 擴散模型在視頻領域表現如何?
擴散模型在視頻領域表現如何?

擴散模型正在不斷的「攻城略地」。
擴散模型并不是一個嶄新的概念,早在2015年就已經被提出。其核心應用領域包括音頻建模、語音合成、時間序列預測、降噪等。
那么它在視頻領域表現如何?先前關于視頻生成的工作通常采用諸如GAN、VAE、基于流的模型。
在視頻生成領域,研究的一個重要里程碑是生成時間相干的高保真視頻。來自谷歌的研究者通過提出一個視頻生成擴散模型來實現這一里程碑,顯示出非常有希望的初步結果。本文所提出的模型是標準圖像擴散架構的自然擴展,它可以從圖像和視頻數據中進行聯合訓練,研究發現這可以減少小批量梯度的方差并加快優化速度。
為了生成更長和更高分辨率的視頻,該研究引入了一種新的用于空間和時間視頻擴展的條件采樣技術,該技術比以前提出的方法表現更好。

論文地址:https://arxiv.org/pdf/2204.03458.pdf
論文主頁:https://video-diffusion.github.io/
研究展示了文本條件視頻生成的結果和無條件視頻生成基準的最新結果。例如生成五彩斑斕的煙花:

其他生成結果展示:

這項研究有哪些亮點呢?首先谷歌展示了使用擴散模型生成視頻的首個結果,包括無條件和有條件設置。先前關于視頻生成的工作通常采用其他類型的生成模型,如 GAN、VAE、基于流的模型和自回歸模型。
其次該研究表明,可以通過高斯擴散模型的標準公式來生成高質量的視頻,除了直接的架構更改以適應深度學習加速器的內存限制外,幾乎不需要其他修改。該研究訓練生成固定數量的視頻幀塊的模型,并且為了生成比該幀數更長的視頻,他們還展示了如何重新調整訓練模型的用途,使其充當對幀進行塊自回歸的模型。
方法介紹
圖像擴散模型中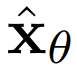 的標準架構是U-Net,它是一種被構造為空間下采樣通道的神經網絡架構,空間上采樣通道緊隨其后,其中殘差連接到下采樣通道激活。這種神經網絡由2D卷積殘差塊的層構建而成,并且每個這種卷積塊的后面是空間注意力塊。
的標準架構是U-Net,它是一種被構造為空間下采樣通道的神經網絡架構,空間上采樣通道緊隨其后,其中殘差連接到下采樣通道激活。這種神經網絡由2D卷積殘差塊的層構建而成,并且每個這種卷積塊的后面是空間注意力塊。
研究者建議將這一圖像擴散模型架構擴展至視頻數據,給定了固定數量幀的塊,并且使用了在空間和時間上分解的特定類型的 3D U-Net。
首先,研究者通過將每個 2D卷積改成space-only 3D卷積對圖像模型架構進行修改,比如將每個3x3卷積改成了1x3x3卷積,即第一個軸(axis)索引視頻幀,第二和第三個索引空間高度和寬度。每個空間注意力塊中的注意力仍然為空間上的注意力,也即第一個軸被視為批處理軸(batch axis)。
其次,在每個空間注意力塊之后,研究者插入一個時間注意力塊,它在第一個軸上執行注意力并將空間軸視為批處理軸。他們在每個時間注意力塊中使用相對位置嵌入,如此網絡不需要絕對視頻時間概念即可區分幀的順序。3D U-Net 的模型架構可視圖如下所示。
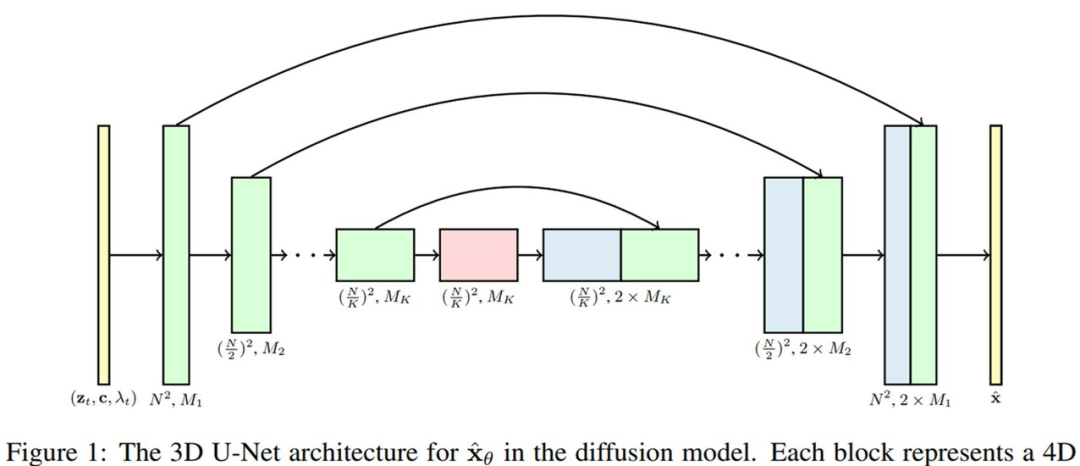
我們都知道,得益于分解時空注意力的計算效率,在視頻transformers中使用它是一個很好的選擇。研究者使用的分解時空架構是自身視頻生成設置獨有的,它的一大優勢是可以直接 mask 模型以在獨立圖像而非視頻上運行,其中只需刪除每個時間注意力塊內部的注意力操作并修復注意力矩陣以在每個視頻時間步精確匹配每個鍵和問詢向量。
這樣做的好處是允許聯合訓練視頻和圖像生成的模型。研究者在實驗中發現,這種聯合訓練對樣本質量非常重要。
新穎的條件生成梯度方法
研究者的主要創新是設計了一種新的、用于無條件擴散模型的條件生成方法,稱之為梯度方法,它修改了模型的采樣過程以使用基于梯度的優化來改進去噪數據上的條件損失。他們發現,梯度方法比現有方法更能確保生成樣本與條件信息的一致性。
研究者使用該梯度方法將自己的模型自回歸地擴展至更多的時間步和更高的分辨率。
下圖左為利用梯度方法的視頻幀,圖右為利用自回歸擴展基線替代(replacement)方法的幀。可以看到,使用梯度方法采用的視頻比基線方法具有更好的時間相干性。

實驗結果
研究者對無條件、文本-條件視頻生成模型進行了評估。文本-條件視頻生成是在一個包含 1000 萬個字幕視頻數據集上進行訓練,視頻空間分辨率為 64x64 ;對于無條件視頻生成,該研究在現有基準 [36] 上訓練和評估模型。
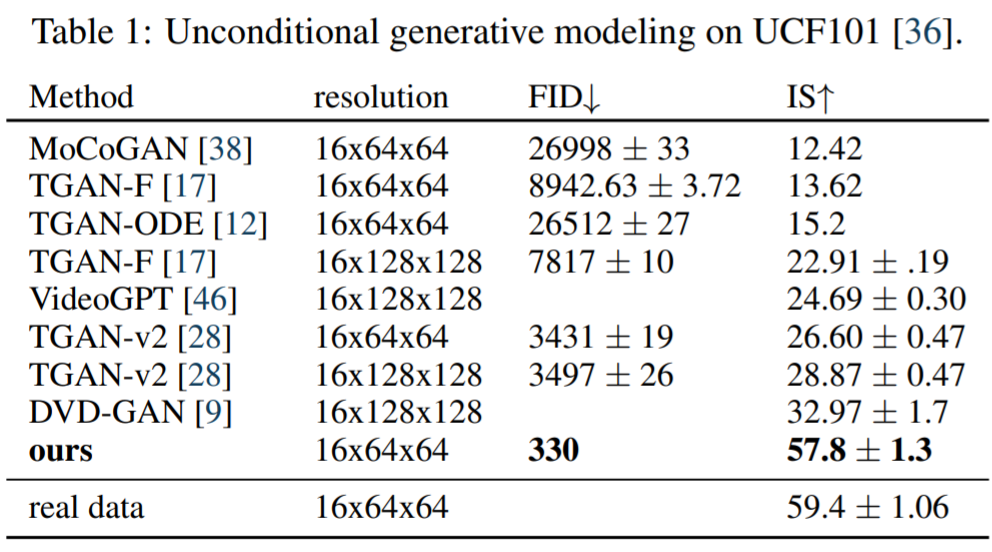
無條件視頻建模該研究使用 Soomro 等人[36]提出的基準對無條件視頻生成模型進行評估。表 1 展示了該研究所提模型生成的視頻的感知質量得分,并與文獻中的方法進行了比較,發現本文方法大大提高了SOTA。
視頻、圖像模型聯合訓練:表 2 報告了針對文本-條件的 16x64x64 視頻的實驗結果。

無分類器指導的效果:表3 表明無分類器指導 [13] 在文本-視頻生成方面的有效性。正如預期的那樣,隨著指導權重的增加,類 Inception Score 的指標有明顯的改進,而類 FID 的指標隨著引導權重的增加先改善然后下降。
表 3 報告的結果驗證了無分類器指導 [13] 在文本-視頻生成方面的有效性。正如預期的那樣,隨著引導權重的增加,類 Inception Score (IS)的指標有明顯的改進,而類 FID 的指標隨著引導權重的增加先改善然后下降。這一現象在文本-圖像生成方面也有類似的發現[23]。
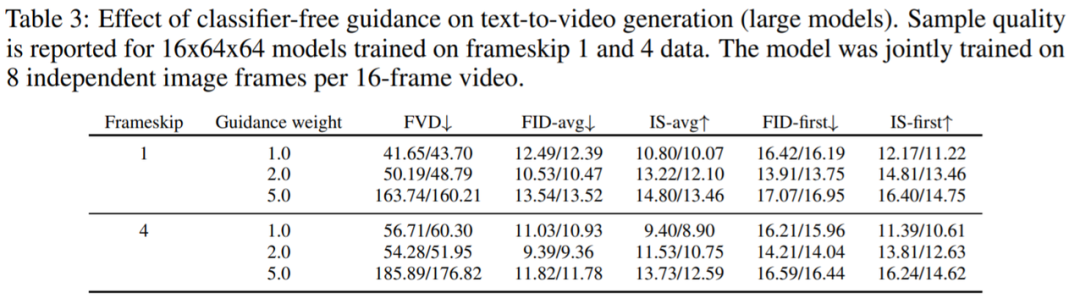
圖 3 顯示了無分類器指導 [13] 對文本-條件視頻模型的影響。與在文本條件圖像生成 [23] 和類條件圖像生成 [13, 11] 上使用無分類器指導的其他工作中觀察到的類似,添加指導提高了每個圖像的樣本保真度。

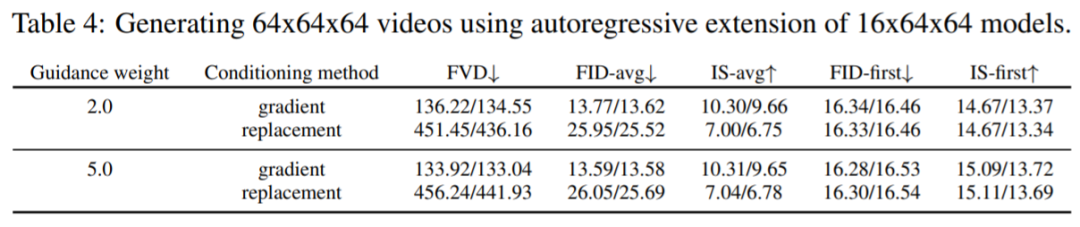
針對較長序列的自回歸視頻擴展:3.1節提出了基于擴散模型的條件采樣梯度法,這是對[35]中替換方法的改進。表4展示了使用這兩種技術生成較長視頻的結果,由結果可得本文提出的方法在感知質量分數方面確實優于替換方法。
審核編輯 :李倩
-
視頻
+關注
關注
6文章
2005瀏覽量
74956 -
GaN
+關注
關注
21文章
2366瀏覽量
82258 -
模型
+關注
關注
1文章
3752瀏覽量
52099
原文標題:視頻生成無需GAN、VAE,谷歌用擴散模型聯合訓練視頻、圖像,實現新SOTA
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
杭晶電子差分晶振產品在視頻領域的應用

探索RISC-V在機器人領域的潛力
AI視頻分析在化工領域的應用和開發
百度重磅發布!全球首創中文音視頻模型
一種基于擴散模型的視頻生成框架RoboTransfer

無法使用OpenVINO?在 GPU 設備上運行穩定擴散文本到圖像的原因?
大模型在半導體行業的應用可行性分析
明遠智睿SSD2351開發板:視頻監控領域的卓越之選
奧松電子擴散硅壓力變送器的優勢

基于Nanopaint壓感油墨系統的柔性傳感系統在體育表現監測中的應用
國產地物光譜儀在“高光譜-機器學習”模型構建中的表現
DiffusionDrive首次在端到端自動駕駛中引入擴散模型




 工商網監
工商網監
評論