") WSL2上CUDA性能的當前狀態(tài)和發(fā)展
WSL2上CUDA性能的當前狀態(tài)和發(fā)展

2020 年 6 月,我們發(fā)布了第一個 NVIDIA 顯示驅(qū)動程序,該驅(qū)動程序為 Windows Insider Program ( WIP )預(yù)覽用戶啟用了 Windows Subsystem for Linux ( WSL ) 2 中的 GPU 加速功能。當時,這仍然是一個早期預(yù)覽,功能有限。一年后,隨著我們穩(wěn)步增加新功能,我們也一直專注于優(yōu)化 CUDA 驅(qū)動程序,以在 WSL2 上提供最佳性能。
WSL 是 Windows 10 的一項功能,它使您能夠直接在 Windows 上運行本機 Linux 命令行工具,而不需要雙啟動環(huán)境的復(fù)雜性。在內(nèi)部, WSL 是一個與 Microsoft Windows 操作系統(tǒng)緊密集成的容器化環(huán)境。 WSL2 使您能夠與傳統(tǒng) Windows 桌面和現(xiàn)代商店應(yīng)用程序一起運行 Linux 應(yīng)用程序。有關(guān) WSL 上 CUDA 的更多信息,請參閱 在 Linux 2 的 Windows 子系統(tǒng)上宣布 CUDA 。
在本文中,我們將重點介紹 WSL2 上 CUDA 性能的當前狀態(tài)、已經(jīng)進行的各種以性能為中心的優(yōu)化,以及未來的展望。
WSL 性能的當前狀態(tài)
在過去的幾個月里,我們一直在通過分析和優(yōu)化 NVIDIA 和 Microsoft 方面的多個關(guān)鍵驅(qū)動程序路徑來調(diào)整 WSL2 上 CUDA 驅(qū)動程序的性能。在本文中,我們將詳細介紹我們?yōu)檫_到當前性能水平所做的工作。在我們開始之前,這里是 WSL2 在幾個基準上的當前狀態(tài)。
在 WSL2 上,所有 GPU 操作都通過 VMBUS 序列化并發(fā)送到主機內(nèi)核接口。 WSL2 最常見的性能問題之一是上述操作的開銷。我們知道,開發(fā)人員想知道,與直接在本機 Linux 上運行工作負載相比,在 WSL2 中運行工作負載是否有任何開銷。有區(qū)別嗎?這項開銷大嗎?
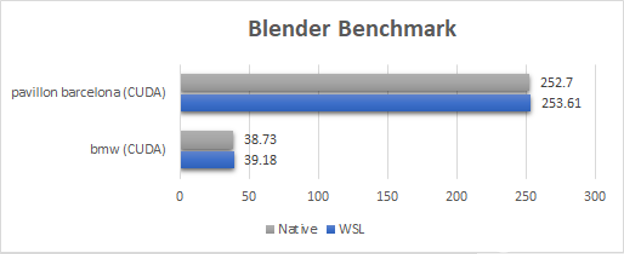
圖 1 。 Blender 基準測試結(jié)果( WSL2 與 Native ,結(jié)果以秒為單位,越低越好) 。
對于 Blender 基準測試, WSL2 性能與本機 Linux 相當或接近(在 1% 以內(nèi))。因為 Blender 循環(huán)將長時間運行的內(nèi)核推送到 GPU 上,所以 WSL2 的開銷在這些基準上都是不可見的。
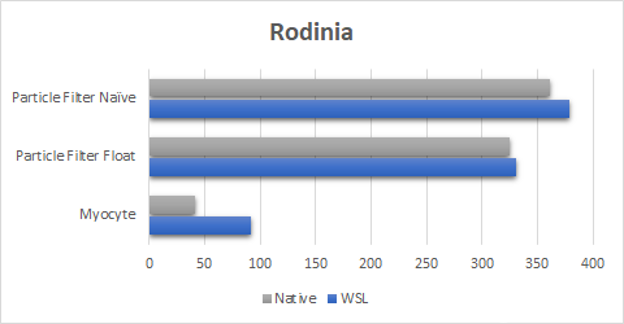
圖 2 。 Rodinia 基準測試套件結(jié)果( WSL2 與本機比較,結(jié)果以秒為單位,越低越好)。
談到 Rodinia 基準測試套件(圖 2 ),我們在第一次啟動對 WSL2 的支持時已經(jīng)取得了很大的成績。
新的驅(qū)動程序可以執(zhí)行得更好,甚至可以達到接近粒子過濾器測試的本機執(zhí)行時間。它也最終縮小了心肌細胞基準的差距。這對于 Myocyte 基準測試尤其重要,與本機 Linux 相比, WSL2 的早期結(jié)果慢了 10 倍。 Myocyte 在 WSL2 上特別難,因為這個基準由許多非常小的順序提交(小于微秒)組成,使其成為順序啟動延遲微基準。這是我們正在調(diào)查的一個領(lǐng)域,以實現(xiàn)完全的性能對等。
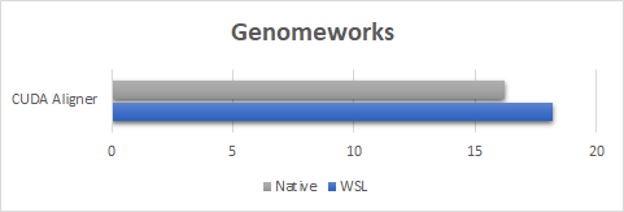
圖 3 。 GenomeWorks CUDA 對齊器示例執(zhí)行時間( WSL2 與本機比較,結(jié)果以秒為單位,越低越好) 。
對于 GenomeWorks 基準測試(圖 3 ),我們使用 CUDA 對齊器進行 GPU 加速成對對齊。為了顯示性能開銷的最壞情況,這里的基準測試運行是使用由短時間運行的內(nèi)核組成的樣本數(shù)據(jù)集完成的。由于內(nèi)核啟動有多短,您可以觀察 WSL2 上的啟動延遲開銷。但是,即使對于這個最壞的示例,性能也等于或超過本機速度的 90% 。我們的期望是,對于數(shù)據(jù)集大小通常較大的實際用例,性能將接近本機性能。
要探索內(nèi)核大小和 WSL2 性能之間的關(guān)鍵權(quán)衡,請查看下一個基準測試。
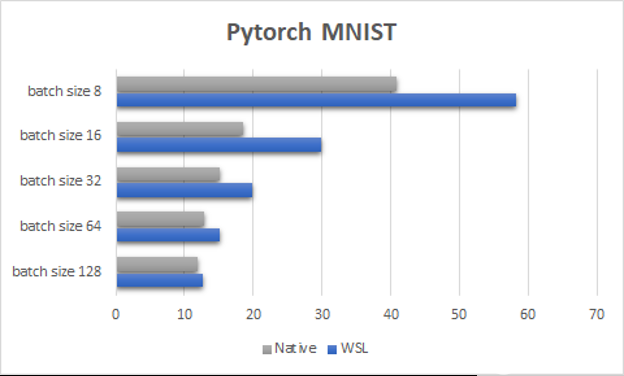
圖 4 。 PyTorch MNIST 每個歷元的采樣時間,具有不同的批大小( WSL2 與本機,結(jié)果以秒為單位,越低越好) 。
圖 4 顯示了 PyTorch MNIST 測試,這是一個專門設(shè)計的小型玩具機器學習示例,它強調(diào)了讓 GPU 保持忙碌以在 WSL2 上達到令人滿意的性能是多么重要。與本機 Linux 一樣,工作負載越小,啟動 GPU 進程的開銷越可能導(dǎo)致性能下降。這種降級在 WSL2 上更為明顯,與本機 Linux 相比,其擴展性也有所不同。
隨著對 WSL2 驅(qū)動程序的不斷改進,對于非常小的工作負載,這種伸縮性差異應(yīng)該越來越不明顯。在 WSL2 和本機 Linux 上避免這些陷阱的最佳方法是盡可能使 GPU 保持忙碌。
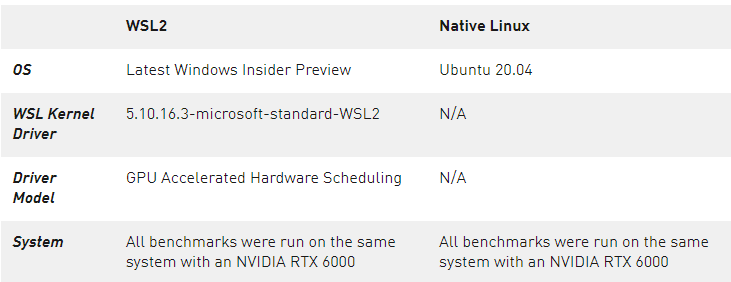
表 1 。用于基準測試的系統(tǒng)配置和軟件版本
。

表 2 。使用的基準測試名稱以及每個測試的簡要說明
。
啟動延遲優(yōu)化
啟動延遲是一些本機 Linux 應(yīng)用程序與 WSL2 之間性能差異的主要原因之一。這里有兩個重要指標:
GPU 內(nèi)核啟動延遲: 通過 CUDA 調(diào)用啟動內(nèi)核并由 GPU 啟動執(zhí)行所需的時間。
端到端開銷 (啟動延遲加上同步開銷):通過 CUDA 調(diào)用啟動內(nèi)核并在 CPU 上等待其完成所需的總時間,不包括內(nèi)核運行時本身。
當推送到 GPU 上的工作負載明顯大于延遲本身時,啟動延遲通常可以忽略不計。多虧了 CUDA 原語(如流和圖),您可以讓 GPU 保持忙碌,并可以利用這些 API 的異步特性來克服任何延遲問題。但是,當發(fā)送到 GPU 的工作負載的執(zhí)行時間接近啟動延遲時,它很快就會成為一個主要的性能瓶頸。啟動延遲將充當啟動速率限制器,這將導(dǎo)致內(nèi)核執(zhí)行性能下降。
本機 Windows 上的啟動延遲
在深入探討在 WSL2 上啟動延遲是一個需要克服的重大障礙之前,我們先解釋一下本機 Windows 上 CUDA 內(nèi)核的啟動路徑。 CUDA Windows 驅(qū)動程序中實現(xiàn)了兩種不同的啟動模型:一種用于數(shù)據(jù)包調(diào)度,另一種用于硬件加速 GPU 調(diào)度。
分組調(diào)度
在數(shù)據(jù)包調(diào)度中,操作系統(tǒng)負責大部分的調(diào)度工作。然而,為了補償提交模型和顯著的啟動開銷, CUDA 驅(qū)動程序總是嘗試基于各種啟發(fā)式方法批處理一定數(shù)量的內(nèi)核啟動。圖 5 顯示,在數(shù)據(jù)包調(diào)度模式下,操作系統(tǒng)調(diào)度提交,并針對給定上下文對提交進行序列化。這意味著一次提交的所有工作必須在下一次提交的任何工作開始之前完成。
為了提高數(shù)據(jù)包調(diào)度模式下的吞吐量, CUDA 驅(qū)動程序嘗試在一次提交中聚合一些啟動,即使它們在內(nèi)部跨多個 GPU 隊列調(diào)度。這種啟發(fā)式方法有助于解決錯誤依賴性和并行性問題,還可以減少提交的數(shù)據(jù)包數(shù)量,減少調(diào)度開銷時間。
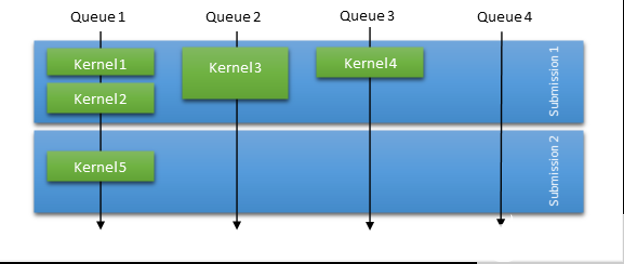
圖 5 。 WDDM 數(shù)據(jù)包調(diào)度模型概述及其在 CUDA 驅(qū)動程序中的使用 。
在這個提交模型中,當工作負載受啟動延遲限制時,您會看到性能達到極限。您可以通過查詢具有較小掛起工作負載的流的狀態(tài),強制發(fā)布未完成的提交。在這種情況下,除了必須處理潛在的錯誤依賴項外,它還面臨著高調(diào)度開銷。
硬件加速 GPU 調(diào)度
最近,微軟推出了一種稱為硬件加速 GPU 調(diào)度的新模式。使用此模型,可以直接為給定上下文公開硬件隊列,并且用戶模式驅(qū)動程序(在本例中為 CUDA )全權(quán)負責管理工作提交和工作項之間的依賴關(guān)系。它消除了將多個內(nèi)核啟動批處理到單個提交中的需要,使您能夠采用與本地 Linux 驅(qū)動程序相同的策略,在本地 Linux 驅(qū)動程序中,工作提交幾乎是即時的(圖 6 )。
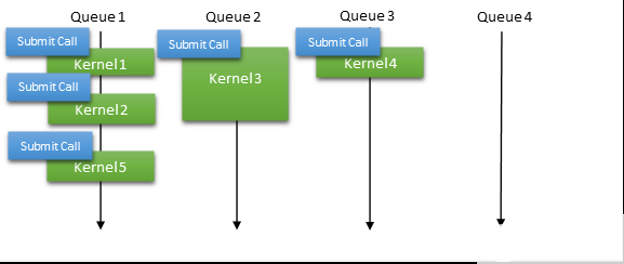
圖 6 。 CUDA 驅(qū)動程序中使用的 WDDM 硬件調(diào)度模型概述 。
這種基于硬件調(diào)度的提交模型消除了錯誤的依賴性,避免了緩沖的需要。它還通過將以前在 CPU 上處理的一些操作系統(tǒng)調(diào)度任務(wù)卸載到 GPU 來減少開銷。
在 WSL2 上利用硬件加速 GPU 調(diào)度
為什么這些日程安排細節(jié)很重要?傳統(tǒng)上,本機 Windows 應(yīng)用程序設(shè)計為隱藏較高的延遲。然而,對于本機 Linux 應(yīng)用程序來說,啟動延遲從來不是一個因素,在本機 Linux 應(yīng)用程序中,延遲影響性能的閾值比 Windows 上的閾值小一個數(shù)量級。
當這些相同的 Linux 應(yīng)用程序在 WSL2 中運行時,啟動延遲變得更加突出。在這里,硬件加速 GPU 調(diào)度的好處可以抵消延遲導(dǎo)致的性能損失,因為 CUDA 在 WSL2 和本機 Windows 上采用了與本機 Linux 相同的提交策略。我們強烈建議在運行 WSL2 時切換到硬件加速 GPU 調(diào)度模式。
即使使用硬件加速的 GPU 調(diào)度,向 GPU 提交工作仍然是通過調(diào)用操作系統(tǒng)完成的,就像在數(shù)據(jù)包調(diào)度中一樣。不僅提交,而且在某些情況下,同步 MIG ht 還必須進行一些操作系統(tǒng)調(diào)用以進行錯誤檢測。在 WSL2 上對操作系統(tǒng)的每次此類調(diào)用都涉及跨越 WSL2 邊界,通過 VMBUS 到達主機內(nèi)核模式。這可能很快成為驅(qū)動程序的單一瓶頸(圖 7 )。同時進行小批量 GPU 工作的 Linux 應(yīng)用程序可能仍然不能很好地運行。
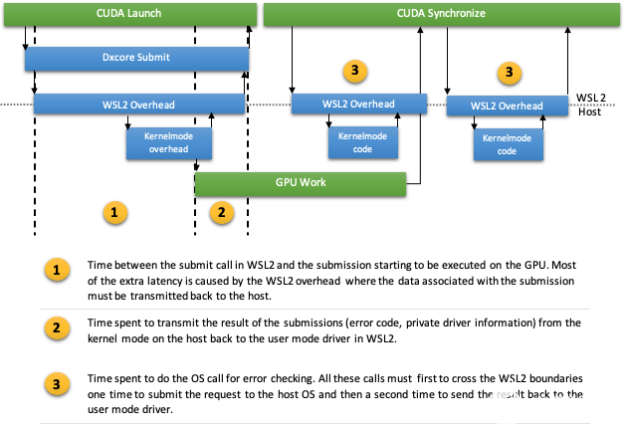
圖 7 。 WSL2 上提交路徑的概述以及額外開銷的各個位置 。
異步提交以減少啟動延遲
我們找到了一個解決方案,通過 Microsoft 更改提交調(diào)用的異步性來減輕 WSL 上額外的啟動延遲。通過利用此調(diào)用,您可以在提交過程中開始重疊其他操作,并以這種方式隱藏額外的 WSL 開銷。由于 submit 調(diào)用的新異步特性,啟動延遲現(xiàn)在可與本機 Windows 媲美。
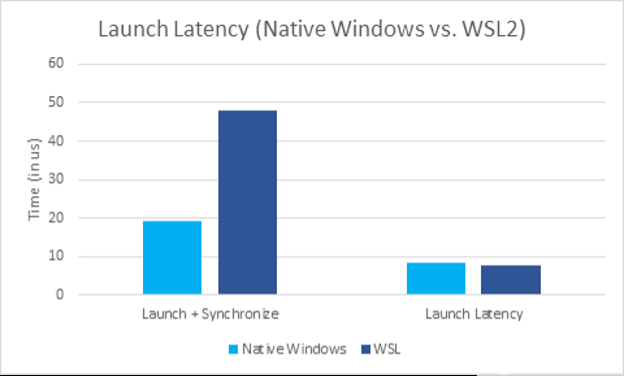
圖 8 。 WSL2 和本機 Windows 上啟動延遲的微基準 。
盡管在同步路徑中進行了優(yōu)化,但與本機 Windows 相比,在提交時啟動和同步的總開銷仍然更高。點 1 的 VMBUS 開銷導(dǎo)致了這一點,而不是同步路徑本身(圖 7 )。這種影響可以在圖 8 中看到,在圖 8 中,我們測量了一次發(fā)射的開銷,然后是同步。 VMBUS 引起的額外延遲是顯而易見的。
使提交調(diào)用異步并不一定完全消除啟動延遲成本。相反,它使您能夠通過同時執(zhí)行其他操作來抵消它。例如,一個應(yīng)用程序可以在一個流上通過管道進行多次啟動,前提是內(nèi)核啟動足夠長,可以覆蓋額外的延遲。在這種情況下,這一成本可以被隱藏起來,并設(shè)計成只有在一系列提交的開始時才可見。
簡而言之,我們已經(jīng)并將繼續(xù)改進和優(yōu)化 WSL2 的性能。盡管有到目前為止提到的所有優(yōu)化,但如果應(yīng)用程序在 GPU 上沒有管道化足夠的工作負載,或者更糟糕的是,如果工作負載太小,那么本機 Linux 和 WSL2 之間的性能差距將開始出現(xiàn)。這也是為什么 WSL2 和本機 Linux 之間的比較具有挑戰(zhàn)性,并且在不同的基準測試中差異很大。
假設(shè)應(yīng)用程序正在進行足夠多的流水線工作,以隱藏延遲開銷,并在應(yīng)用程序的整個生命周期內(nèi)保持 GPU 忙碌。使用當前的一組優(yōu)化,性能很可能接近甚至與本機 Linux 應(yīng)用程序相當。
當應(yīng)用程序提交的 GPU 工作負載不足以克服該延遲時,本機 Linux 和 WSL2 之間的性能差距將開始出現(xiàn)。間隔與總延遲和一次推送的工作大小之間的差異成正比。
這也是為什么,盡管在這方面做了很多改進,我們?nèi)詫⒗^續(xù)關(guān)注減少延遲,使其越來越接近本機 Linux 。
新的分配優(yōu)化
我們關(guān)注的另一個領(lǐng)域是內(nèi)存分配。與啟動延遲(只要應(yīng)用程序在 GPU 上啟動工作,啟動延遲就會影響性能)不同,內(nèi)存分配主要影響程序的啟動、加載和卸載階段。
這并不意味著它不重要;遠非如此。即使與僅提交 GPU 上的工作相比,這些操作并不頻繁,但相關(guān)的驅(qū)動程序開銷通常要高出一個數(shù)量級。一次分配幾兆字節(jié)最終需要幾毫秒才能完成。
為了優(yōu)化此路徑,我們的主要方法之一是在 CUDA 中啟用異步分頁操作。這種功能在 Windows 顯示驅(qū)動程序模型中已經(jīng)使用了一段時間,但 CUDA 驅(qū)動程序直到現(xiàn)在才使用它。此策略的主要優(yōu)點是,您可以退出分配調(diào)用,并將控制權(quán)交還給用戶代碼。您不必等待昂貴的 GPU 操作完成,例如更新頁表。相反,等待被推遲到引用分配的下一個操作。
這不僅可以改善 CPU 和 GPU 工作之間的重疊,而且還可以完全消除等待。如果分頁操作提前完成, CUDA 驅(qū)動程序可以通過監(jiān)聽映射的圍欄值來避免發(fā)出 OS 調(diào)用以等待分頁操作。在 WSL2 上,這一點尤為重要。只要避免調(diào)用主機內(nèi)核模式,就可以避免 VMBUS 開銷。
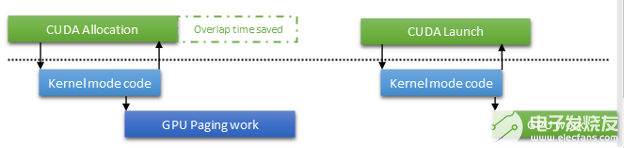
圖 9 。在 CUDA 驅(qū)動程序中完成的分配異步映射概述。
我們到了嗎?
在過去的幾個月里,我們在 WSL2 性能方面取得了長足的進步,現(xiàn)在我們看到許多基準測試的結(jié)果與本機 Linux 相當或接近。這并不意味著我們已經(jīng)達到了目標,我們將停止優(yōu)化驅(qū)動程序。一點也不!
首先,微軟目前正在研究硬件調(diào)度的未來優(yōu)化, MIG ht 使我們能夠?qū)娱_銷降至最低。同時,在這些功能完全開發(fā)之前,我們將繼續(xù)優(yōu)化 WSL 上的 CUDA 驅(qū)動程序,并為本機 Windows 提供建議。
其次,我們將關(guān)注通過某種特殊形式的內(nèi)存拷貝快速高效地分配內(nèi)存。我們還將很快開始研究 WSL2 上更好的多 GPU 功能和優(yōu)化,以使更密集的工作負載能夠快速運行。
WSL2 是 NVIDIA 完全受支持的平臺,它將獲得 CUDA 為其所有其他受支持平臺所努力提供的相同功能和性能重點。我們的目的是使 WSL2 性能更好并適合開發(fā)。我們還將使其成為一個 CUDA 平臺,它對每個用例都有吸引力,性能盡可能接近任何本機 Linux 系統(tǒng)。
最后,但并非最不重要的一點是,我們衷心感謝開發(fā)人員社區(qū)在過去一年中迅速采用 GPU 加速 WSL2 預(yù)覽、報告問題并不斷提供反饋。通過與我們分享我們 MIG ht 在其他方面錯過的性能用例,您幫助我們發(fā)現(xiàn)了潛在的問題,并在性能方面取得了長足的進步。如果沒有您堅定不移的支持, WSL2 上的 GPU 加速將不會達到今天的水平。我們期待著與社區(qū)進一步合作,努力實現(xiàn) CUDA 在 WSL2 上的未來里程碑。
要訪問驅(qū)動程序安裝程序和文檔,請注冊 NVIDIA 開發(fā)人員計劃 和 Microsoft Windows Insider 程序 。
以下資源包含有助于您了解 CUDA 如何使用 WSL2 的寶貴信息,包括如何開始運行應(yīng)用程序和深入學習容器:
WSL 上的 CUDA 下載頁面
WSL 用戶指南上的 CUDA
在 Linux 2 的 Windows 子系統(tǒng)上宣布 CUDA
GPU 在 Linux 的 Windows 子系統(tǒng)中加速了 ML 培訓
什么是 WSL ?
使用 WSL2 ( Linux 的 Windows 子系統(tǒng))在 Microsoft Windows 10 上運行 RAPIDS
關(guān)于作者
Raphael Boissel 領(lǐng)導(dǎo) Windows 平臺的 CUDA 工程。他擁有法國工程學院 EPITA 計算機科學碩士學位。
Arthy Sundaram 是 CUDA 平臺的技術(shù)產(chǎn)品經(jīng)理。她擁有哥倫比亞大學計算機科學碩士學位。她感興趣的領(lǐng)域是操作系統(tǒng)、編譯器和計算機體系結(jié)構(gòu)。
審核編輯:郭婷
-
cpu
+關(guān)注
關(guān)注
68文章
11277瀏覽量
224954 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135431 -
Linux
+關(guān)注
關(guān)注
88文章
11758瀏覽量
219009
發(fā)布評論請先 登錄
借助NVIDIA CUDA Tile IR后端推進OpenAI Triton的GPU編程
如何在NVIDIA CUDA Tile中編寫高性能矩陣乘法

NVIDIA CUDA Tile的創(chuàng)新之處、工作原理以及使用方法

NVIDIA CUDA 13.1版本的新增功能與改進
Hbirdv2 OpenOCD的編譯
keil無法寫入wsl文件怎么解決?
連接配備EZ-USB?的產(chǎn)品時出現(xiàn)Windows藍屏的當前狀態(tài)是怎么回事?
【Banana Pi BPI-RV2開發(fā)板試用體驗】配置WSL網(wǎng)絡(luò)環(huán)境訪問Github
淺談wsl --update` 命令行選項無效的解決方案
WSL 1 和 WSL 2 的區(qū)別是什么
計數(shù)器的當前值與設(shè)定值應(yīng)用
如何將FX3與WSL(Linux 的 Windows 子系統(tǒng))一起使用?
使用NVIDIA CUDA-X庫加速科學和工程發(fā)展
旺詮WSL系列合金電阻的低阻值如何實現(xiàn)高精度?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論