 口語語言理解在任務型對話系統中的探討
口語語言理解在任務型對話系統中的探討

1.1 研究背景與任務定義
口語語言理解在任務型對話系統中扮演了一個非常重要的角色,其目的是識別出用戶的輸入文本中蘊含的意圖和提及到的槽位,一般被分為意圖識別和槽位填充兩個子任務[1]。以句子“use netflix to play music”為例,意圖識別將整個句子的意圖分類為播放音樂(PlayMusic),槽位填充為句子中的每個單詞賦予不同的槽位標簽(即,O, B-service,O,O,O)。從任務類型來區分,意圖識別屬于句子分類任務,槽位填充可以被建模成序列標注任務。 與英文口語語言理解相比,中文口語語言理解面臨了一個獨特的挑戰:在完成任務之前需要進行詞語切分。盡管事先做了分詞,不完美的分詞系統仍然會錯誤識別槽位的邊界,隨即預測了錯誤的槽位類別,使得模型的性能遭受來自分詞系統的錯誤級聯。

圖1 中文口語語言理解示例
1.2 研究動機
為了避免來自分詞系統的錯誤級聯,Liu等人[2]提出了一個基于字符的聯合模型完成中文口語語言理解,達到了當時最好的效果。
然而,直觀上,中文詞語信息的引入有助于對中文文本的理解,進而正確完成意圖識別和槽位填充任務。
以圖1為例,正確的中文分詞為"周冬雨 / 有 / 哪些 / 電影"。如果不引入這種分詞信息作為補充,可能會給"周"賦予Datetime_date槽位標記,將"冬雨"看作Datetime_time。而有了類似于"周冬雨"這樣詞語的幫助,檢測正確的槽位標簽Artist會變得異常容易。
除此之外,由于口語語言理解由兩個類型不同又相互關聯的任務組成,利用任務間的交互可以對在兩個任務間建模細粒度的詞語信息遷移起到重要的幫助。
所以,在考慮任務特性的同時引入詞語信息是很有必要的。
因此,接下來的問題是:是否可以在避免分詞系統錯誤級聯、考慮口語語言理解任務特性的同時,引入中文詞語信息增強中文意圖識別和槽位填充。
為了解決此問題,我們提出了簡單而有效的Multi-LevelWordAdapter (MLWA)模型引入中文詞語信息,對意圖識別和槽位填充進行聯合建模。其中,1) sentence-level word adapter 直接融合詞級別和字級別的句子表示實現對意圖的識別;2) character-level word adapter 針對輸入文本中的每個字動態地確定不同字特征和不同詞特征之間的融合比例,進而得出該字的槽位標簽,以達到對詞語知識的細粒度組合這一目的。另外,word adapter可以作為一個依附于輸出層的插件被應用于各種基于字符的中文口語語言理解模型,其無需改變原始模型其他分量的特性帶來了更多的應用靈活性。
2. 模型
2.1 整體框架
模型以一個普通的基于字符的模型(圖2 (a))為基礎,附以multi-level word adapter模塊(圖2 (b))針對意圖識別和槽位填充分別引入并捕獲句子級和字符級詞語信息。
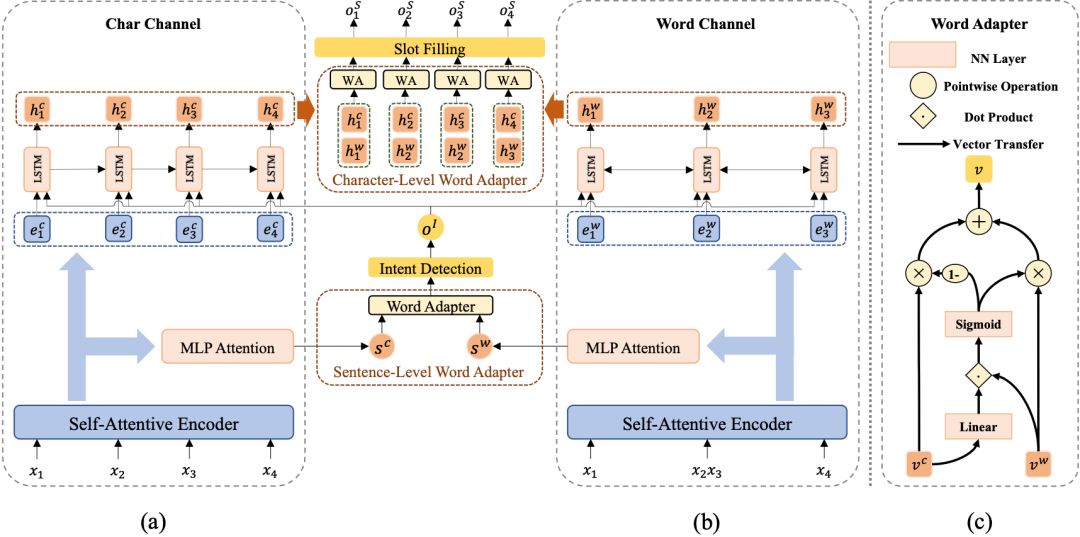
圖2 Multi-Level Word Adapter 整體框架
2.2 Vanilla Character-based Model
Char-Channel Encoder
自注意力編碼器(Self-Attentive Encoder)[3]由抽取序列上下文信息的自注意力模塊[4]和捕獲序列信息的雙向LSTM[5]組成。其接收中文字輸入序列 = ,獲得BiLSTM和self-attention的輸出后,連接兩者輸出字符編碼表示序列 = 。
Intent Detection and Slot Filling
意圖識別和槽位填充均以自注意力編碼器的輸出為基礎,進行進一步的編碼,即兩者共享底層表示信息。其中,意圖識別模塊利用一個MLP Attention模塊獲得整個字序列的綜合表示向量 ,進而完成對意圖的分類(意圖標簽集表示為 ):
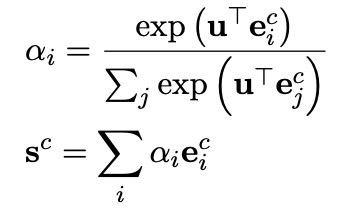
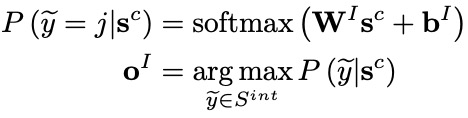
槽位填充應用一個單向LSTM作為解碼器,在每個解碼時間步 ,其接收每個字表示 ,意圖標簽編碼 ,來自上一個時間步解碼的槽位標簽編碼 ,輸出解碼器隱層向量 ,進而計算得到第 個字 的槽位標簽(槽位標簽集表示為 ):
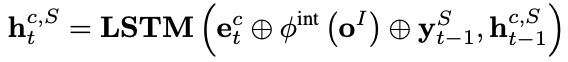
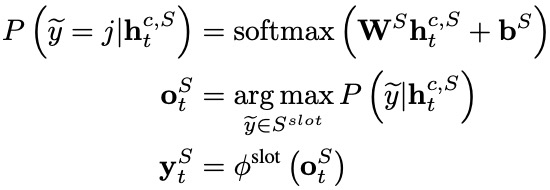
2.3 Multi-Level Word Adapter
Word-Channel Encoder
在我們的框架中,單詞通道編碼器獨立于字符通道編碼器,也就是說,如何編碼單詞信息,編碼何種單詞信息都是自由的,在這里以使用外部中文分詞系統(CWS)為例。對字序列 進行分詞可以得到單詞序列 = 。與字符通道編碼器相同,單詞通道編碼器利用另一個自注意力編碼器生成單詞編碼表示序列 = 。
Word Adapter
word adapter 是一個簡單的神經網絡,可以適應性地融合不同的字特征的詞語特征,圖2 (c)顯示了其內部結構。給定輸入字符向量 和詞語向量 ,word adapter可以計算兩者之間的權重比例,進而加權求和得到融合后的特征向量:
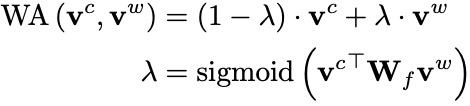
Sentence-Level Word Adapter
給定字符序列和單詞序列的上下文表示序列 和 ,可以通過上文的MLP Attention模塊獲得兩種序列的綜合表示向量 和 。
隨后,sentence-level word adapter計算融合后的綜合向量 ,并利用它預測意圖標簽 :
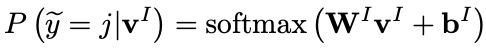
Character-Level Word Adapter
在完成槽位填充之前,我們首先采納一個雙向LSTM增強單詞序列的表示。在每個時間步 ,單詞通道的槽位填充編碼器輸出的隱層向量由相應的單詞表示 和意圖標簽的編碼 計算得到。
然后,character-level word adapter針對每個輸入字符,為字符特征和詞語特征的不同組合確定不同的融合比例:
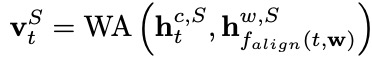
最后,我們利用融合后的表示 完成第 個字符的槽位標注:
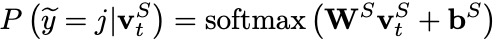
2.4 Joint Training
我們采納聯合訓練策略優化模型,最終的聯合目標函數如下, and 分別是正確的意圖和槽位標簽:
3. 實驗
3.1 實驗設置
數據集
我們在兩個公開的中文數據集CAIS和ECDT-NLU上進行了實驗,我們保持了兩個數據集原分割不變。
CAIS中, 訓練集包含7995個句子,驗證集和測試集分別有994和1024個句子。
ECDT-NLU由2576個訓練樣本和1033個測試樣本組成。
評價指標
與前人相同,我們使用以下三個指標來評價中文口語語言理解模型的性能:
F1值作為槽位填充任務的評價指標。
準確率(accuracy)作為意圖識別任務的評價指標。
使用整體準確率(overall accuracy)指標評價句子級語義幀解析能力。一個整體準確的預測表示預測的意圖和槽位標簽與人工標注完全相同。
3.2 主實驗結果
表1 主實驗結果

所有的baseline模型均考慮了意圖識別和槽位填充兩個任務之間的相關性,并聯合建模這兩個相關任務。從結果可以看出:
我們的實驗結果在所有指標上均超過了這些baseline模型,達到了當前最好的性能,證明了我們提出的multi-level word adapter的有效性。
Slot和Intent指標的提升表明利用multi-level word adapter融入單詞信息可以促進模型對于中文意圖和槽位的識別和標注。
整體準確率的提升歸因于考慮了兩個任務之間的相關性,并通過聯合訓練相互增強兩者。
3.3 消融實驗結果
為了驗證已提出的word adapters的有效性,我們對以下幾個重要分量執行了消融實驗:
w/o Multiple Levels 設置中,我們移除了character-level word adapter,在對每個字符的槽位標記時使用相同的單詞信息。
w/o Sentence-Level word adapter 設置中,不使用sentence-level word adapter,只使用字序列編碼信息去完成意圖識別。
w/o Character-Level word adapter 設置中,不使用character-level word adapter,只使用字序列編碼信息去完成槽位填充。
表2 消融實驗結果

上表是消融實驗的結果,從中可以看出:
使用多層次機制帶來了顯著的正向效果,這從側面證實了對于字符級的槽位填充任務,每個字需要不同的單詞信息,即細粒度的詞信息。
不使用sentence-level word adapter時,在ECDT-NLU數據集上,意圖識別準確率出現了明顯的下降,表明sentence-level word adapter可以抽取有利的詞信息去提升中文意圖識別。
不使用character-level word adapter時,兩個數據集上的槽位填充指標出現了不同程度的下降,證明了詞語信息可以為中文槽位填充的完成提供有效的指導信息(例如,明確的單詞信息可以幫助模型檢測單詞邊界)。
3.4 預訓練模型探索實驗
我們進一步在這兩個數據集上探索了預訓練模型的效果。我們將char-channel encoder替換為預訓練模型BERT,模型的其他部分保持不變,進行fine-tuning訓練,來觀察我們提出的multi-level word adapter的效果。
表3 BERT模型探索結果

表3是對于BERT預訓練模型的探索結果。其中,
Joint BERT 利用預訓練模型BERT得到輸入字序列的編碼,經過線性分類層完成意圖識別和槽位填充,隨后應用多任務學習方法進行訓練。
Our Model + BERT 是使用BERT替換掉char-channel encoder作為字序列的Encoder。具體來說,BERT的[CLS]輸出向量作為字序列的綜合向量,其他輸出向量作為各字的表示向量。
實驗結果表明,multi-level word adapter和BERT的結合可以進一步提升模型效果,證明了我們的貢獻與預訓練模型是互補的。
4.結論
在這篇文章中,我們的貢獻如下:
我們首次利用一個簡單有效的方法向中文口語語言理解中引入中文單詞信息。
我們提出了一個多層次的單詞適配器,句子級和字符級單詞適配器分別向意圖識別和槽位填充提供兩個層次的單詞信息表示,從而實現了不同級別任務的詞信息表示定制化。
在兩個公開數據集上進行的實驗表明,我們的模型取得了顯著性的改進,并實現了最佳的性能。此外,我們的方法與預訓練模型(BERT)在性能上是互補的。
原文標題:【工大SCIR】首次探索中文詞信息增強中文口語語言理解!
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
模型
+關注
關注
1文章
3752瀏覽量
52109 -
nlp
+關注
關注
1文章
491瀏覽量
23280
原文標題:【工大SCIR】首次探索中文詞信息增強中文口語語言理解!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Amphenol FlexTraX:創新電纜管理解決方案深度剖析
思必馳任務型對話算法通過國家備案
拉夫勞倫攜手微軟推出對話式AI應用購物助手Ask Ralph
廣和通發布端側情感對話大模型FiboEmo-LLM
米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
Task任務:LuatOS實現“任務級并發”的核心引擎

圖解環路設計及控制技術探討
Aux-Think打破視覺語言導航任務的常規推理范式
深入理解C語言:函數—編程中的“積木塊”藝術

CPU密集型任務開發指導
深入理解C語言:C語言循環控制

基于MindSpeed MM玩轉Qwen2.5VL多模態理解模型




 工商網監
工商網監
評論