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH: 256 CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE: 5001000 Max Memory bandwidth: 320064000000 bytes (320.06 GiB) CudaInit completed successfully. Skipping WatchFields() since DCGM validation is disabled TensorEngineActive: generated ???, dcgm 0.000 (27605.2 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28697.6 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28432.8 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28585.4 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28362.9 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28361.6 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28448.9 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28311.0 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28210.8 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28304.8 gflops)將此計(jì)劃到您的 Kubernetes 集群上,并在 Grafana 儀表板中查看適當(dāng)?shù)亩攘俊O旅娴拇a示例使用容器的適當(dāng)參數(shù)構(gòu)造此 podspec :
cat << EOF | kubectl create -f - ?apiVersion: v1 ?kind: Pod ?metadata: ?? name: dcgmproftester ?spec: ?? restartPolicy: OnFailure ?? containers: ?? - name: dcgmproftester11 ???? image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 ???? args: ["--no-dcgm-validation", "-t 1004", "-d 120"] ???? resources: ?????? limits: ????????? nvidia.com/gpu: 1 ???? securityContext: ?????? capabilities: ????????? add: ["SYS_ADMIN"] ? EOF您可以看到
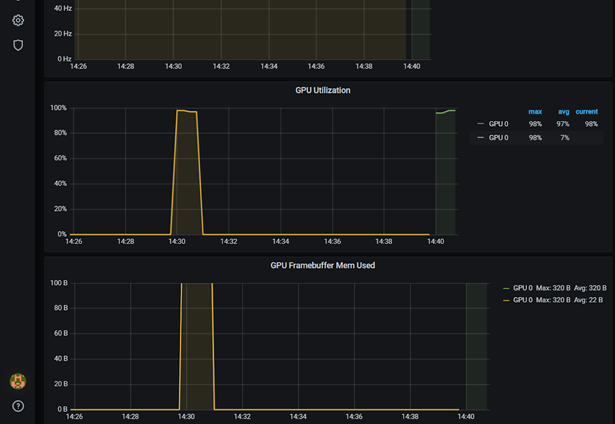
dcgmproftesterpod 正在運(yùn)行,然后在 Grafana 儀表板上顯示度量。 GPU 利用率( GrActive )已達(dá)到 98% 的峰值。您還可能會(huì)發(fā)現(xiàn)其他指標(biāo)很有趣,比如 power 或 GPU 內(nèi)存。$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE ... default dcgmproftester 1/1 Running 0 6s ...
圖 4 GPU 運(yùn)行 dcgmproftest 時(shí)在 Grafana 中的利用率。
驗(yàn)證 GPU 指標(biāo)
DCGM 最近增加了一些設(shè)備級(jí)指標(biāo)。其中包括細(xì)粒度的 GPU 利用率指標(biāo),可以監(jiān)視 SM 占用率和 Tensor 核心利用率。為了方便起見(jiàn),當(dāng)您使用 Helm 圖表部署 dcgm-exporter 時(shí),它被配置為默認(rèn)收集這些度量。
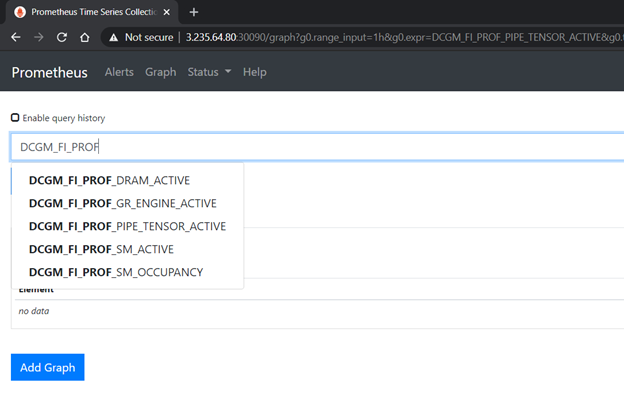
圖 5 顯示了在 Prometheus 儀表板中驗(yàn)證 dcgm-exporter 提供的評(píng)測(cè)指標(biāo)。
圖 5 GPU 在普羅米修斯儀表板中分析 DCGM 的指標(biāo)。
您可以定制 Grafana 儀表板以包含 DCGM 的其他指標(biāo)。在本例中,通過(guò)編輯 repo 上可用的 JSON 伯爵夫人 文件,將 Tensor 核心利用率添加到儀表板中。你也可以使用網(wǎng)頁(yè)界面。請(qǐng)隨意修改儀表板。
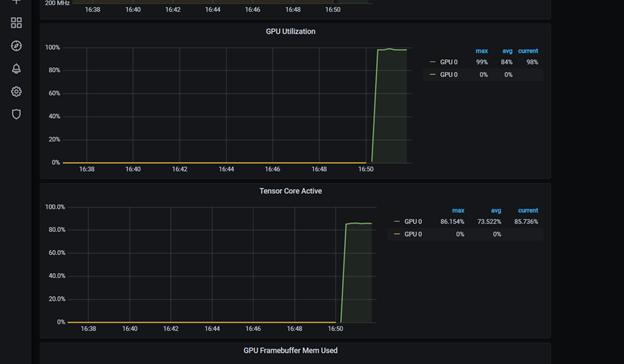
此儀表板包括 Tensor 核心利用率。您可以進(jìn)一步自定義它。重新啟動(dòng) dcgmproftester 容器后,您可以看到 T4 上的張量核心已達(dá)到約 87% 的利用率:
圖 6 Grafana 的張量核心利用率(百分比)。
請(qǐng)隨意修改 JSON 儀表板,以包含 DCGM 支持的其他 GPU 指標(biāo)。支持的 GPU 指標(biāo)在 DCGM DCGM API Documentation 中可用。通過(guò)使用 GPU 指標(biāo)作為定制指標(biāo)和普羅米修斯適配器,您可以使用 臥式吊艙自動(dòng)標(biāo)度機(jī) 根據(jù) GPU 利用率或其他指標(biāo)來(lái)縮放吊艙的數(shù)量。
概要
要從 dcgm-exporter 開(kāi)始,并將監(jiān)視解決方案放在 Kubernetes 上,無(wú)論是在前提還是在云中,請(qǐng)參閱 將 GPU 遙測(cè)技術(shù)集成到 Kubernetes 中 ,或?qū)⑵洳渴馂?NVIDIA GPU 操作員 的一部分。
關(guān)于作者
Pramod Ramarao 是 NVIDIA 加速計(jì)算的產(chǎn)品經(jīng)理。他領(lǐng)導(dǎo) CUDA 平臺(tái)和數(shù)據(jù)中心軟件的產(chǎn)品管理,包括容器技術(shù)。
Ahmed Al-Sudani 是 NVIDIA DCGM 團(tuán)隊(duì)的軟件工程師。他致力于在數(shù)據(jù)中心環(huán)境中實(shí)現(xiàn)健康和性能監(jiān)控。
Swati Gupta 是 NVIDIA 的系統(tǒng)軟件工程師,她在 OpenShift 云基礎(chǔ)設(shè)施、協(xié)調(diào)和監(jiān)控方面工作。她專注于在容器編排系統(tǒng)(如 Kubernetes 、 GPU 和 Docker )中啟用 GPU - 加速的 DL 和 AI 工作負(fù)載。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5594瀏覽量
109749 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135467 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
18文章
5651瀏覽量
75021
發(fā)布評(píng)論請(qǐng)先 登錄
借助NVIDIA CUDA Tile IR后端推進(jìn)OpenAI Triton的GPU編程
NVIDIA RTX PRO 5000 Blackwell GPU的深度評(píng)測(cè)

在Python中借助NVIDIA CUDA Tile簡(jiǎn)化GPU編程

NVIDIA推出NVQLink高速互連架構(gòu)
Lambda采用Supermicro NVIDIA Blackwell GPU服務(wù)器集群構(gòu)建人工智能工廠
NVIDIA RTX PRO 4500 Blackwell GPU測(cè)試分析

NVIDIA Omniverse Extension開(kāi)發(fā)秘籍
NVIDIA桌面GPU系列擴(kuò)展新產(chǎn)品
亞馬遜基于NVIDIA技術(shù)實(shí)現(xiàn)創(chuàng)新型制造解決方案
英偉達(dá):我們的芯片不存監(jiān)控軟件 NVIDIA官方發(fā)文 NVIDIA芯片不存在后門(mén)、終止開(kāi)關(guān)和監(jiān)控軟件
Ansys使用NVIDIA技術(shù)優(yōu)化CFD仿真解決方案
利用NVIDIA技術(shù)構(gòu)建從數(shù)據(jù)中心到邊緣的智慧醫(yī)院解決方案
NVIDIA Omniverse Kit 107的安裝部署步驟




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論