 Arm Neoverse家族新增V1和N2兩大平臺,突破高性能計算瓶頸
Arm Neoverse家族新增V1和N2兩大平臺,突破高性能計算瓶頸

Arm 近日公開了Arm? Neoverse V1 和 N2 平臺的產品細節,兩者滿足了基礎設施應用的各種需求。這兩個平臺的設計旨在解決當前正在運行的各種工作負載和應用問題,與上一代N1相比,并分別帶來 50%和 40%的性能提升。此外,Arm也同時發布了CMN-700,作為構建基于Neoverse V1和 N2 平臺高性能SoC的關鍵部件。
Neoverse V1:最寬微架構+SVE矢量運算
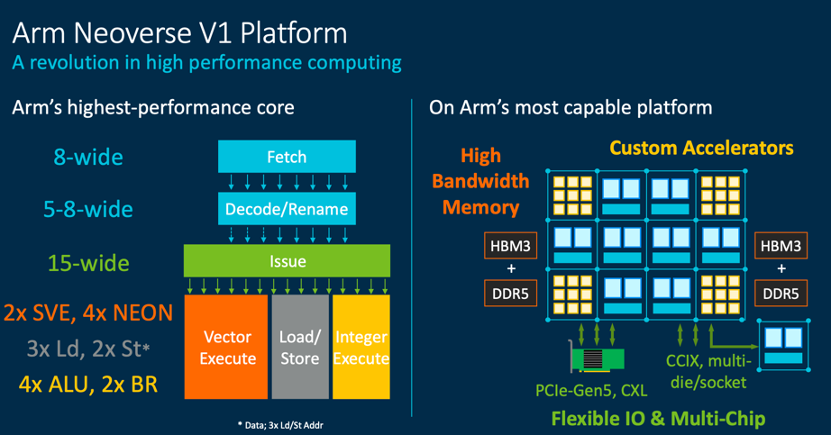
Neoverse V1平臺 / Arm
與上一代N1相比,Neoverse V1帶來了50%的性能提升和1.8倍的矢量工作負載優化、以及4倍的機器學習工作負載優化。得益于Arm迄今為止最寬的微架構以及SVE功能,Neoverse V1可以容納更多運行中的指令,延長了代碼存活期,也為芯片設計人員提供了靈活性。Arm 現有的 SIMD 指令集 NEON 難以對某些代碼進行矢量化處理,而 SVE 可以直接取用相同的代碼,并很好地對其進行自動矢量化,相比于 NEON,SVE可將處理速度提高近3.5倍。

已經用到Neoverse V1的HPC項目 / Arm
目前法國芯片公司SiPearl、印度信息技術部(MEITY)韓國電子通信研究所(ETRI)都在各自的HPC項目中用到了Neoverse V1。
Neoverse N2:首個Armv9+SVE2平臺
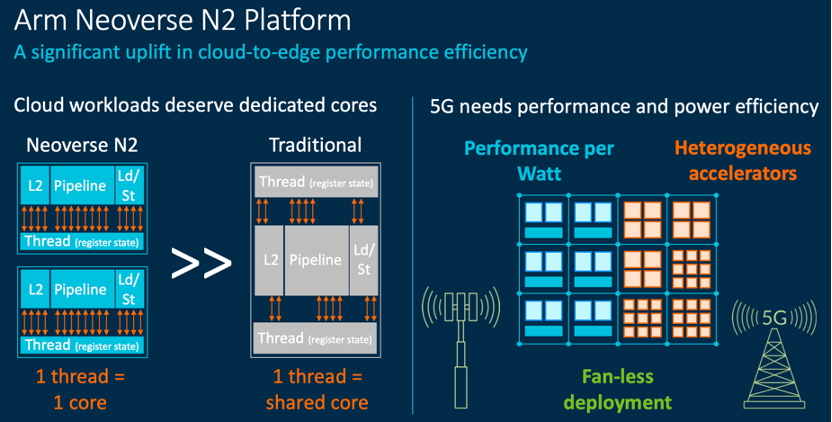
Neoverse N2提高云端到邊緣性能效率 / Arm
Arm在幾周前發布了Armv9架構,以滿足全球對無所不在的專用處理能力的需求,而新公布的Neoverse N2平臺正是第一個基于Armv9架構的平臺。

SVE2 / Arm
相比于N1,Neoverse N2在保持相同水平的功率和面積效率的基礎上,單線程性能提升了40%。不僅如此,Neoverse N2也是第一個具備SVE2功能的平臺,作為SVE和Neon的超集,SVE2為云端到邊緣的性能效率帶來了巨大提升。SVE主要用于加速HPC,而SVE2可廣泛運用于機器學習、數字信號處理和5G等應用場景,同時兼具SVE的編程簡易性和可移植性等優勢。
CMN-700:下一代總線賦能異構SoC

Neoverse CMN-700 / Arm
作為上一代CMN-600的升級,CMN-700支持的最大核心數可達512顆。通過對CCIX 2.0和CXL 2.0的支持,也為客戶提供了更多的定制和擴展選項,為緊密耦合的異構計算提供了更大的靈活性。
異構計算的趨勢
隨著異構計算的逐步發展,我們已經看到了很多CPU和GPU搭配的趨勢,比如英偉達近期公布的基于Arm Neoverse的Grace芯片,就是一個用于AI超算的CPU。英偉達在互聯技術上采用的是自研的NVLink技術,而非PCIE。Arm基礎設施事業部高級副總裁兼總經理 Chris Bergey提到,與多樣化的加速器功能進行互聯,比如AI加速器,這對未來的市場時相當關鍵的。比如CMN-700已經支持了CXL和CCIX這樣的互聯標準,未來Arm期待給市場帶來更多的靈活性,并支持更多像Grace這樣的系統。
這樣的異構趨勢也囊括了FPGA,Arm基礎設施事業部全球高級總監鄒挺補充道,現在已經有合作伙伴將Neoverse N2和FPGA加速卡放在異構計算系統中使用。有的Arm合作伙伴還將FPGA加速器和N2放在一個芯片上做成SoC,通過Chiplet的技術來實現異構計算的靈活性。
公有云的廣泛應用

騰訊云加碼Arm生態 / Arm 騰訊云
Neoverse的廣泛應用在公有云廠商中尤為明顯,比如AWS、阿里云和騰訊云等。騰訊專項測試技術中心總監黃聞欣提到騰訊去年和Arm正式簽署了一份合作協議,希望通過合作加速Arm Neoverse技術的測評和適配。通過TencentBench測試框架發現,得益于更多可擴展的CPU核心數,Arm服務器比傳統的服務器性能表現更強勁,尤其是在AI推理和圖片處理領域。
Neoverse V1:最寬微架構+SVE矢量運算
Neoverse V1平臺 / Arm
與上一代N1相比,Neoverse V1帶來了50%的性能提升和1.8倍的矢量工作負載優化、以及4倍的機器學習工作負載優化。得益于Arm迄今為止最寬的微架構以及SVE功能,Neoverse V1可以容納更多運行中的指令,延長了代碼存活期,也為芯片設計人員提供了靈活性。Arm 現有的 SIMD 指令集 NEON 難以對某些代碼進行矢量化處理,而 SVE 可以直接取用相同的代碼,并很好地對其進行自動矢量化,相比于 NEON,SVE可將處理速度提高近3.5倍。
已經用到Neoverse V1的HPC項目 / Arm
目前法國芯片公司SiPearl、印度信息技術部(MEITY)韓國電子通信研究所(ETRI)都在各自的HPC項目中用到了Neoverse V1。
Neoverse N2:首個Armv9+SVE2平臺
Neoverse N2提高云端到邊緣性能效率 / Arm
Arm在幾周前發布了Armv9架構,以滿足全球對無所不在的專用處理能力的需求,而新公布的Neoverse N2平臺正是第一個基于Armv9架構的平臺。
SVE2 / Arm
CMN-700:下一代總線賦能異構SoC
Neoverse CMN-700 / Arm
作為上一代CMN-600的升級,CMN-700支持的最大核心數可達512顆。通過對CCIX 2.0和CXL 2.0的支持,也為客戶提供了更多的定制和擴展選項,為緊密耦合的異構計算提供了更大的靈活性。
異構計算的趨勢
隨著異構計算的逐步發展,我們已經看到了很多CPU和GPU搭配的趨勢,比如英偉達近期公布的基于Arm Neoverse的Grace芯片,就是一個用于AI超算的CPU。英偉達在互聯技術上采用的是自研的NVLink技術,而非PCIE。Arm基礎設施事業部高級副總裁兼總經理 Chris Bergey提到,與多樣化的加速器功能進行互聯,比如AI加速器,這對未來的市場時相當關鍵的。比如CMN-700已經支持了CXL和CCIX這樣的互聯標準,未來Arm期待給市場帶來更多的靈活性,并支持更多像Grace這樣的系統。
這樣的異構趨勢也囊括了FPGA,Arm基礎設施事業部全球高級總監鄒挺補充道,現在已經有合作伙伴將Neoverse N2和FPGA加速卡放在異構計算系統中使用。有的Arm合作伙伴還將FPGA加速器和N2放在一個芯片上做成SoC,通過Chiplet的技術來實現異構計算的靈活性。
公有云的廣泛應用
騰訊云加碼Arm生態 / Arm 騰訊云
Neoverse的廣泛應用在公有云廠商中尤為明顯,比如AWS、阿里云和騰訊云等。騰訊專項測試技術中心總監黃聞欣提到騰訊去年和Arm正式簽署了一份合作協議,希望通過合作加速Arm Neoverse技術的測評和適配。通過TencentBench測試框架發現,得益于更多可擴展的CPU核心數,Arm服務器比傳統的服務器性能表現更強勁,尤其是在AI推理和圖片處理領域。
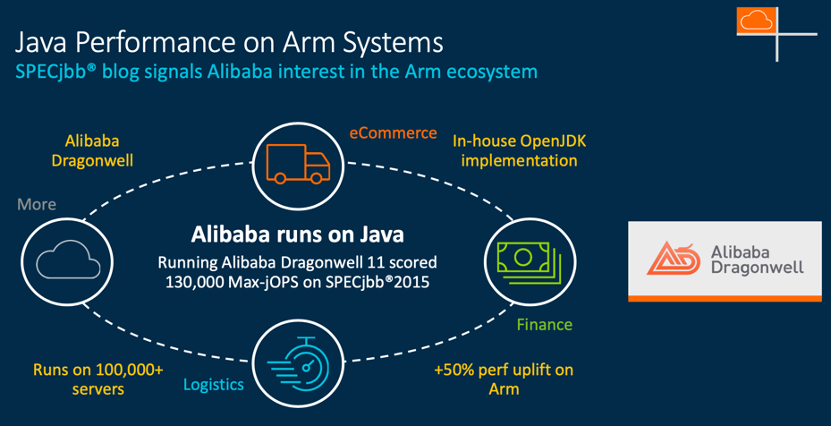
阿里巴巴首席工程師周經森(Kingsum Chow)談道:Arm的CPU資源的話,在我們現有的軟件里會有兩個考慮的點,一個是我們有些軟件是需要重新編譯的,另外一種不需要重新編譯,只需要我們把Java applications在JVM(Java Virtual Machine)上跑好就可以了。在這方面,一年之前,我們就跟Arm的員工一起合作,把JVM的性能提高。過去一年里,我們從JDK8到JDK11,通過OpenJDK, 通過阿里巴巴 Dragonwell(OpenJDK的一個發行版),就把我們現有一些Java應用的一些性能提高了50%。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
ARM
+關注
關注
135文章
9553瀏覽量
391867 -
HPC
+關注
關注
0文章
346瀏覽量
24976 -
高性能計算
+關注
關注
0文章
96瀏覽量
13808 -
Neoverse
+關注
關注
0文章
16瀏覽量
4974
發布評論請先 登錄
相關推薦
熱點推薦
如何在Arm Neoverse N2平臺上提升llama.cpp擴展性能
跨 NUMA 內存訪問可能會限制 llama.cpp 在 Arm Neoverse 平臺上的擴展能力。本文將為你詳細分析這一問題,并通過引入原型驗證補丁來加以解決。測試結果表明,在基于 Neo
Arm Neoverse平臺集成NVIDIA NVLink Fusion
生態系統,實現全緩存一致性與高帶寬互連。 隨著 AI 數據中心對 Arm Neoverse 的需求持續增長,客戶在將工作負載加速器連接至 Arm 平臺時擁有更多選擇。 人工智能 (A
RISC-V V擴展的指令代碼
1.指令集V擴展的主要內容:
矢量指令:針對數據并行性,增加了一系列新的矢量指令,可以同時對多個數據進行操作,提高了計算效率。浮點指令:新增了一些浮點指令,支持更高精度的
發表于 10-21 13:11
全新Arm Lumex CSS平臺實現兩位數性能提升
及下一代個人電腦加速其人工智能 (AI) 體驗的先進計算平臺。Lumex CSS 平臺集成了搭載第二代可伸縮矩陣擴展 (SME2) 技術的最高性能

西門子 Veloce CS 助力 Arm Neoverse 計算子系統驗證與確認
西門子數字化工業軟件近日宣布,Veloce Strato CS 與Veloce proFPGA CS 已被 Veloce 的長期合作伙伴 Arm 部署應用,作為Arm Neoverse 計算
知合計算:RISC-V架構創新,阿基米德系列劍指高性能計算
在2025 RISC-V中國峰會上,知合計算處理器設計總監劉暢就高性能RISC-V處理器架構探索與實踐進行了精彩分享。 在以X86和ARM為

Arm Neoverse N2平臺實現DeepSeek-R1滿血版部署
頗具優勢。Arm 攜手合作伙伴,在 Arm Neoverse N2 平臺上使用開源推理框架 llama.cpp 實現 DeepSeek-R

臺安N2變頻器與Modbus RTU轉Profinet網關實現數據互換
在工業自動化領域,Modbus RTU協議與Profinet協議的轉換需求日益凸顯,尤其是當涉及到臺安N2變頻器等設備的應用時。本文將深入探討Modbus RTU轉Profinet網關與臺安N2變頻器通訊的相關知識,幫助讀者更好地理解和應用這一技術。

AMD實現首個基于臺積電N2制程的硅片里程碑
代號為“Venice”的新一代AMD EPYC CPU是首款基于臺積電新一代N2制程的高性能計算產品。 ? AMD表示,其代號為“Venice”的新一代AMD EPYC?處理器是業界首款完成流片并

解讀基于Arm Neoverse V2平臺的Google Axion處理器
云計算需求在人工智能 (AI) 時代的爆發式增長,推動了開發者尋求性能優化且高能效的解決方案,以降低總體擁有成本 (TCO)。Arm 致力于通過 Arm
如何在基于Arm Neoverse平臺的CPU上構建分布式Kubernetes集群
在本文中,我們將以 X(原 Twitter)為例,演示如何在基于 Arm Neoverse 平臺的 CPU 上構建分布式 Kubernetes 集群,以根據推文實時監控情緒變化。如此一來,你可以充分利用
Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
RZ/V2N——近期在嵌入式世界2025上新發布,為 AI 計算、嵌入式系統及工自動化提供強大支持。這款全新的計算平臺旨在滿足開發者和企業用戶對高性
發表于 03-19 17:54
Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
2025年3月19日——Banana Pi 今日正式發布 BPI-AI2N & BPI-AI2N Carrier,基于瑞薩電子(Renesas)同步發布的最新的高性能處理器RZ/V2N

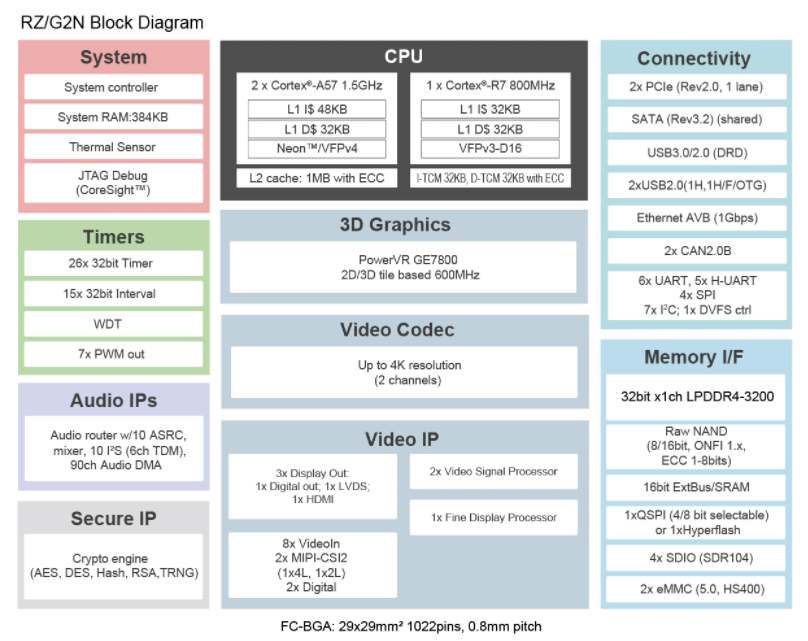
采用雙核Arm Cortex-A57 CPU的超高性能微處理器RZ/G2N數據手冊
RZ/G2N憑借雙核 Arm? Cortex?-A57(1.5GHz)處理器,具備更高規格的處理性能,同時擁有 3D 圖形處理能力以及 4K 視頻編碼/ 解碼功能。作為該產品的軟件平臺



 工商網監
工商網監
評論