 為什么SAM可以實現更好的泛化?如何在Pytorch中實現SAM?
為什么SAM可以實現更好的泛化?如何在Pytorch中實現SAM?

導讀 使用SAM(銳度感知最小化),優化到損失的最平坦的最小值的地方,增強泛化能力。
動機來自先前的工作,在此基礎上,我們提出了一種新的、有效的方法來同時減小損失值和損失的銳度。具體來說,在我們的處理過程中,進行銳度感知最小化(SAM),在領域內尋找具有均勻的低損失值的參數。這個公式產生了一個最小-最大優化問題,在這個問題上梯度下降可以有效地執行。我們提出的實證結果表明,SAM在各種基準數據集上都改善了的模型泛化。
在深度學習中,我們使用SGD/Adam等優化算法在我們的模型中實現收斂,從而找到全局最小值,即訓練數據集中損失較低的點。但等幾種研究表明,許多網絡可以很容易地記住訓練數據并有能力隨時overfit,為了防止這個問題,增強泛化能力,谷歌研究人員發表了一篇新論文叫做Sharpness Awareness Minimization,在CIFAR10上以及其他的數據集上達到了最先進的結果。
在本文中,我們將看看為什么SAM可以實現更好的泛化,以及我們如何在Pytorch中實現SAM。
SAM的原理是什么?
在梯度下降或任何其他優化算法中,我們的目標是找到一個具有低損失值的參數。但是,與其他常規的優化方法相比,SAM實現了更好的泛化,它將重點放在領域內尋找具有均勻的低損失值的參數(而不是只有參數本身具有低損失值)上。
由于計算鄰域參數而不是計算單個參數,損失超平面比其他優化方法更平坦,這反過來增強了模型的泛化。
(左))用SGD訓練的ResNet收斂到的一個尖銳的最小值。(右)用SAM訓練的相同的ResNet收斂到的一個平坦的最小值。
注意:SAM不是一個新的優化器,它與其他常見的優化器一起使用,比如SGD/Adam。
在Pytorch中實現SAM
在Pytorch中實現SAM非常簡單和直接
import torch
class SAM(torch.optim.Optimizer):
def __init__(self, params, base_optimizer, rho=0.05, **kwargs):
assert rho 》= 0.0, f“Invalid rho, should be non-negative: {rho}”
defaults = dict(rho=rho, **kwargs)
super(SAM, self).__init__(params, defaults)
self.base_optimizer = base_optimizer(self.param_groups, **kwargs)
self.param_groups = self.base_optimizer.param_groups
@torch.no_grad()
def first_step(self, zero_grad=False):
grad_norm = self._grad_norm()
for group in self.param_groups:
scale = group[“rho”] / (grad_norm + 1e-12)
for p in group[“params”]:
if p.grad is None: continue
e_w = p.grad * scale.to(p)
p.add_(e_w) # climb to the local maximum “w + e(w)”
self.state[p][“e_w”] = e_w
if zero_grad: self.zero_grad()
@torch.no_grad()
def second_step(self, zero_grad=False):
for group in self.param_groups:
for p in group[“params”]:
if p.grad is None: continue
p.sub_(self.state[p][“e_w”]) # get back to “w” from “w + e(w)”
self.base_optimizer.step() # do the actual “sharpness-aware” update
if zero_grad: self.zero_grad()
def _grad_norm(self):
shared_device = self.param_groups[0][“params”][0].device # put everything on the same device, in case of model parallelism
norm = torch.norm(
torch.stack([
p.grad.norm(p=2).to(shared_device)
for group in self.param_groups for p in group[“params”]
if p.grad is not None
]),
p=2
)
return norm
代碼取自非官方的Pytorch實現。
代碼解釋:
首先,我們從Pytorch繼承優化器類來創建一個優化器,盡管SAM不是一個新的優化器,而是在需要繼承該類的每一步更新梯度(在基礎優化器的幫助下)。
該類接受模型參數、基本優化器和rho, rho是計算最大損失的鄰域大小。
在進行下一步之前,讓我們先看看文中提到的偽代碼,它將幫助我們在沒有數學的情況下理解上述代碼。

正如我們在計算第一次反向傳遞后的偽代碼中看到的,我們計算epsilon并將其添加到參數中,這些步驟是在上述python代碼的方法first_step中實現的。
現在在計算了第一步之后,我們必須回到之前的權重來計算基礎優化器的實際步驟,這些步驟在函數second_step中實現。
函數_grad_norm用于返回矩陣向量的norm,即偽代碼的第10行
在構建這個類后,你可以簡單地使用它為你的深度學習項目通過以下的訓練函數片段。
from sam import SAM
。。.
model = YourModel()
base_optimizer = torch.optim.SGD # define an optimizer for the “sharpness-aware” update
optimizer = SAM(model.parameters(), base_optimizer, lr=0.1, momentum=0.9)
。。.
for input, output in data:
# first forward-backward pass
loss = loss_function(output, model(input)) # use this loss for any training statistics
loss.backward()
optimizer.first_step(zero_grad=True)
# second forward-backward pass
loss_function(output, model(input)).backward() # make sure to do a full forward pass
optimizer.second_step(zero_grad=True)
。。.
總結
雖然SAM的泛化效果較好,但是這種方法的主要缺點是,由于前后兩次計算銳度感知梯度,需要花費兩倍的訓練時間。除此之外,SAM還在最近發布的NFNETS上證明了它的效果,這是ImageNet目前的最高水平,在未來,我們可以期待越來越多的論文利用這一技術來實現更好的泛化。
英文原文:https://pub.towardsai.net/we-dont-need-to-worry-about-overfitting-anymore-9fb31a154c81
編輯:lyn
-
SAM
+關注
關注
0文章
118瀏覽量
34397 -
深度學習
+關注
關注
73文章
5599瀏覽量
124400 -
pytorch
+關注
關注
2文章
813瀏覽量
14853
原文標題:【過擬合】再也不用擔心過擬合的問題了
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
鈣鈦礦/硅疊層電池首次通過IEC濕凍測試:基于pH調控的共SAM策略

PyTorch 中RuntimeError分析
《Altium Designeder 25電路設計精講實踐》SAM V71章節有感
Atmel SAM C20系列微控制器:工業自動化的理想之選
Atmel SAM3S系列32位Flash微控制器深度剖析
Atmel | SMART SAM3S系列MCU:高集成與低功耗的完美結合
深入解析AT91SAM7SE512/256/32:強大的ARM基Flash MCU
SAM(通用圖像分割基礎模型)丨基于BM1684X模型部署指南
水浸超聲掃描顯微鏡(C-SAM)與其他無損檢測技術對比分析

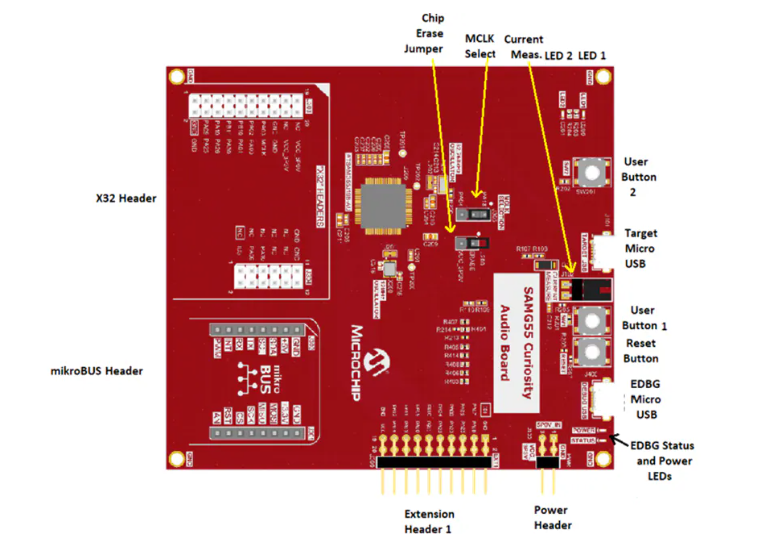
?SAM G55音頻開發板技術解析與應用指南
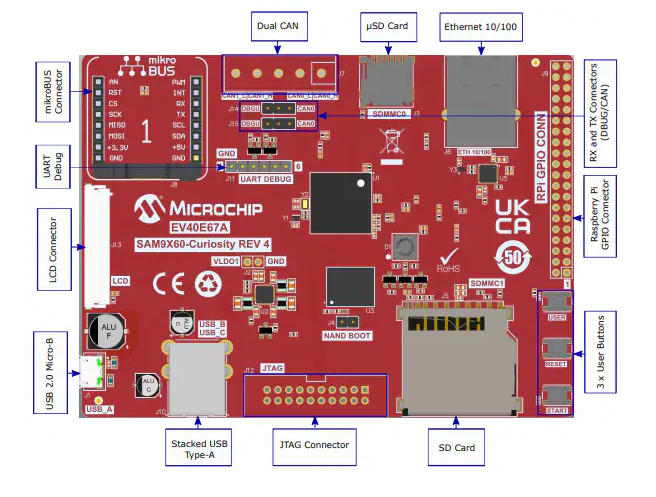
SAM9X60-Curiosity評估板:高性能嵌入式開發的理想起點
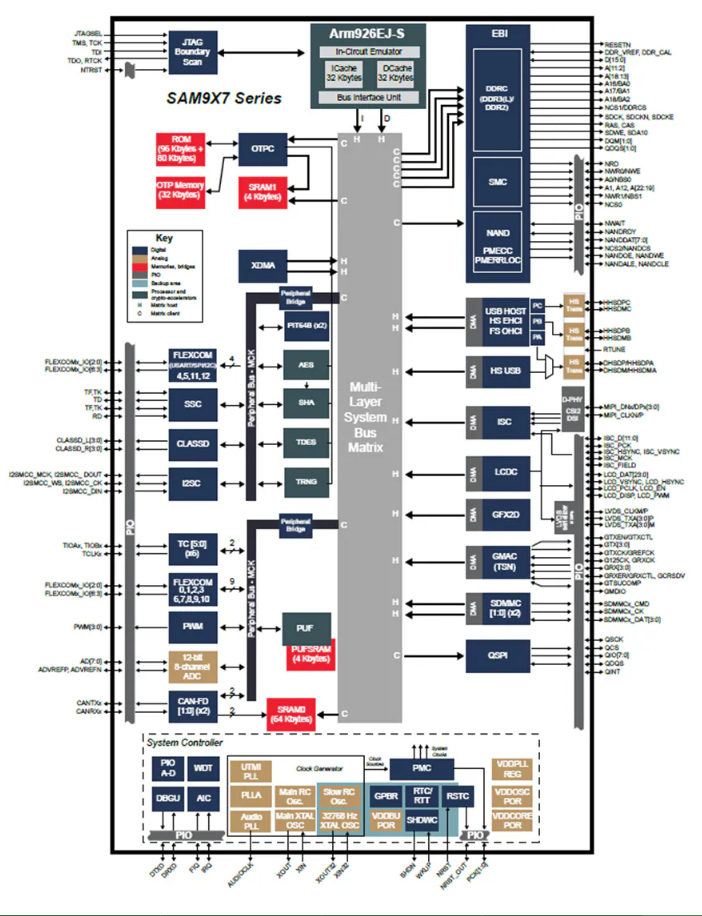
Microchip SAM9X7 系列:面向高性能嵌入式系統的超低功耗 Arm? MPU
Zettabyte任命Sam Lawn為全球首席財務官
橢偏儀與DIC系統聯用測量半導體超薄圖案化SAM薄膜厚度與折射率




 工商網監
工商網監
評論