") 谷歌在內存方面依賴于per memcg lru lock
谷歌在內存方面依賴于per memcg lru lock

自電子計算機誕生以來,內存性能一直是行業(yè)關心的重點。內存也隨著摩爾定律,在大小和速度上一直增長。現在的阿里云服務器動輒單機接近TB的內存大小,加上數以百記的CPU數量也著實考驗操作系統的資源管理能力。
作為世間最流行的操作系統Linux, 內核使用LRU, Last Recent Used 鏈表來管理全部用戶使用的內存,用一組鏈表串聯起一個個的內存頁,并且使用lru lock來保護鏈表的完整性。
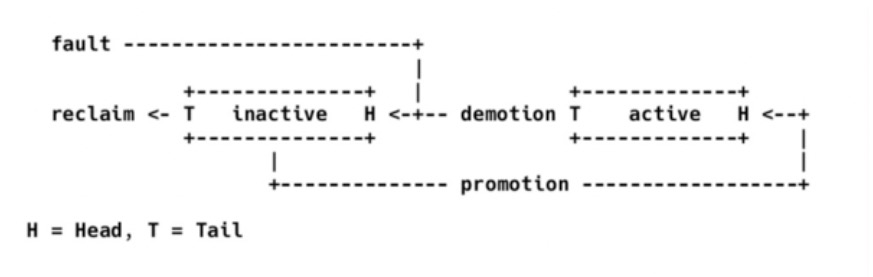
所有應用程序常用操作都會涉及到LRU鏈表操作,例如,新分配一個頁,需要掛在inactive lru 鏈上, 2次訪問同一個文件地址, 會導致這個頁從inactive 鏈表升級到active 鏈表, 如果內存緊張, 頁需要從active 鏈表降級到inactive 鏈表, 內存有壓力時,頁被回收導致被從inactive lru鏈表移除。不單大量的用戶內存使用創(chuàng)建,回收關系到這個鏈表, 內核在內存大頁拆分,頁移動,memcg 移動,swapin/swapout, 都要把頁移進移出lru 鏈表。
可以簡單計算一下x86服務器上的鏈表大小:x86最常用的是4k內存頁, 4GB 內存會分成1M個頁, 如果按常用服務器256GB頁來算, 會有超過6千萬個頁掛在內核lru 鏈表中。超大超長的內存鏈表和頻繁的lru 操作造成了2個著名的內核內存鎖競爭, zone lock, 和 lru lock. 這2個問題也多次在阿里內部造成麻煩, 系統很忙, 但是業(yè)務應用并沒得到多少cpu時間, 大部分cpu都花在sys上了。一個簡單2次讀文件的benchmark可以顯示這個問題, 它可以造成70%的cpu時間花費在LRU lock上。
作為一個知名內核性能瓶頸, 社區(qū)也多次嘗試以各種方法解決這個問題, 例如,使用更多的 LRU list, 或者LRU contention 探測。
但是都因為各種原因被linux 內核拒絕。
尋找解決方案
通過仔細的觀察發(fā)現, 內核在2008年引進內存組-memcg以來, 系統單一的lru lists已經分成了每個內存組一個lru list, 由每個內存組單獨管理自己的lru lists。那么按道理lru lock的contention應該有所減小啊?為什么還是經常在內部服務器觀察到lru lock hot引起的sys 高?
原來, 內核在引入per memcg lru lists后,并沒有使用per memcg lru lock, 還在使用舊的全局lru lock 來管理全部memcg lru lists. 這造成了本來可以自治的memcg A, 卻要等待memcg B 釋放使用的lru lock。然后A拿起的lru lock又造成 memcg C的等待。。。
那么把全局lru lock拆分到每一個memcg中, 不是可以理所當然的享受到了memcg獨立的好處了嗎?這樣每個memcg 都不會需要等待其他memcg 釋放lru lock。鎖競爭限制在每個memcg 內部了。

要完成lru lock 拆分,首先要知道lru lock 保護了多少對象, 通常情況中, page lru lock需要保護lru list完整性, 這個是必須的。與lru list相關的還有page flags中的lru bit,這個lru bit用作頁是否在lru list存在的指示器, 可以避免查表才能知道頁是否在list中。那么lru lock保護它也說的通。
但是lru lock 看起來還有一些奇怪的保護對象,承擔了一些不屬于它的任務:
1.PageMlock bit,保護 munlock_vma 和split_huge_page 沖突,
其實, 上述2個函數在調用鏈中都需要 page lock, 所以沖突可以完全由page lock來保證互斥。這里lru lock使用屬于多余。
2.pagecache xa_lock和memcg->move_lock,
xa_lock并沒有需要lru lock保護的場景,這個保護也是多余。相反,lru lock放到xa_lock 之下, 符合xa_lock/lock_page_memcg, 的使用次序。反而可以優(yōu)化 lru lock 和 memcg move_lock的關系。
3.lru bit in page_idle_get_page, 用在這里是因為擔心 page_set_anon_rmap中, mapping 被提前預取訪問,造成異常。用memory barrier 方式可以避免這個預取, 所以可以在page idle中撤掉lru lock.
+ WRITE_ONCE(page->mapping, (struct address_space *) anon_vma);
經過這樣的修改, lru lock 可以在memory lock 調用層次中降級到最底層。
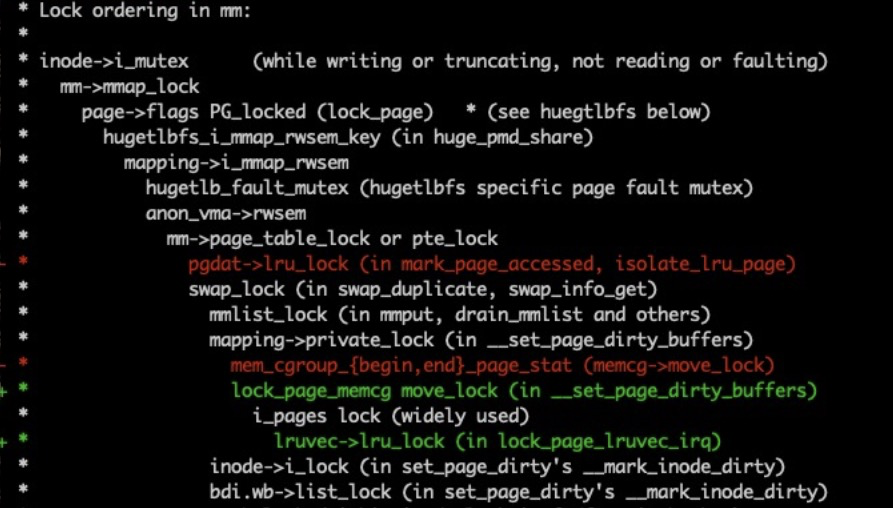
這時, lru lock已經非常簡化,可以用per memcg lru lock來替換全局的lru lock了嗎?還不行,使用per memcg lru lock 有一個根本問題,使用者要保證 page所屬的memcg不變,但是頁在生命周期中是可能轉換memcg的,比如頁在memcg之間migration,導致 lru_lock隨著memcg變化, 拿到的lru lock是錯誤的,好消息是memcg 變化也需要先拿到lru lock鎖,這樣我們可以獲得lru lock之后檢查這個是不是正確的鎖:
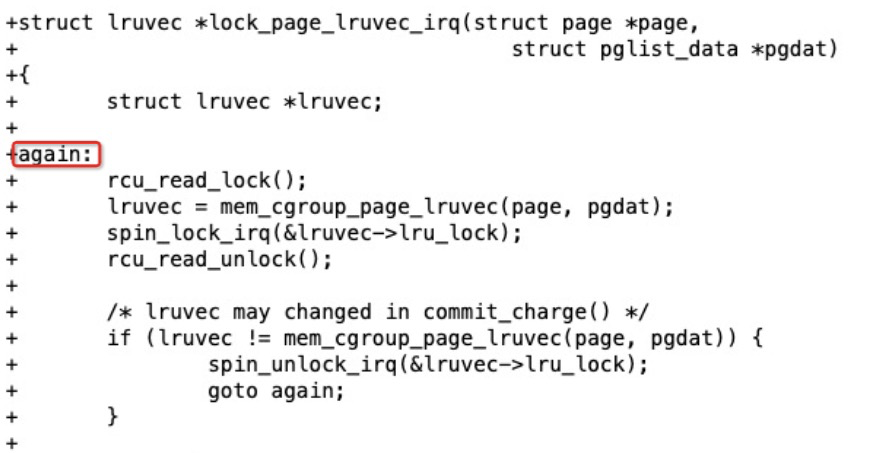
如果不是, 由反復的relock 來保證鎖的正確性。bingo! 完美解決!
由此, 這個feature曲折的upstream 之路開始了。。。
最終解決
這個patchset 2019年發(fā)出到社區(qū)之后, google的 Hugh Dickins 提出, 他和facebook的Konstantin Khlebnikov 同學已經在2011發(fā)布了非常類似的patchset,當時沒有進主線。不過google內部生產環(huán)境中一直在使用。所以現在Hugh Dickins發(fā)出來他的upstream版本。關鍵路徑和我的版本是一樣的
2個相似patchset的PK, 引起了memcg 維護者Johannes 的注意, Johannes發(fā)現在compaction的時候, relock并不能保護某些特定場景:
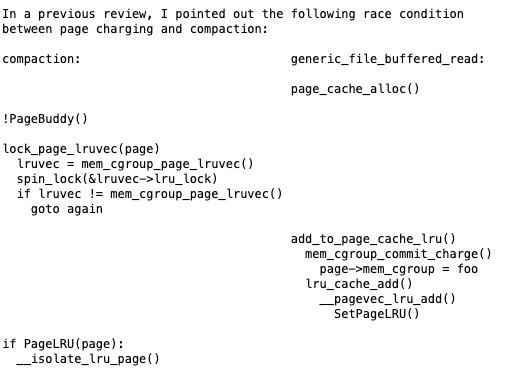
所以他建議,也許增加原子的lru bit操作作為 lru_lock 的前提也許可以保護這個場景。Hugh Dickins 則不認為這樣會有效,并且堅持他patchset已經在google內部用了9年了。一直安全穩(wěn)定。。。
Johannes的建議的本質是使用lru bit代替lru lock做page isolation互斥,但是問題的難點在其他地方, 比如在通常的一個swap in 的場景中:

swap in 的頁是先加入lru, 然后charge to memcg, 這樣造成頁在加入lru 時,并不知道自己會在那個memcg上, 我們也拿不到正確的per memcg lru_lock, 所以上面場景中左側CPU 即使提前檢查PageLRU 也找不到正確的lru lock 來阻止右面cpu的操作, 然并卵。
正確的解決方案, 就是上面第9步移動到第7步前面, 在加入lru前charge to memcg. 并且在取得lru lock之前檢查lru bit是否存在, 這樣才可以保證我們可以拿到的是正確的memcg 的lru lock。由此提前清除/檢查lru bit的方法才會有效。這個memcg charge的上升, 在和Johannes討論后, Johannes在5.8 完成了代碼實現并且和入主線。
在新的代碼基礎上, 增加了lru bit的原子操作TestClearPageLRU, 把lru bit移出了lru lock的保護,相反用這個bit來做page isolation的互斥條件, 用isolation來保護頁在memcg間的移動, 讓lru lock只完成它的最基本任務, 保護lru list完整性。至此方案主體完成。lru lock的保護對象也由6個減小到一個。編碼實現就很容易了。

測試結果
方案完成后, 上面提到的file readtwice 測試中,多個memcg的情況下,lru lock 競爭造成的sys 從70% 下降了一半,throughput 提高到260%。(80個cpu的神龍機器)

Upstream過程
經過漫長4輪的逐行review, 目前這個feature 已經進入了 linus的 5.11 https://github.com/torvalds/linux
第一版patch 發(fā)到了社區(qū)后, google的skakeel butt立刻提出, google曾經在2011發(fā)過一樣的patchset來解決 per memcg lru lock 問題。所以,skakeel 要求我們停止自己開發(fā), 基于google的版本來解決這個問題。然后我才發(fā)現真的2011年 google Hugh Dickins 和 Facebook Konstantin Khlebnikov 就大約同時提出類似的patchset。, 但是當時引起的關注比較少,也缺乏benchmark來展示補丁的效果, 所以很快被社區(qū)遺忘了。不過google內部則一直在維護這組補丁,隨他們內核版本升級。
對比google的補丁, 我們的實現共同點都是使用relock來確保page->memcg線性化, 其他實現細節(jié)則不盡相同。測試表明我們的patch性能更好一點。于是我基于自己的補丁繼續(xù)修改并和Johannes討論方案改進。這也導致了以后每一版都有google同學的反對:我們的測試發(fā)現你的patchset 有bug, 請參考google可以工作的版本。并在linux-next上發(fā)現一個小bug時達到頂峰:https://lkml.org/lkml/2020/3/6/627 google同學批評我們抄他們的補丁還抄出一堆bug.

其實這些補丁和Hugh Dickins的補丁毫無關聯, 并且在和Johannes的持續(xù)討論中,解決方案的核心:page->memcg的線性化已經進化了幾個版本了, 從relock 到 lock_page_memcg, 再到TestClearPageLRU. 和google的補丁是路線上的不同。
面對這樣的無端指責,memcg 維護者 Johannes 看不下去, 出來說了一些公道話:我和Alex同學都在嘗試和你不同的方案來解決上次提出的compacion沖突問題,而且我記得你當時是覺得這個沖突你無能為力的:

之后google同學分享了他們的測試程序,然后在這個話題上沉默了一段時間。
后來memcg charge的問題解決后, 就可以用lru bit來保證page->memcg互斥了。v17 coding很快完成后。intel 的Alexander Duyck, 花了5個星期, 逐行逐字的review整個patchset, 并其基于補丁的改進, 提出了一些后續(xù)優(yōu)化補丁。5個星期的review, 足以讓一個feature 錯過合適的內核upstream 窗口。但是也增強了社區(qū)的信心。
(重大內核的feature 的merge窗口是這樣的:大的feature 在進入linus tree之前, 要在linux-next tree 待一段時間, 主要的社區(qū)測試如Intel LKP, google syzbot 等等也會在著重測試Linux-next。所以為了保證足夠的測試時間, 進入下個版本重要feature 必須在當前版本的rc4之前進入linux-next。而當前版本-rc1通常bug比較多, 所以最佳rebase 版本是 rc2, 錯過最佳merge 窗口 rc2-rc4. 意味著需要在等2個月到下一個窗口。并且還要適應新的內核版本的相關修改。)
基于5.9-rc2的 v18 版本完成后, google hugh dickins同學強勢歸來,主動申請測試和review,根據他的意見v18 做了很多刪減和合并,甚至推翻了一些Alexander Duyck要求的修改。patch 數量從32個壓縮到20個。Hugh Dickin 逐行review 了整整4個星期。也完美錯過了5.10和入窗口。之后v19, Johannes 同學終于回來開始review. Johannes比較快,一個星期就完成了review。現在v20, 幾乎每個patch 都有了2個reviewed-by: Hugh/Johannes.
然而, 這次不像以前, 以前 patchset 沒有人關心, 這次大家的review興趣很大,來了就停不住, SUSE的 Vlastimil Babka 同學又過來開始review, 并且提出了一些coding style 和代碼解釋要求。不過被強勢的Hugh Dickins 駁回:

Hugh 的影響力還是很大的, Vlastimil 和其他潛在的reivewer都閉上了嘴。代碼終于進了基于5.10-rc 的 linux-next。不過這個駁回也引起一個在5.11提交窗口的麻煩, memory總維護者 Andrew Morthon突然發(fā)現Vlastimil Babka 表示過一些異議。所以他問我:是不是輿論還不一致, 還有曾經推給你一個bug, 你解決了嗎?
I assume the consensus on this series is 'not yet"?
Hugh再次出來護場:我現在覺得patchset 足夠好了, 足夠多人review過足夠多的版本了, 已經在linux-next 安全運行一個多月了,沒有任何功能和性能回退, Vlastimil也已經沒有意見了。至于那個bug, Alex有足夠的證據表明和這個補丁無關。。。
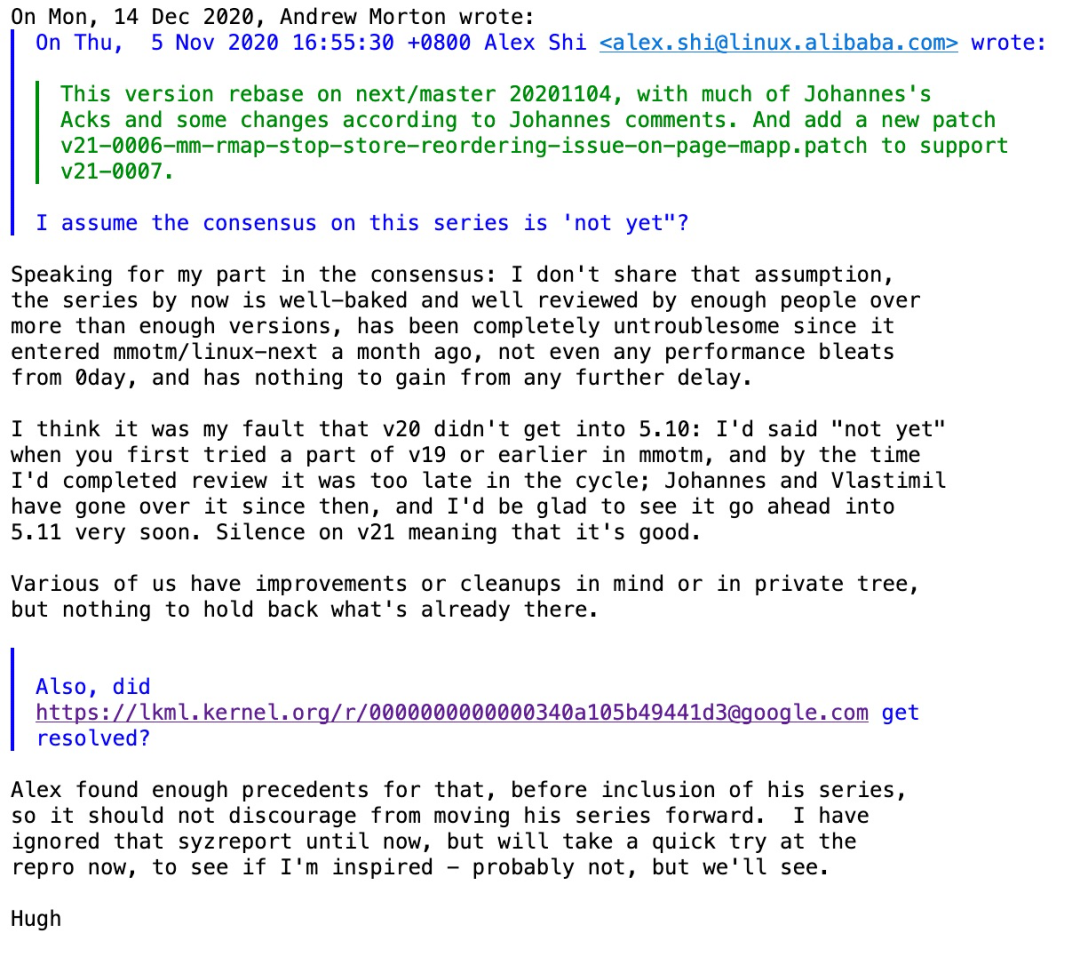
最終這個patchset享受到了Andrew 向 Linus單獨推送的待遇。進了5.11。
后記
在 Linux 上游做事情,有很多成就感,也可以保證自己需要的feature,一直在線, 免去了內核升級維護之苦。但也會面臨荊棘和險阻, 各種內部不關心的場景都要照顧到, 不能影響其他任何人的feature。所以相比coding, 大量的社區(qū)討論大概是coding的3~5倍時間,主要是反復的代碼解釋和修改.
在整個upstreaming的過程中特別值得一提的是一些google的同學態(tài)度轉變, 從一開始的反對,到最后加入我們。從google方面來說, google在內存方面有很多優(yōu)化都依賴于per memcg lru lock. 這個代碼加入內核也解除了他們9年來的代碼維護痛苦。
原文標題:memcg lru lock 血淚史
文章出處:【微信公眾號:Linuxer】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
Linux
+關注
關注
88文章
11758瀏覽量
219009 -
操作系統
+關注
關注
37文章
7401瀏覽量
129282
原文標題:memcg lru lock 血淚史
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
RK平臺新聲卡添加與驅動調試指南


博世可編程柵極驅動器ASIC EG120的核心技術解析

Amphenol 38999 Ram-Lock 推拉接口連接器:設計與應用指南
Molex Mini-Lock SMT接頭技術解析與應用指南
為什么單片機中很少使用malloc,而PC程序頻繁使用呢?
請問OTA是否一定依賴于ymodem協議?
什么是MES,為什么MES系統難以標準化?

瀾起科技憑借在內存接口和高速互連芯片領域的突破性創(chuàng)新榮膺《財富》中國科技50強
一次消諧器核心功能依賴于其非線性電阻材料

集裝箱智能識別系統主要依賴哪些技術?

【創(chuàng)龍TL3562-MiniEVM開發(fā)板試用體驗】Grove移植9之LCD
擺脫依賴英偉達!OpenAI首次轉向使用谷歌芯片
時間的力量:RTC如何賦能萬物精準運行?




 工商網監(jiān)
工商網監(jiān)
評論