 如何在OpenCV中使用基于深度學習的邊緣檢測
如何在OpenCV中使用基于深度學習的邊緣檢測

導讀
分析了Canny的優劣,并給出了OpenCV使用深度學習做邊緣檢測的流程,文末有代碼鏈接。
在這篇文章中,我們將學習如何在OpenCV中使用基于深度學習的邊緣檢測,它比目前流行的canny邊緣檢測器更精確。邊緣檢測在許多用例中是有用的,如視覺顯著性檢測,目標檢測,跟蹤和運動分析,結構從運動,3D重建,自動駕駛,圖像到文本分析等等。
什么是邊緣檢測?
邊緣檢測是計算機視覺中一個非常古老的問題,它涉及到檢測圖像中的邊緣來確定目標的邊界,從而分離感興趣的目標。最流行的邊緣檢測技術之一是Canny邊緣檢測,它已經成為大多數計算機視覺研究人員和實踐者的首選方法。讓我們快速看一下Canny邊緣檢測。
Canny邊緣檢測算法
1983年,John Canny在麻省理工學院發明了Canny邊緣檢測。它將邊緣檢測視為一個信號處理問題。其核心思想是,如果你觀察圖像中每個像素的強度變化,它在邊緣的時候非常高。
在下面這張簡單的圖片中,強度變化只發生在邊界上。所以,你可以很容易地通過觀察像素強度的變化來識別邊緣。
現在,看下這張圖片。強度不是恒定的,但強度的變化率在邊緣處最高。(微積分復習:變化率可以用一階導數(梯度)來計算。)

Canny邊緣檢測器通過4步來識別邊緣:
去噪:因為這種方法依賴于強度的突然變化,如果圖像有很多隨機噪聲,那么會將噪聲作為邊緣。所以,使用5×5的高斯濾波器平滑你的圖像是一個非常好的主意。
梯度計算:下一步,我們計算圖像中每個像素的強度的梯度(強度變化率)。我們也計算梯度的方向。
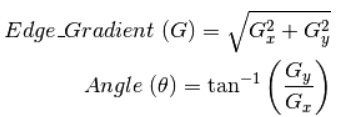
梯度方向垂直于邊緣,它被映射到四個方向中的一個(水平、垂直和兩個對角線方向)。
非極大值抑制:現在,我們想刪除不是邊緣的像素(設置它們的值為0)。你可能會說,我們可以簡單地選取梯度值最高的像素,這些就是我們的邊。然而,在真實的圖像中,梯度不是簡單地在只一個像素處達到峰值,而是在臨近邊緣的像素處都非常高。因此我們在梯度方向上取3×3附近的局部最大值。
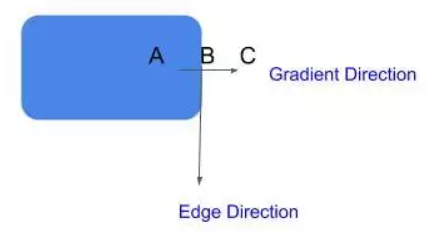
遲滯閾值化:在下一步中,我們需要決定一個梯度的閾值,低于這個閾值所有的像素都將被抑制(設置為0)。而Canny邊緣檢測器則采用遲滯閾值法。遲滯閾值法是一種非常簡單而有效的方法。我們使用兩個閾值來代替只用一個閾值:
高閾值 = 選擇一個非常高的值,這樣任何梯度值高于這個值的像素都肯定是一個邊緣。
低閾值 = 選擇一個非常低的值,任何梯度值低于該值的像素絕對不是邊緣。
在這兩個閾值之間有梯度的像素會被檢查,如果它們和邊緣相連,就會留下,否則就會去掉。
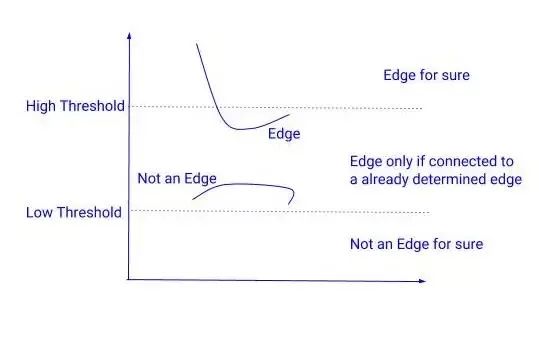
遲滯閾值化
Canny 邊緣檢測的問題:
由于Canny邊緣檢測器只關注局部變化,沒有語義(理解圖像的內容)理解,精度有限(很多時候是這樣)。
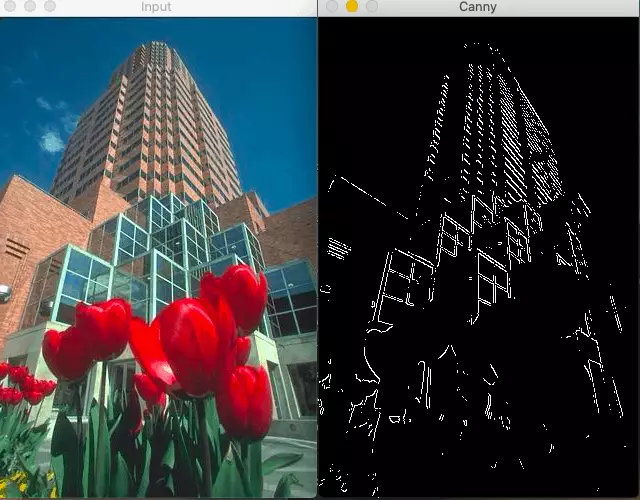
Canny邊緣檢測器在這種情況下會失敗,因為沒有理解圖像的上下文
語義理解對于邊緣檢測是至關重要的,這就是為什么使用機器學習或深度學習的基于學習的檢測器比canny邊緣檢測器產生更好的結果。
OpenCV中基于深度學習的邊緣檢測
OpenCV在其全新的DNN模塊中集成了基于深度學習的邊緣檢測技術。你需要OpenCV 3.4.3或更高版本。這種技術被稱為整體嵌套邊緣檢測或HED,是一種基于學習的端到端邊緣檢測系統,使用修剪過的類似vgg的卷積神經網絡進行圖像到圖像的預測任務。
HED利用了中間層的輸出。之前的層的輸出稱為side output,將所有5個卷積層的輸出進行融合,生成最終的預測。由于在每一層生成的特征圖大小不同,它可以有效地以不同的尺度查看圖像。
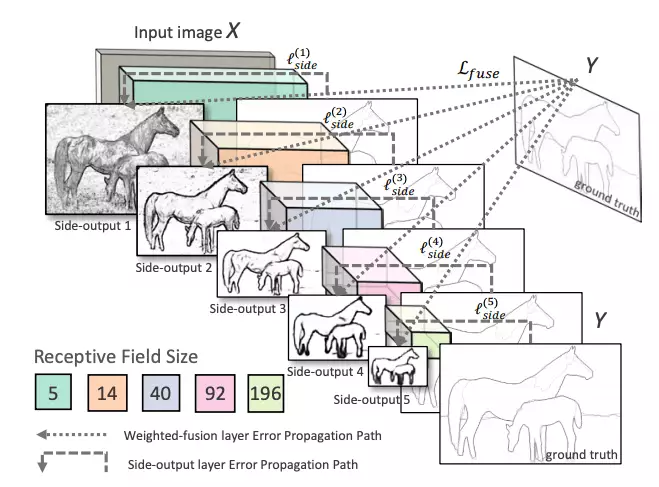
網絡結構:整體嵌套邊緣檢測
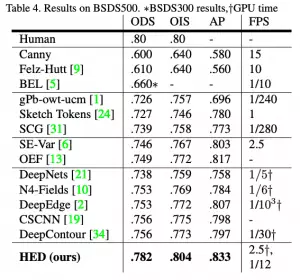
HED方法不僅比其他基于深度學習的方法更準確,而且速度也比其他方法快得多。這就是為什么OpenCV決定將其集成到新的DNN模塊中。以下是這篇論文的結果:
在OpenCV中訓練深度學習邊緣檢測的代碼
OpenCV使用的預訓練模型已經在Caffe框架中訓練過了,可以這樣加載:
shdownload_pretrained.sh
網絡中有一個crop層,默認是沒有實現的,所以我們需要自己實現一下。
classCropLayer(object): def__init__(self,params,blobs): self.xstart=0 self.xend=0 self.ystart=0 self.yend=0 #Ourlayerreceivestwoinputs.Weneedtocropthefirstinputblob #tomatchashapeofthesecondone(keepingbatchsizeandnumberofchannels) defgetMemoryShapes(self,inputs): inputShape,targetShape=inputs[0],inputs[1] batchSize,numChannels=inputShape[0],inputShape[1] height,width=targetShape[2],targetShape[3] self.ystart=(inputShape[2]-targetShape[2])//2 self.xstart=(inputShape[3]-targetShape[3])//2 self.yend=self.ystart+height self.xend=self.xstart+width return[[batchSize,numChannels,height,width]] defforward(self,inputs): return[inputs[0][:,:,self.ystart:self.yend,self.xstart:self.xend]]
現在,我們可以重載這個類,只需用一行代碼注冊該層。
cv.dnn_registerLayer('Crop',CropLayer)
現在,我們準備構建網絡圖并加載權重,這可以通過OpenCV的dnn.readNe函數。
net=cv.dnn.readNet(args.prototxt,args.caffemodel)
現在,下一步是批量加載圖像,并通過網絡運行它們。為此,我們使用cv2.dnn.blobFromImage方法。該方法從輸入圖像中創建四維blob。
blob=cv.dnn.blobFromImage(image,scalefactor,size,mean,swapRB,crop)
其中:
image:是我們想要發送給神經網絡進行推理的輸入圖像。
scalefactor:圖像縮放常數,很多時候我們需要把uint8的圖像除以255,這樣所有的像素都在0到1之間。默認值是1.0,不縮放。
size:輸出圖像的空間大小。它將等于后續神經網絡作為blobFromImage輸出所需的輸入大小。
swapRB:布爾值,表示我們是否想在3通道圖像中交換第一個和最后一個通道。OpenCV默認圖像為BGR格式,但如果我們想將此順序轉換為RGB,我們可以將此標志設置為True,這也是默認值。
mean:為了進行歸一化,有時我們計算訓練數據集上的平均像素值,并在訓練過程中從每幅圖像中減去它。如果我們在訓練中做均值減法,那么我們必須在推理中應用它。這個平均值是一個對應于R, G, B通道的元組。例如Imagenet數據集的均值是R=103.93, G=116.77, B=123.68。如果我們使用swapRB=False,那么這個順序將是(B, G, R)。
crop:布爾標志,表示我們是否想居中裁剪圖像。如果設置為True,則從中心裁剪輸入圖像時,較小的尺寸等于相應的尺寸,而其他尺寸等于或大于該尺寸。然而,如果我們將其設置為False,它將保留長寬比,只是將其調整為固定尺寸大小。
在我們這個場景下:
inp=cv.dnn.blobFromImage(frame,scalefactor=1.0,size=(args.width,args.height), mean=(104.00698793,116.66876762,122.67891434),swapRB=False, crop=False)
現在,我們只需要調用一下前向方法。
net.setInput(inp) out=net.forward() out=out[0,0] out=cv.resize(out,(frame.shape[1],frame.shape[0])) out=255*out out=out.astype(np.uint8) out=cv.cvtColor(out,cv.COLOR_GRAY2BGR) con=np.concatenate((frame,out),axis=1) cv.imshow(kWinName,con)
結果:
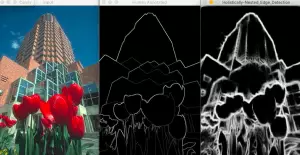
中間的圖像是人工標注的圖像,右邊是HED的結果

中間的圖像是人工標注的圖像,右邊是HED的結果
文中的代碼:https://github.com/sankit1/cv-tricks.com/tree/master/OpenCV/Edge_detection
英文原文:https://cv-tricks.com/opencv-dnn/edge-detection-hed/
責任編輯:lq
-
邊緣檢測
+關注
關注
0文章
94瀏覽量
18673 -
OpenCV
+關注
關注
33文章
652瀏覽量
44787 -
深度學習
+關注
關注
73文章
5599瀏覽量
124396
原文標題:基于OpenCV深度學習的邊緣檢測
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
OpenCV首次到訪奧比中光并展開深度交流
穿孔機頂頭檢測儀 機器視覺深度學習
沒有專利的opencv-python 版本
如何深度學習機器視覺的應用場景
如何在AMD Vitis Unified IDE中使用系統設備樹
機器視覺雙雄YOLO 和 OpenCV 到底有啥區別?別再傻傻分不清!
如何在機器視覺中部署深度學習神經網絡

【開發實例】基于GM-3568JHF開發板安裝OpenCV并使用視頻目標跟蹤 ( CamShift)

如何使用樹莓派與OpenCV實現面部和運動追蹤的云臺系統?

【Milk-V Duo S 開發板免費體驗】SDK編譯、人臉檢測、OpenCV測試
【「# ROS 2智能機器人開發實踐」閱讀體驗】視覺實現的基礎算法的應用
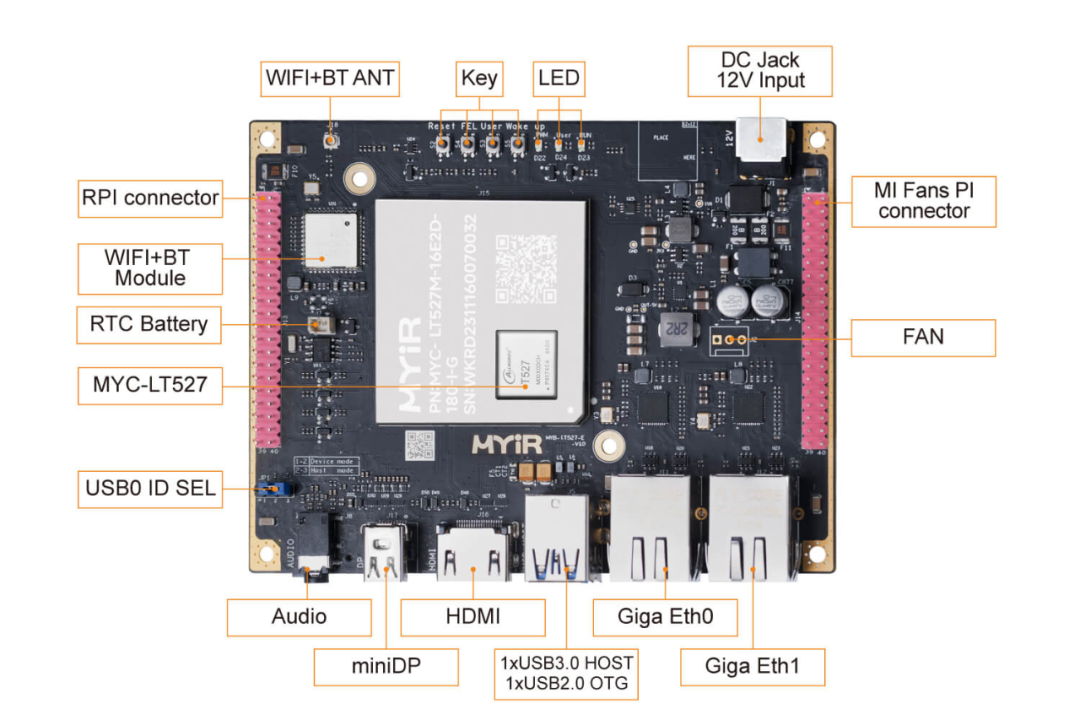
OpenCV行人檢測應用方案--基于米爾全志T527開發板
行業首創:基于深度學習視覺平臺的AI驅動輪胎檢測自動化




 工商網監
工商網監
評論