 一文詳解實時數據倉庫的發展、架構和趨勢
一文詳解實時數據倉庫的發展、架構和趨勢

數據處理現狀:當前基于Hive的離線數據倉庫已經非常成熟,數據中臺體系也基本上是圍繞離線數倉進行建設。但是隨著實時計算引擎的不斷發展以及業務對于實時報表的產出需求不斷膨脹,業界最近幾年就一直聚焦并探索于兩個相關的熱點問題:實時數倉建設和大數據架構的批流一體建設。
1實時數倉建設:實時數倉1.0
傳統意義上我們通常將數據處理分為離線數據處理和實時數據處理。對于實時處理場景,我們一般又可以分為兩類,一類諸如監控報警類、大屏展示類場景要求秒級甚至毫秒級;另一類諸如大部分實時報表的需求通常沒有非常高的時效性要求,一般分鐘級別,比如10分鐘甚至30分鐘以內都可以接受。
對于第一類實時數據場景來說,業界通常的做法比較簡單粗暴,一般也不需要非常仔細地進行數據分層,數據直接通過Flink計算或者聚合之后將結果寫入MySQL/ES/HBASE/Druid/Kudu等,直接提供應用查詢或者多維分析。如下所示:
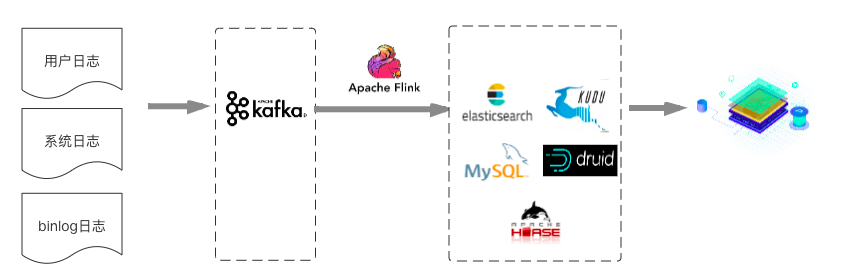
而對于后者來說,通常做法會按照數倉結構進行設計,我們稱后者這種應用場景為實時數倉,將作為本篇文章討論的重點。從業界情況來看,當前主流的實時數倉架構基本都是基于Kafka+Flink的架構(為了行文方便,就稱為實時數倉1.0)。下圖是基于業界各大公司分享的實時數倉架構抽象的一個方案:
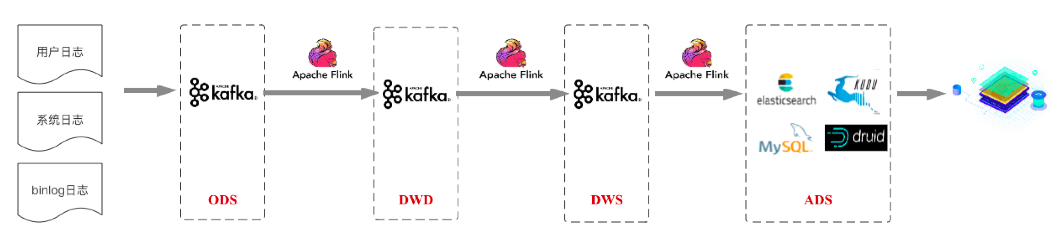
這套架構總體依然遵循標準的數倉分層結構,各種數據首先匯聚于ODS數據接入層。再接著經過這些來源明細數據的數據清洗、過濾等操作,完成多來源同類明細數據的融合,形成面向業務主題的DWD數據明細層。在此基礎上進行輕度的匯總操作,形成一定程度上方便查詢的DWS輕度匯總層(注:這里沒有畫出DIM維度層,一般選型為Redis/HBase,下文架構圖中同樣沒有畫出DIM維度層,在此說明)。最后再面向業務需求,在DWS層基礎上進一步對數據進行組織進入ADS數據應用層,業務在數據應用層的基礎上支持用戶畫像、用戶報表等業務場景。
基于Kafka+Flink的這套架構方案很好的解決了實時數倉對于時效性的業務訴求,通常延遲可以做到秒級甚至更短。基于上圖所示實時數倉架構方案,筆者整理了一個目前業界比較主流的整體數倉架構方案:
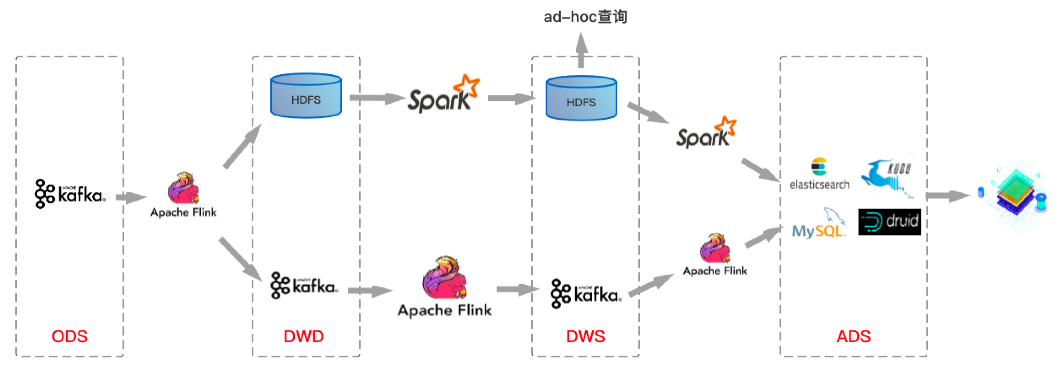
上圖中上層鏈路是離線數倉數據流轉鏈路,下層鏈路是實時數倉數據流轉鏈路,當然實際情況可能是很多公司在實時數倉建設中并沒有嚴格按照數倉分層結構進行分層,與上圖稍有不同。
然而基于Kafka+Flink的實時數倉方案有幾個非常明顯的缺陷:
(1)Kafka無法支持海量數據存儲。對于海量數據量的業務線來說,Kafka一般只能存儲非常短時間的數據,比如最近一周,甚至最近一天;
(2)Kafka無法支持高效的OLAP查詢。大多數業務都希望能在DWDDWS層支持即席查詢的,但是Kafka無法非常友好地支持這樣的需求;
(3)無法復用目前已經非常成熟的基于離線數倉的數據血緣、數據質量管理體系。需要重新實現一套數據血緣、數據質量管理體系;
(4)Lambad架構維護成本很高。很顯然,這種架構下數據存在兩份、schema不統一、 數據處理邏輯不統一,整個數倉系統維護成本很高;
(5)Kafka不支持update/upsert。目前Kafka僅支持append。實際場景中在DWS輕度匯聚層很多時候是需要更新的,DWD明細層到DWS輕度匯聚層一般會根據時間粒度以及維度進行一定的聚合,用于減少數據量,提升查詢性能。假如原始數據是秒級數據,聚合窗口是1分鐘,那就有可能產生某些延遲的數據經過時間窗口聚合之后需要更新之前數據的需求。這部分更新需求無法使用Kafka實現。
所以實時數倉發展到現在的架構,一定程度上解決了數據報表時效性問題,但是這樣的架構依然存在不少問題,隨著技術的發展,相信基于Kafka+Flink的實時數倉架構也會進一步往前發展。那會往哪里發展呢?
大數據架構的批流一體建設。
帶著上面的問題我們再來接著聊一聊最近一兩年和實時數倉一樣很火的另一個概念:批流一體。對于批流一體的理解,筆者發現有很多種解讀,比如有些業界前輩認為批和流在開發層面上都統一到相同的SQL上是批流一體,又有些前輩認為在計算引擎層面上批和流可以集成在同一個計算引擎是批流一體,比如Spark/Spark Structured Streaming就算一個在計算引擎層面實現了批流一體的計算框架,與此同時另一個計算引擎Flink,目前在流處理方面已經做了很多的工作而且在業界得到了普遍的認可,但在批處理方面還有一定的路要走。
2實時數倉2.0
筆者認為無論是業務SQL使用上的統一還是計算引擎上的統一,都是批流一體的一個方面。除此之外,批流一體還有一個最核心的方面,那就是存儲層面上的統一。在這個方面業界也有一些走在前面的技術,比如最近一段時間開始流行起來的數據湖三劍客-- delta/hudi/iceberg,就在往這個方向走。存儲一旦能夠做到統一,上述數據倉庫架構就會變成如下模樣(以Iceberg數據湖作為統一存儲為例),稱為實時數倉2.0:
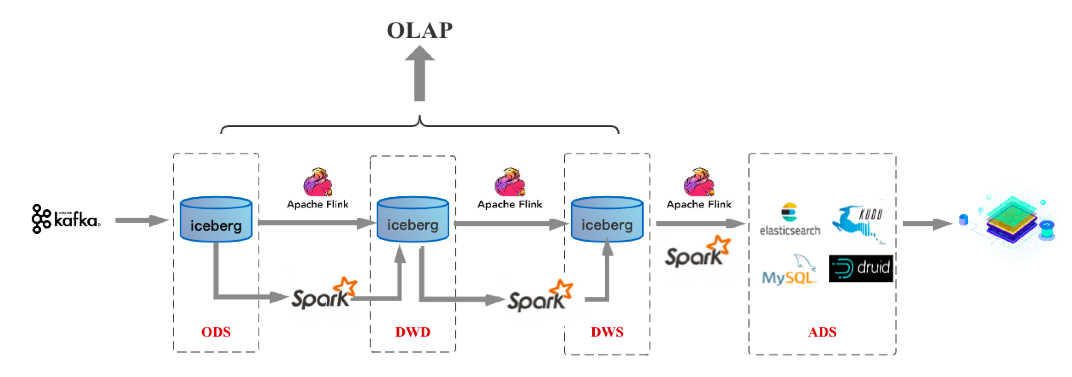
這套架構中無論是流處理還是批處理,數據存儲都統一到數據湖Iceberg上。那這么一套架構將存儲統一后有什么好處呢?很明顯,可以解決Kafka+Flink架構實時數倉存在的前面4個問題:
(1)可以解決Kafka存儲數據量少的問題。目前所有數據湖基本思路都是基于HDFS之上實現的一個文件管理系統,所以數據體量可以很大。
(2)DW層數據依然可以支持OLAP查詢。同樣數據湖基于HDFS之上實現,只需要當前的OLAP查詢引擎做一些適配就可以進行OLAP查詢。
(3)批流存儲都基于Iceberg/HDFS存儲之后,就完全可以復用一套相同的數據血緣、數據質量管理體系。
(4)Kappa架構相比Lambad架構來說,schema統一,數據處理邏輯統一,用戶不再需要維護兩份數據。
有的同學說了,這不,你直接解決了前4個問題嘛,還有第5個問題呢?對,第5個問題下文會講到。
又有的同學會說了,上述架構確實解決了Lambad架構的諸多問題,但是這套架構看起來就像是一條離線處理鏈路,它是怎么做到報表實時產出呢?確實,上述架構圖主要將離線處理鏈路上的HDFS換成了數據湖Iceberg,就號稱可以實現實時數倉,聽起來容易讓人迷糊。這里的關鍵就是數據湖Iceberg,它到底有什么魔力?
為了回答這個問題,筆者就上述架構以及數據湖技術本身做一個簡單的介紹(接下來也會基于Iceberg出一個專題深入介紹數據湖技術)。上述架構圖中有兩條數據處理鏈路,一條是基于Flink的實時數據鏈路,一條是基于Spark的離線數據鏈路。通常數據都是直接走實時鏈路處理,而離線鏈路則更多的應用于數據修正等非常規場景。這樣的架構要成為一個可以落地的實時數倉方案,數據湖Iceberg是需要滿足如下幾個要求的:
(1)支持流式寫入-增量拉取。流式寫入其實現在基于Flink就可以實現,無非是將checkpoint間隔設置的短一點,比如1分鐘,就意味每分鐘生成的文件就可以寫入到HDFS,這就是流式寫入。沒錯,但是這里有兩個問題,第一個問題是小文件很多,但這不是最關鍵的,第二個問題才是最致命的,就是上游每分鐘提交了很多文件到HDFS上,下游消費的Flink是不知道哪些文件是最新提交的,因此下游Flink就不知道應該去消費處理哪些文件。這個問題才是離線數倉做不到實時的最關鍵原因之一,離線數倉的玩法是說上游將數據全部導入完成了,告訴下游說這波數據全部導完了,你可以消費處理了,這樣的話就做不到實時處理。
數據湖就解決了這個問題。實時數據鏈路處理的時候上游Flink寫入的文件進來之后,下游就可以將數據文件一致性地讀走。這里強調一致性地讀,就是不能多讀一個文件也不能少讀一個文件。上游這段時間寫了多少文件,下游就要讀走多少文件。我們稱這樣的讀取叫增量拉取。
(2)解決小文件多的問題。數據湖實現了相關合并小文件的接口,Spark/Flink上層引擎可以周期性地調用接口進行小文件合并。
(3)支持批量以及流式的Upsert(Delete)功能。批量Upsert/Delete功能主要用于離線數據修正。流式upsert場景上文介紹了,主要是流處理場景下經過窗口時間聚合之后有延遲數據到來的話會有更新的需求。這類需求是需要一個可以支持更新的存儲系統的,而離線數倉做更新的話需要全量數據覆蓋,這也是離線數倉做不到實時的關鍵原因之一,數據湖是需要解決掉這個問題的。
(4)支持比較完整的OLAP生態。比如支持Hive/Spark/Presto/Impala等OLAP查詢引擎,提供高效的多維聚合查詢性能。
這里需要備注一點,目前Iceberg部分功能還在開發中。具體技術層面Iceberg是怎么解決上述問題的,請持續關注本號,接下來一篇文章會詳細講解哦。
3實時數倉3.0
按照批流一體上面的探討,如果計算引擎做到了批流一體的統一,就可以做到SQL統一、計算統一以及存儲統一,這時就邁入實時數倉3.0時代。對于以Spark為核心技術棧的公司來說,實時數倉2.0的到來就意味著3.0的到來,因為在計算引擎層面Spark早已做到批流一體。基于Spark/數據湖的3.0架構如下圖:
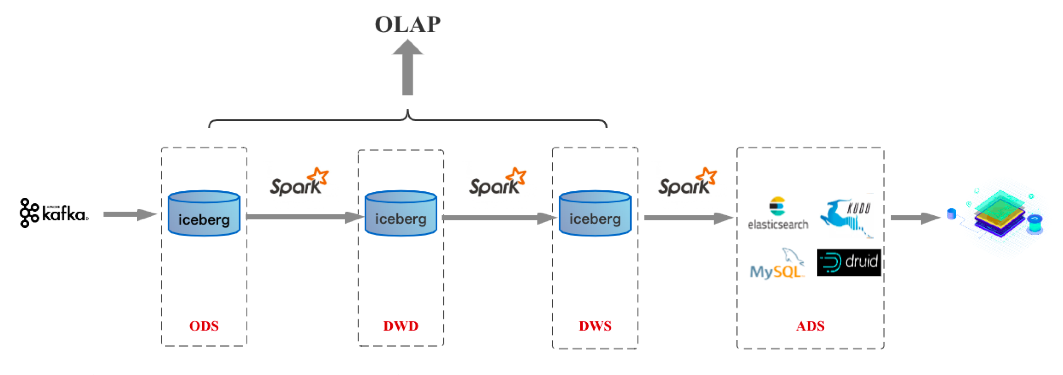
假如未來Flink在批處理領域成熟到一定程度,基于Flink/數據湖的3.0架構如下圖:
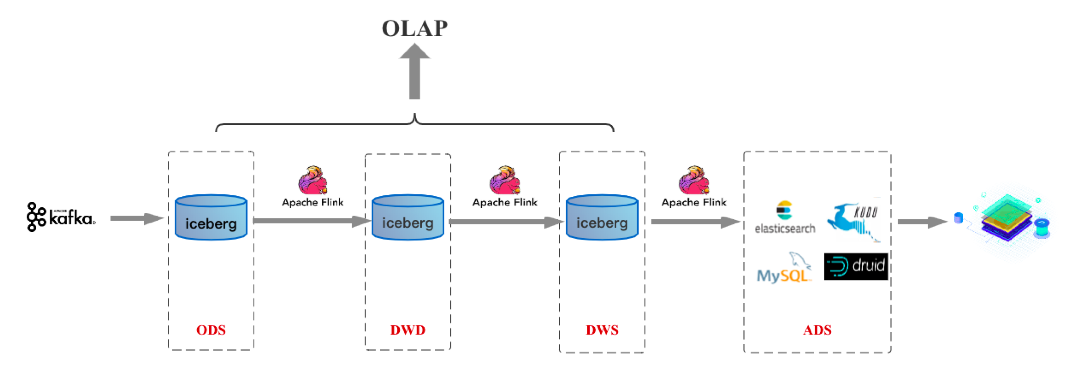
上面所介紹的,是筆者認為接下來幾年數據倉庫發展的一個可能路徑。對于業界目前實時數倉的一個發展預估,個人覺得目前業界大多公司都還往實時數倉1.0這個架構上靠;而在接下來1到2年時間隨著數據湖技術的成熟,實時數倉2.0架構會成為越來越多公司的選擇,其實到了2.0時代之后,業務同學最關心的報表實時性訴求和大數據平臺同學最關心的數據存儲一份訴求都可以解決;隨著計算引擎的成熟,實時數倉3.0可能和實時數倉2.0一起或者略微滯后一些普及。
編輯:jq
-
SQL
+關注
關注
1文章
803瀏覽量
46799 -
數據倉庫
+關注
關注
0文章
65瀏覽量
10988 -
ODS
+關注
關注
0文章
7瀏覽量
9717
原文標題:一文了解實時數據倉庫的發展、架構和趨勢
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于 LES33-HUB-3-RS485 的冷鏈倉庫多傳感器智能組網解決方案
零碳園區數字感知基礎架構規劃的發展趨勢
智能手持條碼掃描pda:告別盲掃,提升倉庫管理效率

米爾RK3506核心板SDK重磅升級,解鎖三核A7實時控制新架構
實時庫存同步接口技術詳解


電商API的實時數據處理



 工商網監
工商網監
評論