") 如何建設機器學習平臺,該如何去做
如何建設機器學習平臺,該如何去做

00. 平臺的業(yè)務
從平臺這個概念本身來說,它提供的是支撐作用,通過整合、管理不同的基礎(chǔ)設施、技術(shù)框架,一些通用的流程規(guī)范來形成一個通用的、易用的GUI來給用戶使用。通用性是它的考量之一、也是所有平臺的愿景之一:希望平臺能適用于各個不同的業(yè)務線來產(chǎn)生價值。所以從業(yè)務上來說,作為一個平臺本身是不會、也不應該有太多specific的業(yè)務功能的。當然這只是理想情況,有時候為了平臺使用方的需求,也不得不加上一些業(yè)務領(lǐng)域特定的功能或者補丁來適應業(yè)務方,特別是平臺建設初期,在沒有太多業(yè)務的使用的時候。整體來看,平臺自身的業(yè)務可謂是非常簡單,可以用一張圖來表示:
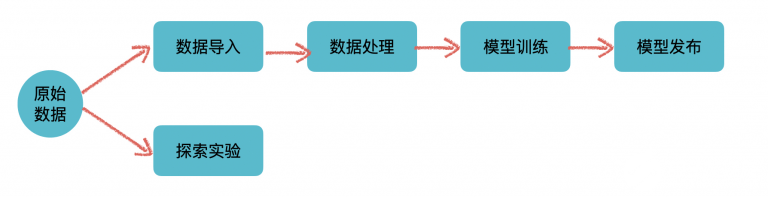
平臺的業(yè)務
上面這個分支是標準的機器學習流程的抽象。從數(shù)據(jù)準備,數(shù)據(jù)處理,模型訓練,再到模型上線實現(xiàn)價值完成整個流程。
下面這個分支,也是機器學習和數(shù)據(jù)科學領(lǐng)域中不可或缺的,主要指的是類似于Jupyter Notebook這類,提供高度靈活性和可視化的數(shù)據(jù)探索服務,用戶可以在里面進行數(shù)據(jù)探索、嘗試一些實驗來驗證想法。當然當平臺擁有了SDK/CLI之后,也可以在里面無縫集成上面這條線里面的功能,將靈活性與功能性融合在一起。
01. 基礎(chǔ)設施
上面提到平臺本身是整合了不同的基礎(chǔ)設施、技術(shù)框架和流程規(guī)范。在正式開始之前,有必要介紹下本文后續(xù)所使用的的基礎(chǔ)設施和框架。
在容器化、云化的潮流中,Kubernetes基本上是必選的基礎(chǔ)設施,它提供靈活易用的基礎(chǔ)設施和應用管理能力,同時擴展性非常好。它可以用于
部署平臺本身
調(diào)度一些批處理任務(這里主要指離線任務,如數(shù)據(jù)處理、模型訓練。適用的技術(shù)為:Spark on kubernetes/Kubernetes Job),
部署常駐服務(一般指的是RESTful/gRPC等為基礎(chǔ)的服務,如啟動的Notebook、模型發(fā)布后的模型推理服務。適用的技術(shù)為Kubernetes Deployment/Kubernetes Statefulset/Service等)。
機器學習的主要場景下,數(shù)據(jù)量都是非常大的,所以Hadoop這一套也是必不可少的,其中包含基礎(chǔ)的Hadoop(HDFS/HIVE/HBase/Yarn)以及上層計算框架Spark等。大數(shù)據(jù)技術(shù)體系主要用于數(shù)據(jù)存儲和分布式數(shù)據(jù)處理、訓練的業(yè)務。
最后就是一些機器學習框架,Spark系的(Spark MLlib/Angel),Python系的(Tensorflow/Pytorch)。主要用途就是模型訓練和模型發(fā)布(Serving)的業(yè)務。
02.原始數(shù)據(jù)
原始數(shù)據(jù),也叫做數(shù)據(jù)源,也就是機器學習的燃料。平臺本身并不關(guān)心原始數(shù)據(jù)是如何被收集的,只關(guān)心數(shù)據(jù)存儲的方式和位置。存儲的方式?jīng)Q定了平臺是否能支持此種數(shù)據(jù)的操作。存儲的位置決定了平臺是否有權(quán)限、有能力去讀取到此數(shù)據(jù)。按主流的情況來看,原始數(shù)據(jù)的存儲一般支持四類形式:
傳統(tǒng)的數(shù)據(jù)庫,例如RDS/NoSQL。這類數(shù)據(jù)源見得比較少,因為一般在大數(shù)據(jù)場景下,通用的解決方案是將此類數(shù)據(jù)源通過一些工具導入到大數(shù)據(jù)體系中(如Sqoop)。對于此類數(shù)據(jù)源的支持也是很簡單的,使用通用的Driver 或者 Connector即可。
以HDFS為媒介的通用大數(shù)據(jù)存儲。此類數(shù)據(jù)源使用較為廣泛,最常見的是HDFS文件(parquet/csv/txt)和基于HDFS的HIVE數(shù)據(jù)源。另外,由于是大數(shù)據(jù)場景下的經(jīng)典數(shù)據(jù)源,所以上層的框架支持較為完善。
NFS。NFS由于其快速的讀寫能力,以及悠久的歷史。很多企業(yè)內(nèi)部都有此基礎(chǔ)設施,因而已有的數(shù)據(jù)也極有可能存儲在上面。
OSS(對象存儲)。最過于流行的要屬S3了。對象存儲是作為數(shù)據(jù)湖的經(jīng)典方案,使用簡單,存儲理論上無限,和HDFS一樣具備數(shù)據(jù)高可用,不允許按片段更改數(shù)據(jù),只能修改整個對象是其缺點。
值得注意的是,NFS和OSS一般用于存儲非結(jié)構(gòu)化數(shù)據(jù),例如圖片和視屏。或者用于持久化輸出目的,如容器存儲,業(yè)務日志存儲。而HDFS和數(shù)據(jù)庫里面存放的都是結(jié)構(gòu)化、半結(jié)構(gòu)化的數(shù)據(jù),一般都是已經(jīng)經(jīng)過ETL處理過的數(shù)據(jù)。存儲的數(shù)據(jù)不一樣決定了后續(xù)的處理流程的區(qū)別:
NFS/OSS系數(shù)據(jù)源,基本上都是通過TensorFlow/Pytorch來處理,數(shù)據(jù)一般通過Mount或者API來操作使用。當然也有特例,如果是使用云服務,例如AWS的大數(shù)據(jù)體系的話,絕大多數(shù)場景下,是使用S3來代替HDFS使用的,這也得益于AWS本身對于S3的專屬EMRFS的定制化。當然Spark本身等大數(shù)據(jù)處理框架也是支持此類云存儲的。
HDFS系和傳統(tǒng)數(shù)據(jù)庫系數(shù)據(jù)源,這個大數(shù)據(jù)框架、Python系框架都是可以的。
平臺一般會內(nèi)嵌對以上數(shù)據(jù)源的支持能力。對于不支持的其他存儲,比如本地文件,一般的解決方案是數(shù)據(jù)遷移到支持的環(huán)境。
03.數(shù)據(jù)導入
這應該是整個平臺里較為簡單的功能,有點類似于元數(shù)據(jù)管理的功能,不過功能要更簡單。要做的是在平臺創(chuàng)建一個對應的數(shù)據(jù)Mapping。為保證數(shù)據(jù)源的可訪問,以及用戶的操作感知。平臺要做的事情可以分為三步:
訪問對應的數(shù)據(jù)源,以測試數(shù)據(jù)是否存在、是否有權(quán)限訪問。
拉取小部分數(shù)據(jù)作為采樣存放在平臺中(如MySQL),以便于快速展示,同時這也是數(shù)據(jù)本身的直觀展現(xiàn)(Sample)。對于圖片、視頻類的,只需要存儲元信息(如資源的url、大小、名稱),展示的時候通過Nginx之類的代理訪問展示即可。
如果是有Schema的數(shù)據(jù)源,例如Hive表,數(shù)據(jù)源的Schema也需要獲取到。為后續(xù)數(shù)據(jù)處理作為輸入信息。
技術(shù)上來說,平臺中會存在與各種存儲設施交互的代碼,大量的外部依賴。此時,外部依賴可能會影響到平臺本身的性能和可用性,比如Hive的不可用、訪問緩慢等,這個是需要注意的。
業(yè)務上來說,更多考量的是提高系統(tǒng)的易用性,舉個例子,創(chuàng)建Hive表數(shù)據(jù)源,是不是可以支持自動識別分區(qū),選擇分區(qū)又或者是動態(tài)分區(qū)(支持變量)等。
04.數(shù)據(jù)處理
這里的數(shù)據(jù)處理是一個大的概念,從我的認知上來看。大體可以分成兩個部分, 數(shù)據(jù)標注以及特征處理。
數(shù)據(jù)標注
數(shù)據(jù)標注針對是的監(jiān)督學習任務,目前機器學習的應用場景大多都是應用監(jiān)督學習任務習得的。巧婦難為無米之炊,沒有足夠的標注數(shù)據(jù),算法的發(fā)揮也不會好到哪兒去。對于標注這塊。業(yè)務功能上來說,基本上可以當成是另一套系統(tǒng)了,我們可以把它叫做標注平臺。但從邏輯關(guān)系上來說,標注數(shù)據(jù)是為了機器學習服務的。本質(zhì)上也是對數(shù)據(jù)的處理,所以劃到機器學習平臺里面也沒有什么問題。
標注平臺對應了之前提到平臺的另一功能:提供通用的流程規(guī)范。這里,流程指的是整個標注流程,規(guī)范指的是標注數(shù)據(jù)存儲的規(guī)范,比如在圖像領(lǐng)域,目前沒有通用而且規(guī)范的存儲格式,比較需要平臺來提供一種通用的存儲格式。
數(shù)據(jù)標注有兩種,一種是人工標注; 另一種是使用已訓練好的機器學習模型來標注,然后再輔以人工確定和修訂。無論是使用哪種方式,最后都需要人工介入。因為數(shù)據(jù)標注的正確性是非常重要的,大家應該都聽過一句話: 數(shù)據(jù)和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已。 如果給你的數(shù)據(jù)都是有問題的,那模型如何能學習到正確的能力呢。
在標注平臺中,往往都是人工+模型混合使用的,整體流程如下:
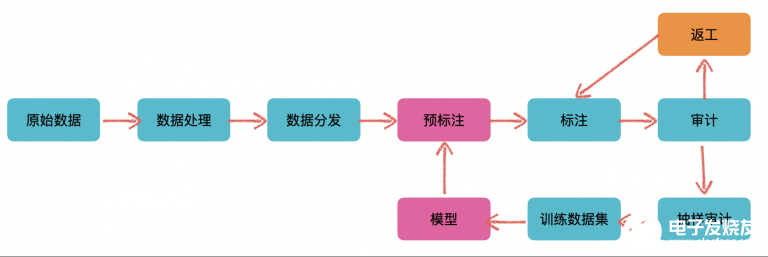
在標注平臺中,人工+模型混合使用
在最開始可能沒有模型來輔助進行標注(這里的預標注),這個時候就需要人為手工介入,以此來訓練出一個模型
當我們根據(jù)標注出的數(shù)據(jù)(訓練數(shù)據(jù)集)訓練出不錯的模型之后,就可以使用此模型來對新輸入的數(shù)據(jù)做一個預標注的工作,然后再輔以人工確認和修訂
如此反復迭代,隨著輸入數(shù)據(jù)的增多,當我們訓練出的模型準確率達到一個很高的水準之后,需要人工操作的數(shù)據(jù)就會越來越少。以此減少人工成本費
標注平臺中需要考量的問題有幾點:
一般來說,需要標注的數(shù)據(jù)量都是非常巨大的。不存在說兩三個人隨便標幾下就完事。所以更為通用的做法是做一個眾包平臺,外包給其他公司或者自由職業(yè)者(標注員)來做。參考AWS的Amazon Mechanical Turk。這就涉及到了權(quán)限控制、角色控制。
標注數(shù)據(jù)的準確性問題。不能避免有些標注員劃水摸魚,隨意標注。此時是需要己方人員去做一個審計工作的,這里就是一個工作流,和上圖所示差不多。是一個相對來說較為規(guī)范的流程,可以隨著業(yè)務來增加額外的流程。
標注工具的開發(fā)。如果有合適開源工具,可以集成開源工具,如VGG-VIA/Vatic, poplar。開源工具一般不會滿足所有的需求,在開源上做二次開發(fā)往往成本更高。這里更傾向于自己開發(fā),這樣更能滿足需要,自定義程度高,靈活性強
標注數(shù)據(jù)的存儲。最好是一個相對通用的格式,以便于往各種其他格式做一個轉(zhuǎn)換。在使用時做一個數(shù)據(jù)格式轉(zhuǎn)換。這里更偏好Json格式類似的存儲,可讀性和代碼可操作性都非常高
技術(shù)上的考量,這里并不是太多。唯一需要注意的可能是數(shù)據(jù)的處理,如圖片、視頻標注,資源的拆剪、縮放,各種標注數(shù)據(jù)的保存,坐標計算等。相對而言,后端主要是工作流處理,前端的各種標注工具是技術(shù)核心點。
特征處理
在正式開始模型構(gòu)建與訓練之前,對數(shù)據(jù)做特征處理基本上是必不可少的環(huán)節(jié)。特征處理的輸入是之前創(chuàng)建的數(shù)據(jù)集、或者是標注完成后產(chǎn)生的數(shù)據(jù)集。它的輸出是經(jīng)過一系列數(shù)據(jù)操作后、可以直接輸入到模型中的數(shù)據(jù),這里稱它為訓練數(shù)據(jù)。
這里又可以分為兩類,一類是不需要太多操作的特征處理,常見于非結(jié)構(gòu)化數(shù)據(jù),如圖片、視屏。另一類是針對結(jié)構(gòu)化/半結(jié)構(gòu)化數(shù)據(jù)的特征處理流程,這類數(shù)據(jù)往往不是拿來即可用的,需要一定的特征處理。
首先來看第一類,第一類的典型應用場景就是CNN圖像領(lǐng)域。對于輸入的圖片,一般不需要太多的操作。此類數(shù)據(jù)源往往也是存儲在NFS/OSS上的。對于此類數(shù)據(jù)的處理,一般也不會使用到大數(shù)據(jù)框架,一般都是自己手擼Python(C++)來處理;或者是放在模型訓練一起處理,不單獨拎開。Spark2.3開始是支持圖片格式的,不過目前沒有看到太多的使用案例。整體流程如下:

CNN圖像領(lǐng)域
本質(zhì)上是一個批處理過程,Kubernetes的Job天然適用于此類問題。當然其他調(diào)度框架來做這個任務調(diào)度也是可以的。
然后是第二類,這種基本上就是傳統(tǒng)的特征工程了,以Hive/HDFS輸入為經(jīng)典例子。由于對數(shù)據(jù)的操作是非常多樣的,所以一般傾向于構(gòu)建一個數(shù)據(jù)處理的流水線,也就是Pipeline:

傳統(tǒng)的特征工程
把對數(shù)據(jù)的操作拆分成一個一個的操作運算(也就是一個Pipeline Node節(jié)點),可以把它叫做算子,然后利用Pipeline把操作進行自由組合,從而達到對數(shù)據(jù)進行各種變換處理的過程。使用過Sklearn pipeline或者Spark MLlib pipeline的小伙伴應該對此并不陌生,事實上,這就是基于此的可視化建模。使得用戶可以在界面上進行拖拉拽,選擇和輸入一些參數(shù)來完成對于數(shù)據(jù)的操作,提供更靈活的功能。
那么這條Pipeline里面都有哪些操作呢,整個算子大致可以分為這幾類別:
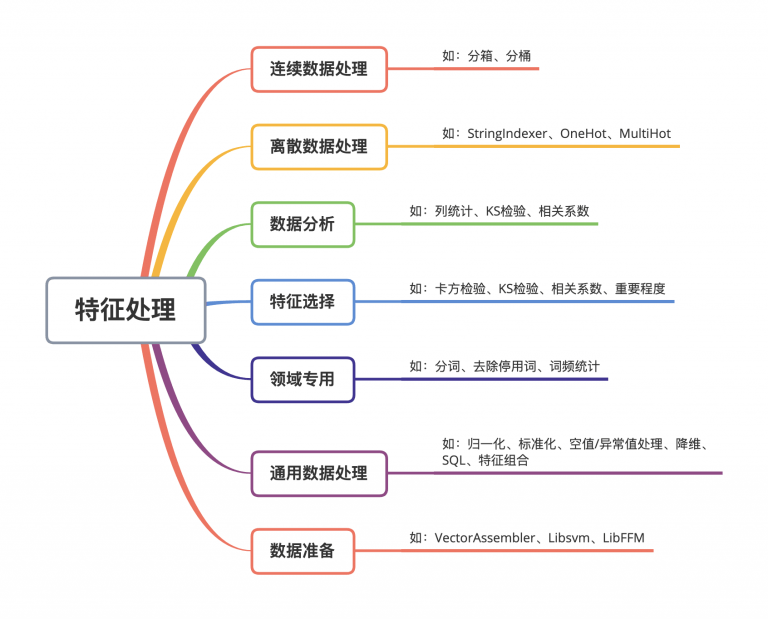
特征處理
技術(shù)上,使用Spark MLlib是個不錯的選擇,可以適應不同數(shù)據(jù)量的規(guī)模。且天然支持這種Pipeline的形式,只需要對此做一定的封裝。同時,考慮到業(yè)務功能,還需要手動定制、修改一些算子;對于擴展這點,它的支持也是非常不錯的,自定義算子、算法都比較簡單。當然也可以基于其他框架(如Azkaban)或者自己造輪子。需要注意的是,在大數(shù)據(jù)場景下,Spark MLlib里面部分自帶的算子會有性能問題(有些直接OOM),需要分析源碼定位然后修復。包括我們自己實現(xiàn)的算子,也都要考量大數(shù)據(jù)場景下這個問題,這對于測試而言是個Case。
整個Pipeline的核心是構(gòu)造一個DAG,解析后,提交給對應的框架來做處理。拋開技術(shù)來說,功能上來說,易用性和快速反饋是Pipeline需要注意的。比如:
所有的算子都應該能自動獲取到可用的輸入、對應類型,自動生成輸出
支持參數(shù)校驗,Pipeline完整性校驗
支持調(diào)試/快速模式,利用部分Sample data快速驗證效果,相當于一個試驗功能
日志查看,每個算子狀態(tài)查看,以及操作完成后的Sample data查看
支持一些變量、SQL書寫,以擴展更靈活的功能,比如參數(shù)動態(tài)化
支持定時調(diào)度,任務狀態(tài)郵件、短袖及時告警、同步等
05.模型訓練
到了模型訓練這塊。從功能上來看需要的不是很多,更多是體驗上的設計。比如參數(shù)在界面上的展示和使用,日志、訓練出的Metrics的可視化、交互方式,模型的一些可視化等。核心功能包含這幾塊兒:
1.預置算法/模型
這里考量的點是:
支持界面手動調(diào)參
訓練中日志、Metrics的可視化。支持同時使用不同的參數(shù)多次訓練,直觀對比結(jié)果方便調(diào)參
需要支持常用的框架,如Spark MLlib/Tensorflow/Pytorch,或者一些特定的框架(業(yè)務方需要的)
預置算法/模型很簡單,在不同的框架上封裝一層并且暴露對應的參數(shù)給到用戶即可。有些算法可能框架不支持,這種根據(jù)情況決定如何解決(自己實現(xiàn)或者其他解決方案)。有一點就是,框架不宜太多,否則在后續(xù)模型發(fā)布的Serving上,也需要多套解決方案。對于訓練本身來說,分為兩種:單體/單機訓練和分布式訓練,分布式訓練是訓練這塊的大頭(也是技術(shù)難點所在)。
對于單體/單機訓練的解決方案,和上訴特征處理中的解決方案一致。優(yōu)先使用Kubernetes的Job,或者使用Spark,控制下Executor即可。
對于分布式訓練,目前接觸到的,基本上都是數(shù)據(jù)并行:
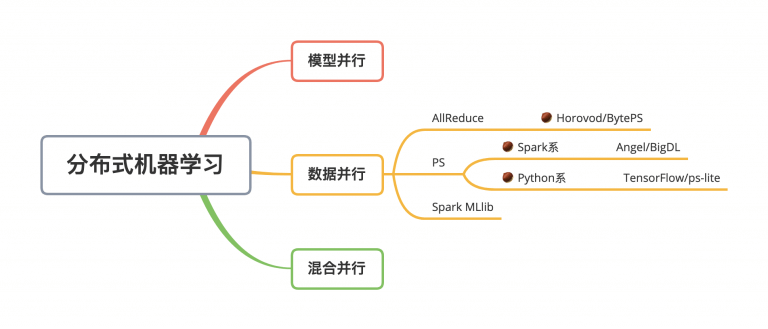
分布式機器學習
以Spark為基礎(chǔ)的基本都使用的是PS模式。PS模式一般使用的都是異步更新參數(shù),每個Worker只需要和PS通信,所以容錯管理上會更加簡單。AllReduce模式則是同步的參數(shù)模式,而且每個Worker都需要上下游通信,相對而言,容錯處理會更苛刻一些。
Spark系的分布式訓練,經(jīng)典的算法可以由Spark MLlib提供。但是其對于DNN的支持并不好,而且Spark的訓練是一個同步的過程,如果數(shù)據(jù)傾斜的話,整個訓練的速度取決于最慢的RDD。如果要在Spark上跑深度學習的模型,一般會選用其他框架或者基于Spark的框架,如騰訊的Angel、 Intel的BigDL。兩者的思想都是一致的,同屬于PS模式下的分布式訓練,整個流程可以概括為這幾步:
利用Spark來作為任務調(diào)度、資源分配、數(shù)據(jù)讀取和容錯處理的容器
從PS拉取參數(shù),然后將數(shù)據(jù)和參數(shù)通過JNI喂到底層的框架代碼中去(如Pytorch C++ Frontend)完成訓練,返回梯度
使用優(yōu)化算法和梯度,更新參數(shù),再將新的參數(shù)更新到PS。如此反復
借用一張Angel的圖:
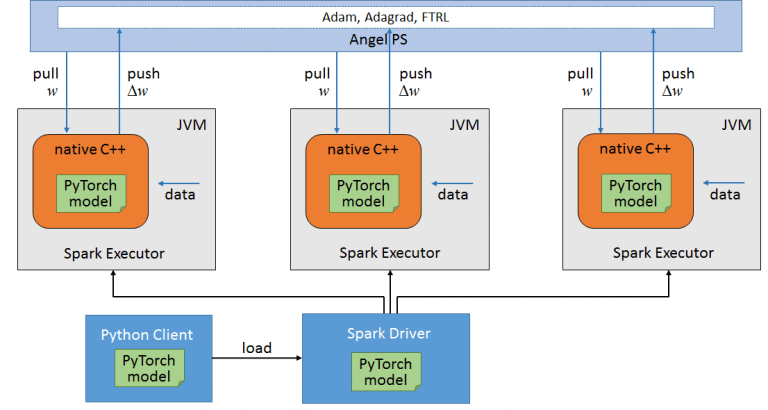
Angel的圖
順著這個思路,可以以Spark為基礎(chǔ),兼容任何深度學習框架。只要底層框架:
支持模型/代碼序列化,以支持分發(fā)模型到所有Worker中進行本地訓練
通過JNI能調(diào)用模型提供的接口,如Forward/Backward
這要比自己造輪子更加便利和友好,畢竟Spark已經(jīng)是一個成熟的分布式計算框架了。
如果使用的是Python系的深度學習框架有兩點需要注意:
如何讀取分布式存儲上的數(shù)據(jù)以支持數(shù)據(jù)并行。也就是Spark里面Partition的概念。當然最簡單的方法,就是將數(shù)據(jù)拆分成塊,不同的節(jié)點讀取不同的數(shù)據(jù)來訓練。
另外一點在于容錯性,基于Spark的分布式訓練的優(yōu)勢就在于數(shù)據(jù)的分配、容錯處理。現(xiàn)在就得自己去保障這兩點了。
訓練部署上面。Spark系的,使用Spark支持的即可(Yarn/Kubernetes/Standalone)。Python系的更傾向于云原生、或者基于Kubernetes的解決方案(自定義Operator是個比較好的選擇),這里有個為云原生和容器化而生的框架:Polyaxon,值得一試。
2. 自定義算法
關(guān)于自定義算法,個人更傾向于將這個功能放在Notebook中而不是界面化的操作上,因為這個功能的自由度很高,允許用戶自己寫代碼。平臺其實只需要提供:
數(shù)據(jù)讀取能力,這里包括源數(shù)據(jù)、平臺內(nèi)生成的數(shù)據(jù)
NFS/OSS使用Mount形式或者API提供(如Databricks 的DBFS)
HDFS系列的API提供支持(如提供pyspark)
調(diào)度能力,能根據(jù)需求調(diào)度起任務。
以上兩者功能,都或多或少依賴于SDK/API/CLI。可以參考大廠的實現(xiàn)Amazon SageMaker、Databricks Notebooks。
另外一點是GPU的支持,這點,如果是選擇Kubernetes作為基礎(chǔ)設施,是有基本的功能支持的,利用Extended Resource(ER)配合 Device plugin體系:
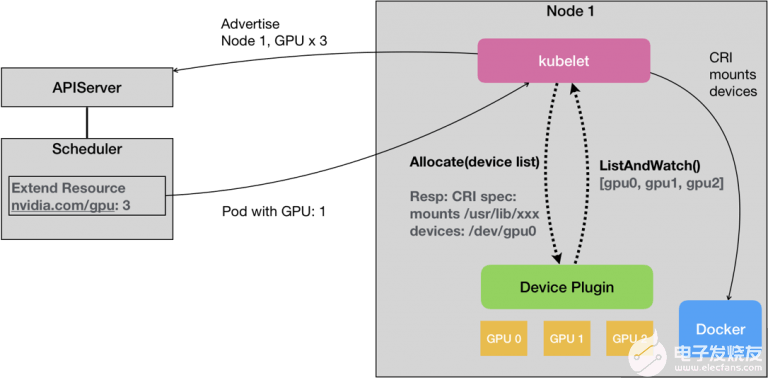
Extended Resource(ER)配合 Device plugin體系
對于Hadoop體系的話,3.1.X之后也是支持的。
這兩者對于GPU的支持都非常有限,都是處于一個能用,但是不好用的狀態(tài)。使用的時候,淌坑可能在所難免。
3. AutoML
關(guān)于AutoML這塊。目前還沒有太多的接觸。從我看來,做個簡單的隨機搜索還是問題不大的,集成算法來自動調(diào)參、自動構(gòu)建模型也是不難的。就跟上訴集成算法進來是一樣的。唯一考量的是,集成那些算法進來以及計算資源的考量,尤其是深度學習大行其道的今天,類似于隨機搜索這樣耗費的資源是巨大的。如何設計這個功能,以及具體實現(xiàn)還是需要非常專業(yè)的領(lǐng)域知識。
總的來說,模型訓練這塊。是一個很偏技術(shù)的功能。完成一個Demo的端到端,實現(xiàn)基本的功能很簡單。但是要做到好用、穩(wěn)定性這兩點就并不那么容易。尤其是分布式機器學習這一塊兒,還是需要不斷淌坑的。
06.模型發(fā)布
終于來到最后一步,是整個平臺產(chǎn)生價值的最后一環(huán)。模型發(fā)布,通常包含兩種發(fā)布:
發(fā)布成API(RESTful/gRPC),以供業(yè)務側(cè)實時調(diào)用。這類服務通常對于性能要求苛刻
發(fā)布成批處理形式,用于批處理數(shù)據(jù),上述標注平臺中的預標注屬于此類任務
對于批處理形式的發(fā)布,較為簡單。一般框架本身都支持模型的序列化和加載做預測:
Spark系的就依舊走原始路線,提交Spark Job,做批處理預測
TensorFlow類似的,配合不同的鏡像環(huán)境,Mount模型,讀取數(shù)據(jù),配合Kubernetes Job的方式來啟動批處理達到一個統(tǒng)一的處理流程
對于實時推理服務,于平臺而言,能使用通用的框架/技術(shù)來做那當然是極好的。然鵝,現(xiàn)實很殘酷。通用的解決方案,要么性能不夠(如MLeap),要么支持的算子/操作/輸入有限(如ONNX。想要在真正的業(yè)務場景下發(fā)揮價值都是需要淌坑的。用的更多的,往往都是性能領(lǐng)域強悍的C/C++/RUST來實現(xiàn),比如自研、或者框架本身自帶的(如TensorFlow的Serving),會更能滿足性能需求。平臺選用的框架最好是不要太多,這樣做Serving會比較麻煩,不同的框架都要去找解決方案實現(xiàn)一遍。
雖然做不到通用的模型Serving方案,但是通用的模型發(fā)布、提供服務的平臺卻是可以做到的。這是這部分的重點,即如何設計一個通用的推理平臺。一個推理平臺需要考量的點如下所示:
支持各種框架,多語言、多環(huán)境
模型版本管理
API安全性
可用性、可擴展性,服務狀態(tài)監(jiān)控、動態(tài)擴容
監(jiān)控、告警,日志可視化
灰度上線/AB Testing
把Serving看做是普通的Web服務。對于上訴的點,Kubernetes體系是絕佳的選擇:
鏡像,配合NFS的模型,啟動時Mount再復制到容器內(nèi)部。可以支持多語言、多環(huán)境
版本管理,每個版本在NFS上創(chuàng)建新的版本目錄,比如0.0.1,放入對應的模型和啟動腳本配合一個Service。這樣就允許不同版本的Service同時在線,或者部分在線
API安全性,與Kubernetes本身無關(guān)。簡單的做法是為每個API生成對應的調(diào)用Token來做鑒權(quán),或者使用API網(wǎng)關(guān)來做
可用性、可擴展性。利用Kubernetes原生的Liveness/Readness probe,可以檢測單個Pod中服務的狀態(tài)。使用Kubernetes的HPA、或者自己實現(xiàn)監(jiān)控再配合Autoscale可以滿足需求,而且這些都可以成為一些配置暴露給用戶
監(jiān)控、告警。可以Prometheus+Grafana+Alertmanager三件套,或者配合企業(yè)內(nèi)部的運維體系
交給Istio即可。灰度發(fā)布肯定妥妥的,利用一些Cookie/Header來做分流到不同版本的服務也可以做到部分AB Testing的事情
由于Serving服務與服務之間是沒有關(guān)系的,是一個無狀態(tài)的單體服務。對于單體服務的各種處理就會比較簡單。比如不使用Kubernetes,使用AWS云的EC2來部署,配合Auto Scaling、CloudWatch等也是非常簡單的。
07. Addons
除開上訴的核心功能。一般來說,機器學習平臺還有一些擴展。最經(jīng)典的當屬CLI和SDK了。
CLI就不用多說了,主要提供快捷入口。可以參考AWS的CLI。需要包含的點主要是:
提供基本的操作功能,滿足用戶的使用
以及導入導出功能。方便用戶共享配置、快速創(chuàng)建和使用平臺的功能
支持多環(huán)境、認證
完善的操作使用文檔、幫助命令、模板文件等
對于SDK這塊,需要和平臺本身的功能做深度集成;同時,還需要一定的靈活性。比如上訴的自定義算法,用戶可以在Notebook里面讀取平臺生成的數(shù)據(jù)集,寫完代碼后,還得支持提交分布式訓練。既要集成平臺功能,又得支持一定程度的自定義,如何設計會是一個難點。
08.探索實驗(Notebook)
Notebook本身功能并不復雜。實質(zhì)上就是對Jupyter Notebook/JupyterLab等的包裝。通常的做法是使用Kubernetes的Service,啟動一個Notebook。以下幾點是需要考量的:
存儲要能持久化,需要引入類似于NFS這樣的持久目錄以供用戶使用
內(nèi)置Demo,如讀取平臺數(shù)據(jù)、訪問資源、提交任務
預置不同的鏡像,支持不同的框架,以及CPU/GPU訴求用于啟動不同的Notebook
安全問題,一個是Notebook本身的安全。另一個是容器本身的安全
有可用的安全源,以供用戶安裝和下載一些包和數(shù)據(jù)
能夠訪問到基礎(chǔ)設施里面的數(shù)據(jù),Mount/API
最好能有Checkpoint機制,不用的時候回收資源。需要的時候再啟動,但環(huán)境不變
大致的解決思路如下:
持久化需要Mount存儲。Storage class可以幫助
Notebook自身的安全,可以在里面增加Handler或者外面配置一層Proxy來鑒權(quán)。容器的安全大概有這幾點需要考量(要做到更嚴格還有很多可以深挖):
限制容器內(nèi)部用戶的權(quán)限
開啟SELinux
Docker的—cap-add/—cap-drop
heckpoint機制的實現(xiàn),數(shù)據(jù)已經(jīng)持久化在外部存儲了。只需要Save新的鏡像,作為下次啟動的鏡像即可,可使用Daemonset+Docker in dokcer的形式做一個微服務來提交鏡像。
09. 平臺的基石
這一節(jié)主要討論的是做平臺一定繞不開的問題。首先逃脫不了的是多租戶問題:
可能要和已有的系統(tǒng)進行集成。而不是新開發(fā)
租戶間權(quán)限、數(shù)據(jù)隔離
租戶資源配額、任務優(yōu)先級劃分
技術(shù)上來說,系統(tǒng)自身的租戶功能難度不高。主要是數(shù)據(jù)、資源隔離這塊。要看對應的基礎(chǔ)設施:
Hadoop可以使用Keberos
Kubernetes可以使用Namespace
再配合不同的調(diào)度隊列。即可完成需求。
另外一點是偏技術(shù)層面的調(diào)度功能。這可以算是整個平臺運行的基礎(chǔ),無論是數(shù)據(jù)處理還是模型訓練、模型部署都依賴于此, 調(diào)度系統(tǒng)分為兩塊:
調(diào)度本身,即如何調(diào)度不同的任務到不同的基礎(chǔ)設施上
狀態(tài)管理,有些任務可能存在依賴關(guān)系,會觸發(fā)不同的Action。這也是一個狀態(tài)機的問題
狀態(tài)管理這塊,業(yè)務場景不復雜的情況下自己實現(xiàn)即可。一般平臺上也沒有太復雜的依賴關(guān)系,經(jīng)典的模型訓練也不過單向鏈路而已。如果過于復雜,可以考慮其他開源任務編排工具:

狀態(tài)管理
調(diào)度本身是一個任務隊列+任務調(diào)度組合而成。隊列用啥都可以,數(shù)據(jù)庫也可以。只要能保證多個Consumer的數(shù)據(jù)一致性即可。任務調(diào)度,如果不考慮用戶的感受,可以直接丟給對應的基礎(chǔ)設施,如Yarn/Kubernetes都可以。由這些基礎(chǔ)設施來負責調(diào)度和管理,這樣最簡單。
如果想做的盡善盡美,那還是需要維護一個資源池。同步基礎(chǔ)設施的使用情況,然后根據(jù)剩余資源和任務優(yōu)先級來做調(diào)度。
狀態(tài)更新方面。對于Yarn體系,只能通過API去輪詢狀態(tài)、獲取日志。
對于Kubernetes體系,推薦一個Informer機制,通過List&Watch機制可以方便、快速獲取整個集群的情況:
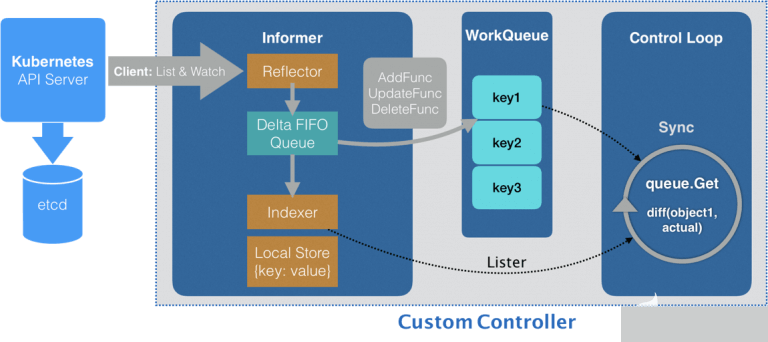
Custom Controller
關(guān)于如何提交任務到基礎(chǔ)設施:
Spark/Yarn - 直接API、包裝下命令行者Livy都可
Kubernetes - SDK
10.最終Boss
做平臺,最怕的是什么?當然不是某某技術(shù)太過于復雜,攻克不下。而是沒有用戶使用平臺,或者不能通過平臺產(chǎn)生真實業(yè)務價值,這才是最重要的。有某一業(yè)務場景在平臺實現(xiàn)端到端產(chǎn)生價值,才能證明這個平臺的價值,才能吸引其他用戶來使用。
對于用戶來說,一般都已經(jīng)有自己成熟的技術(shù)線。想要他們往平臺上遷移,實屬不易,除非已有系統(tǒng)滿足不了他們的需求、或者已有系統(tǒng)不好用。畢竟,自己用的好好的系統(tǒng),遷移是需要耗時耗力的,用別人的東西也沒有自己做來的靈活;學習一個新的系統(tǒng)使用也是如此,有可能一開始用著并不習慣。此外,新的系統(tǒng),沒有人期望第一個來當小白鼠的。有這么多缺點,當然平臺本身也有其優(yōu)點。比如將基礎(chǔ)設施這塊甩給了第三方,不用去關(guān)注底層的東西,只要關(guān)注自己的業(yè)務了。
事實上的流程往往都是,隨著平臺MVP的發(fā)布。部分用戶開始上來試用,然后提各種想法和需求;緊接著,會逐漸遷移部分功能上來試用,比如搞些數(shù)據(jù)上來跑跑Demo,看看訓練的情況等。同時,在這個階段,就會需要各種適配用戶原始的系統(tǒng)了,比如原始數(shù)據(jù)導入與現(xiàn)有系統(tǒng)不兼容,需要格式的轉(zhuǎn)換;再比如只想用平臺的部分功能,想集成到自己現(xiàn)有的系統(tǒng)中等。最后才是,真正的在平臺上使用。想要用戶能端到端的使用平臺,來完成他們的業(yè)務需求,還是需要漫長的過程的。
相對而言,至上而下的推動往往更為有效。總有一批人要先來體驗、先來淌坑,給出建議和反饋。這樣這個平臺才會越來越好,朝好的地方發(fā)展。而不是一開始上來就堆功能,什么炫酷搞什么、大而全。但是在用戶使用上,易用性和穩(wěn)定性并不好,或者是并不能解決用戶的需求和難點。那這種平臺是活不下去的。
fqj
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
4019瀏覽量
68340 -
機器學習
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136936
發(fā)布評論請先 登錄
自動駕駛中常提的模仿學習是什么?
機器學習和深度學習中需避免的 7 個常見錯誤與局限性

光伏智慧管控平臺建設的原則
如何在機器視覺中部署深度學習神經(jīng)網(wǎng)絡

光伏電站數(shù)字孿生平臺建設的核心流程

農(nóng)村供水智慧化管理平臺怎么建設?
黑芝麻智能AI全棧機器人計算平臺榮膺國際大獎
NVIDIA助力構(gòu)建人形機器人全身遙操作仿真平臺
FPGA在機器學習中的具體應用
海微科技入選2025年省級制造業(yè)中試平臺培育建設名單
機器人主控芯片平臺有哪些 機器人主控芯片一文搞懂

面向AI與機器學習應用的開發(fā)平臺 AMD/Xilinx Versal? AI Edge VEK280
工業(yè)機器人工作站的建設意義
AgiBot World Colosseo:構(gòu)建通用機器人智能的規(guī)模化數(shù)據(jù)平臺




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論