 存儲與GPU性能皆已成倍增長,IO表現為何遲遲不見好轉?
存儲與GPU性能皆已成倍增長,IO表現為何遲遲不見好轉?

存儲與GPU性能皆已成倍增長,IO表現為何遲遲不見好轉?
伴隨著HPC、自動駕駛、深度學習和VR/AR需求的不斷增加,IO性能也在逐步凸顯瓶頸,尤其是GPU與存儲之間的讀寫。處理器速度已經從KHz進化至了GHz,VRAM從KB進化至了GB,IO速度也從KB/s進化至了GB/s,然而GB/s的大幅度改善從直觀角度來看依然像是MB/s。
比如在有線連接的VR應用中,圖形需要經過電腦進行處理,再經有線傳輸顯示在VR屏幕上,這就引發了高延遲和長讀取時間等問題。這不禁讓人開始遐想,在CPU、GPU和存儲都已經革新換代的情況下,我們是否真正有效地應用了硬件性能?為此微軟和英偉達都提出了直接存儲的概念來改善IO的現狀。
微軟:Windows上的DirectStorage
微軟在不久前的Windows 11發布會上重點提到了DirectStorage技術,這是一個最初為主機設計的DirectX API,如今微軟也將把這一技術帶到PC上。
在當前NVMe SSD和PCIe技術的演進下,存儲帶寬遠超舊式的硬盤存儲技術,過去10MB每秒的速度已經達到數GB每秒。但PC上的圖形工作量也在逐步進化,數據量的增加對于讀取提出了更高的要求。過去大量數據的讀取只需要少量的IO請求,但如今的圖形渲染會將材質等資源分成小塊,只有在場景提出要求時載入所需的部分,如此一來雖然提高了效率,卻引入了更多IO請求。

當前的GPU資源讀取流程 / 微軟
而目前的存儲API并沒有對大量IO請求作出優化,因此拖累了NVMe,使得讀寫瓶頸愈發明顯。即便采用高端的PC硬件,也無法飽和利用存儲帶寬優勢。除此之外,這些數據往往需要經過壓縮傳輸下一個環節,傳入內存后,還要CPU進行一部分解壓工作,最后再傳入GPU顯存里,這樣一來每個節點都存在效率損失。
而DirectStorage采用了全新的路徑,從存儲讀取的數據傳給內存后,直接傳給GPU顯存。而GPU對于這些數據的解壓速度遠快于CPU,所以極大地優化了IO性能。
英偉達:RTX IO和Magnum IO GPUDirect Storage
英偉達在RTX 30系列顯卡上引入了RTX IO,面向消費市場,提升游戲場景下的讀取速度。英偉達稱RTX IO將與微軟的DirectStorage結合,與傳統硬盤下的存儲API相比,可將IO性能提高百倍。過去需要數十個CPU內核的工作全部交由RTX GPU來處理。
值得一提的是,英偉達的RTX IO雖然也用到了微軟的DirectStorage,但該技術并沒有將數據傳輸到內存,而是直接由SSD轉向GPU。微軟一名圖形開發者在GSL 2021大會上表示,未來DirectStorage的目標也是繞過系統內存。
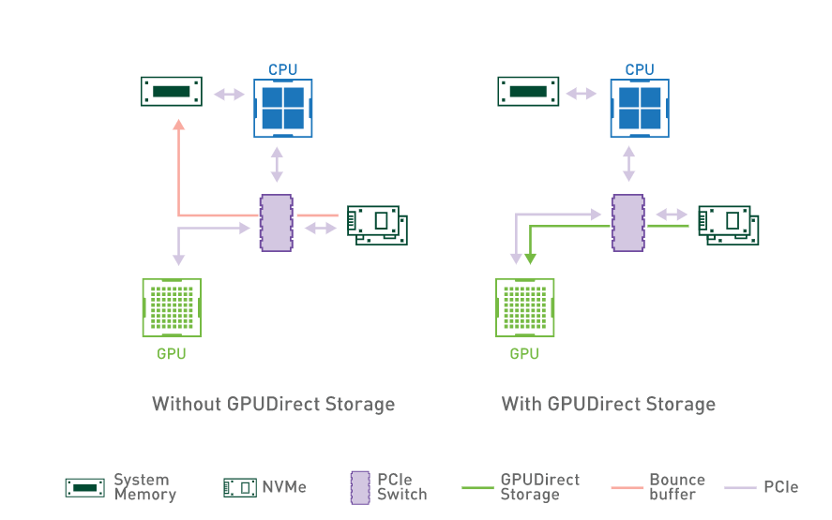
GDS技術 / 英偉達
除了消費市場外,英偉達在HPC市場也推出了對應的直接存儲技術,Magnum IO GPUDirect Storage(GDS)。GDS技術同樣是一個繞過CPU的技術,與消費級GPU不同,HPC場景下往往要用到多塊GPU,如此一來受IO延遲和CPU的影響更大。GDS在本地存儲與GPU顯存之間建立直接的數據通道,消除了CPU引入的延遲和讀寫瓶頸。
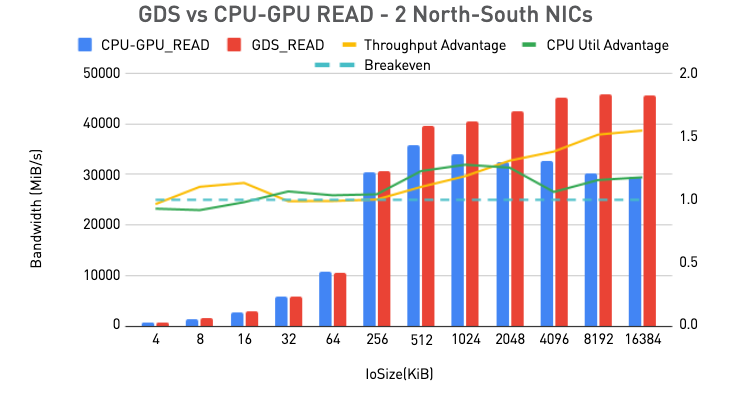
GDS與CPU傳輸至GPU讀取性能對比 / 英偉達
在運用GDS后,帶寬提升達到1.5倍,與傳統CPU回彈緩沖的數據路徑相比,CPU利用率也有2.8倍的提升。
目前英偉達已經將這一技術加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已經開始了相關產品的量產,而IBM、美光等五家廠商也在積極引入這一技術。三星、鎧俠、西數和戴爾等廠商也開始了GDS的早期集成與認證計劃。
小結
直接存儲技術進一步放大了GPU廠商與存儲廠商的優勢,目前HPC市場前景巨大,英偉達在相關業務上的盈利已經讓其看到了商機。不僅是GPU,英偉達采用Arm架構的Grace CPU同樣引入了NVLink這樣的數據傳輸改善方案。在這樣的性能改善下,即便存儲方案不同,英偉達的GPU也很可能成為HPC應用的首選。
伴隨著HPC、自動駕駛、深度學習和VR/AR需求的不斷增加,IO性能也在逐步凸顯瓶頸,尤其是GPU與存儲之間的讀寫。處理器速度已經從KHz進化至了GHz,VRAM從KB進化至了GB,IO速度也從KB/s進化至了GB/s,然而GB/s的大幅度改善從直觀角度來看依然像是MB/s。
比如在有線連接的VR應用中,圖形需要經過電腦進行處理,再經有線傳輸顯示在VR屏幕上,這就引發了高延遲和長讀取時間等問題。這不禁讓人開始遐想,在CPU、GPU和存儲都已經革新換代的情況下,我們是否真正有效地應用了硬件性能?為此微軟和英偉達都提出了直接存儲的概念來改善IO的現狀。
微軟:Windows上的DirectStorage
微軟在不久前的Windows 11發布會上重點提到了DirectStorage技術,這是一個最初為主機設計的DirectX API,如今微軟也將把這一技術帶到PC上。
在當前NVMe SSD和PCIe技術的演進下,存儲帶寬遠超舊式的硬盤存儲技術,過去10MB每秒的速度已經達到數GB每秒。但PC上的圖形工作量也在逐步進化,數據量的增加對于讀取提出了更高的要求。過去大量數據的讀取只需要少量的IO請求,但如今的圖形渲染會將材質等資源分成小塊,只有在場景提出要求時載入所需的部分,如此一來雖然提高了效率,卻引入了更多IO請求。
當前的GPU資源讀取流程 / 微軟
而目前的存儲API并沒有對大量IO請求作出優化,因此拖累了NVMe,使得讀寫瓶頸愈發明顯。即便采用高端的PC硬件,也無法飽和利用存儲帶寬優勢。除此之外,這些數據往往需要經過壓縮傳輸下一個環節,傳入內存后,還要CPU進行一部分解壓工作,最后再傳入GPU顯存里,這樣一來每個節點都存在效率損失。
而DirectStorage采用了全新的路徑,從存儲讀取的數據傳給內存后,直接傳給GPU顯存。而GPU對于這些數據的解壓速度遠快于CPU,所以極大地優化了IO性能。
英偉達:RTX IO和Magnum IO GPUDirect Storage
英偉達在RTX 30系列顯卡上引入了RTX IO,面向消費市場,提升游戲場景下的讀取速度。英偉達稱RTX IO將與微軟的DirectStorage結合,與傳統硬盤下的存儲API相比,可將IO性能提高百倍。過去需要數十個CPU內核的工作全部交由RTX GPU來處理。
值得一提的是,英偉達的RTX IO雖然也用到了微軟的DirectStorage,但該技術并沒有將數據傳輸到內存,而是直接由SSD轉向GPU。微軟一名圖形開發者在GSL 2021大會上表示,未來DirectStorage的目標也是繞過系統內存。
GDS技術 / 英偉達
除了消費市場外,英偉達在HPC市場也推出了對應的直接存儲技術,Magnum IO GPUDirect Storage(GDS)。GDS技術同樣是一個繞過CPU的技術,與消費級GPU不同,HPC場景下往往要用到多塊GPU,如此一來受IO延遲和CPU的影響更大。GDS在本地存儲與GPU顯存之間建立直接的數據通道,消除了CPU引入的延遲和讀寫瓶頸。
GDS與CPU傳輸至GPU讀取性能對比 / 英偉達
在運用GDS后,帶寬提升達到1.5倍,與傳統CPU回彈緩沖的數據路徑相比,CPU利用率也有2.8倍的提升。
目前英偉達已經將這一技術加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已經開始了相關產品的量產,而IBM、美光等五家廠商也在積極引入這一技術。三星、鎧俠、西數和戴爾等廠商也開始了GDS的早期集成與認證計劃。
小結
直接存儲技術進一步放大了GPU廠商與存儲廠商的優勢,目前HPC市場前景巨大,英偉達在相關業務上的盈利已經讓其看到了商機。不僅是GPU,英偉達采用Arm架構的Grace CPU同樣引入了NVLink這樣的數據傳輸改善方案。在這樣的性能改善下,即便存儲方案不同,英偉達的GPU也很可能成為HPC應用的首選。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
微軟
+關注
關注
4文章
6741瀏覽量
107852 -
gpu
+關注
關注
28文章
5194瀏覽量
135432 -
HPC
+關注
關注
0文章
346瀏覽量
24974 -
英偉達
+關注
關注
23文章
4086瀏覽量
99173
發布評論請先 登錄
相關推薦
熱點推薦
探索AFBR - S4N44P164M 4×4 NUV - MT硅光電倍增管陣列的卓越性能
探索AFBR - S4N44P164M 4×4 NUV - MT硅光電倍增管陣列的卓越性能 在如今的電子工程領域,對于高精度、高靈敏度的光子檢測設備的需求日益增長。博通(Broadcom)的AFBR
探索AFBR - S4N44P044M 2×2 NUV - MT硅光電倍增管陣列的卓越性能
探索AFBR - S4N44P044M 2×2 NUV - MT硅光電倍增管陣列的卓越性能 在當今的電子工程領域,對于高精度、高靈敏度的光探測器件的需求日益增長。Broadcom的AFBR
探索AFBR - S4N22P014M NUV - MT硅光電倍增管陣列的卓越性能
探索AFBR-S4N22P014M NUV - MT硅光電倍增管陣列的卓越性能 在當今的光電檢測領域,對于高精度、高靈敏度的單光子檢測需求日益增長。Broadcom的AFBR
NVIDIA RTX PRO 4000 Blackwell GPU性能測試
Generation 的全面超越。那么,這款劃時代的專業 GPU 在真實應用場景中的表現究竟如何?今天,我們將通過深度實測,為您揭曉 NVIDIA RTX PRO 4000 Blackwell 相較于前代產品的性能躍遷。

康耐視機器視覺解決方案助力IMA E-COMMERCE提升電商訂單包裝
在電商日訂單量成倍增長的今天,包裝不再是簡單的“裝箱”環節,而是履約效率、運輸成本與用戶體驗的三重競技場。對于IMA E-COMMERCE而言,挑戰不僅來自包裝尺寸不精準導致的運輸浪費,更來自人工
高性能網絡存儲設計:NVMe-oF IP的實現探討
。
該機制能夠根據 IO 類型、SSD 當前隊列深度、任務并行度動態選擇最優NVMe傳輸隊列,避免隊列熱點(Queue Hotspot)與長尾延遲,有效提升NVMe層吞吐能力與指令并行度。在多流場景下
發表于 12-19 18:45
福田歐輝客車銷量實現翻倍增長的核心密碼
2025年中國大中客市場競爭白熱化,福田歐輝客車憑借一份震撼行業的成績單強勢突圍:10月單月銷量同比暴漲179%,新能源車型增長289%,出口增長158%,前10月銷量持續領跑細分賽道,全年銷量劍指1.1萬輛,實現翻倍增長。這
全球前四!京東云云海AI存儲躋身IO500高性能存儲榜單
存儲技術,云海AI存儲不采用 PMEM 硬件,具備更強通用性的同時也實現了更低存儲成本。 IO500是全球高性能計算HPC領域最權威、最具影

如何實現高效的RoCE網卡狀態采集與監控?
當下大規模AI訓練成為常態,RoCEv2憑借高性能、低延遲與低CPU開銷的優勢,已成為構建智算中心的優先選擇。然而,RoCE對網絡無損的嚴苛要求,配置不當會放大擁塞,如 PFC、ECN、Buffer滯留等引發的高延遲、性能下降等
霄云科技銀河存儲:重構AI時代的存儲新范式
在人工智能與高性能計算需求呈指數級增長的今天,數據存儲的效率與可靠性已成為算力釋放的關鍵支撐。上海霄云信息科技有限公司正式推出全新一代AI存儲
芯朋微電子PN7885系列60A超大電流E-Fuse介紹
隨著人工智能(AI)浪潮的到來,數據中心迎來前所未有的變革。服務器的功率需求激增,超高的功率對供電系統的需求成倍增長,板上電源越來越多。防止輸入端涌入的電流使系統過載變得至關重要,否則高昂的停機成本變得不可接受!

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
前言
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」書中的芯片知識是比較接近當前的頂尖芯片水平的,同時包含了芯片架構的基礎知識,但該部分知識比較晦澀難懂,或許是由于我一直從事的事芯片
發表于 06-18 19:31
硅光第六篇:多波長計
現有光纖網絡及其基礎設施的基礎上,數據傳輸容量成倍增長成為可能。特別是在WDM(波分復用)與DWDM的應用場景中,針對光源、光模塊以及光收發器等領域的產品,進行波長

?為什么GPU性能效率比峰值性能更關鍵
在評估GPU性能時,通常首先考察三個指標:圖形工作負載的紋理率(GPixel/s)、浮點運算次數(FLOPS)以及它們能處理計算和AI工作負載的每秒8-bittera運算次數(TOPS)。這些關鍵




 工商網監
工商網監
評論