 NLP:用Cluster-to-Cluster生成更多樣化的新數據
NLP:用Cluster-to-Cluster生成更多樣化的新數據

論文名稱:C2C-GenDA: Cluster-to-Cluster Generation for Data Augmentation of Slot Filling 論文作者:侯宇泰、陳三元、車萬翔、陳成、劉挺 原創作者:侯宇泰 論文鏈接:https://arxiv.org/abs/2012.07004 出處:哈工大SCIR
1. 簡介
1.1 研究背景
對話語言理解(Spoken Language Understanding,SLU)[1]經常面臨領域和需求的頻繁切換,這常常會導致訓練數據在數量和質量上的不足。
數據增強(Data Augmentation)是一種自動生成新數據擴充訓練集的技術,能夠有效地緩解上述數據不足的帶來的挑戰 [2,3]。
1.2 研究動機
如圖1(上)所示,現有數據增強,如基于Seq2Seq 的句子復述(re-phrasing)方法 [4,5,6],經常無法避免地生成沒有意義的重復數據。這很大程度要歸咎于現有的one-by-one數據生成模式。
相較之下,如圖1(下)所示,one-by-one數據生成弊病可以天然地通過多到多(cluster-to-cluster)生成方式得到緩解。
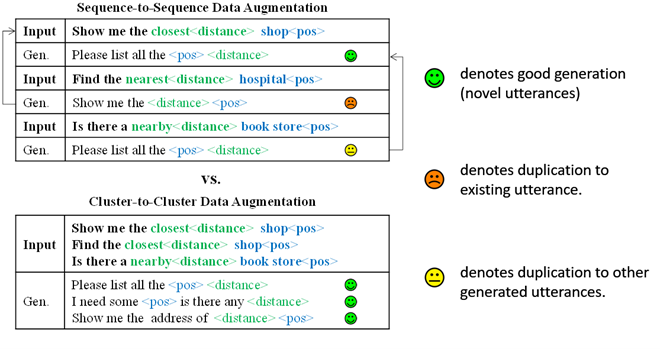
圖1 示例:從已有句子生成新表述,現有one-by-one復述方法無法避免生成重復數據
1.3 我們的貢獻
我們提出了一種全新的Cluster-to-Cluster生成范式來生成新數據,并基于此提出了一個全新的數據增強框架,稱為C2C-GenDA。C2C-GenDA通過將現有句子重構為表達方式不同但語義相同的新句子,來擴大訓練集。與過往的Data Augmentation(DA)方法逐句(One-by-one)構造新句子的做法不同,C2C-GenDA采用一種多到多(Cluster-to-Cluster)的全新的新語料生成方式。
具體的,C2C-GenDA聯合地編碼具有相同語義的多個現有句子,并同時解碼出多個未見表達方式的新句子。
這樣種的生成方式會直接帶來如下好處:
(1)同時生成多個新話語可以讓模型建模生成的新句子之間的關系,減少新句子間內部重復。
(2)聯合地對多個現有句子進行編碼讓模型可以更廣泛地看到已有的現有表達式,從而減少無意義的對已有數據的重復。
1.4實驗效果
當只有數百句訓練語料時,C2C-GenDA數據增強方法在了兩個公開的槽位提取(slot filling)數據集上分別帶來了 7.99 (11.9%↑) and 5.76 (13.6%↑) F-scores 的提升。
2. 方法
2.1 Cluster2Cluster 生成模型
給定具有相同語義框架(semantic frame)的一組多個句子,即input cluster, 模型一次性生成多個新句子,即output cluster。這些輸出與輸入的語義框架相同,但是具有不同的表達方式。
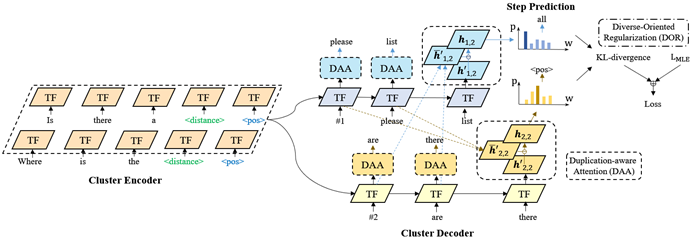
圖2 Cluster2Cluster 生成模型
如圖2所示,Cluster2Cluster模型采用基于Transformer的Encoder和Decoder。具體的,我們用特殊分割Token拼接input cluster中的句子,作為模型輸入。在解碼時,模型用多個共享參數的decoder同步解碼多個新句子。
我們采用了前人添加Rank Token作為解碼起步的方法[5]來讓模型區分不同的輸出句子。
同時,為了進一步提升句子的多樣性,我們提出Duplication-aware Attention和Diverse-Oriented Regularization來進一步強化模型,如圖2所示:
(1)Duplication-aware Attention(DAA):通過Attention為模型提供兩方面的信息,即Input Cluster中已有的表達方式,和其他正在解碼的句子中的表達方法。根據這些信息,我們采用一種類似Coverage Attention的方式對重復的表達生成進行懲罰。
(2)Diverse-Oriented Regularization(DOR):我們提出DOR來從Loss層面引導模型生成多樣的句子。具體的,我們用不同句子,解碼詞分布之間的KL-散度作為loss,來約束模型避免在不同的句子中的相同step解碼出相同的詞。
2.2 Cluster2Cluster 模型訓練
僅有多到多的生成模型顯然不足以生成新的數據。為了讓Cluster2Cluster模型具有生成新表述的能力,我們提出了Dispersed Cluster Pairing算法來構造多到多的復寫(Paraphrase)訓練數據。
具體的,如圖3 和圖4所示,給定具有相同語義的一組數據,我們首先找到一組表述相近的句子作為Input Cluster,然后貪心地構造Output Cluster:每次添加一句和Input Cluster以及現有Output Cluster表述差異最大的句子到 Output Cluster。
這樣的作法旨在模擬從少量說法有限的句子生成多樣的未見表述的過程。

圖3構造多到多的Paraphrase訓練數據

圖4多到多的Paraphrase訓練數據構造算法
2.3 數據增強實現
我們將原有的訓練數據分為兩份,一份訓練C2C-GenDA模型,一份用來做數據增強的輸入。
最后我們用所有新生成的句子和原有的句子作為增強后的訓練集。
3. 實驗:
3.1 主實驗結果
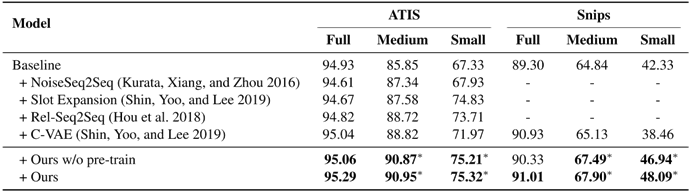
如表1所示,我們的方法能夠大幅地提升Slot Filling模型效果(Baseline),并優于現有的數據增強方法。
表1 主實驗結果
3.2 分析實驗
如表2所示,在消融實驗中,我們提出的各個模塊都對最終的實驗效果起到了作用。
表2 消融實驗
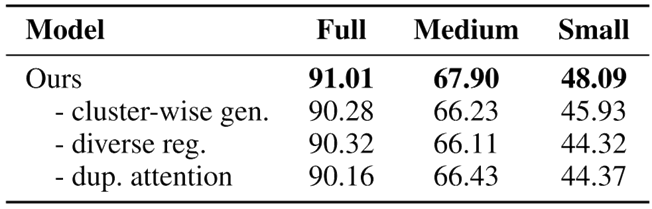
表3展示不同生成模型的生成數據和Inter和Intra多樣性,結果顯示采用Cluster2Cluster的生成方法可以讓新數據的多樣性產生巨大的提升。
表3 多樣性分析實驗
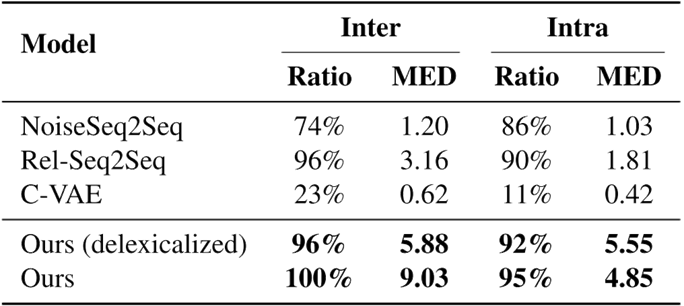
表4展示了由Cluster2Cluster模型生成的一些樣例,可以看到Cluster2Cluster模型可以從多個角度生成一些有趣的新表述方式。
表4 樣例分析

4.參考文獻
[1] Young, S.; Gasiˇ c, M.; Thomson, B.; and Williams, J. D. ′ 2013. Pomdp-based statistical spoken dialog systems: A review. Proc. of the IEEE 101(5): 1160–1179.
[2] Kim, H.-Y.; Roh, Y.-H.; and Kim, Y.-G. 2019. Data Augmentation by Data Noising for Open-vocabulary Slots in Spoken Language Understanding. In Proc. of NAACL, 97– 102.
[3] Shin, Y.; Yoo, K. M.; and Lee, S.-G. 2019. Utterance Generation With Variational Auto-Encoder for Slot Filling in Spoken Language Understanding. IEEE Signal Processing Letters 26(3): 505–509.
[4] Yoo, K. M. 2020. Deep Generative Data Augmentation for Natural Language Processing. Ph.D. thesis, Seoul National University
[5] Hou, Y.; Liu, Y.; Che, W.; and Liu, T. 2018. Sequence-to-Sequence Data Augmentation for Dialogue Language Understanding. In Proc. of COLING, 1234–1245.
[6] Kurata, G.; Xiang, B.; and Zhou, B. 2016. Labeled Data Generation with Encoder-Decoder LSTM for Semantic Slot Filling. In Proc. of INTERSPEECH, 725–729.
責任編輯:xj
原文標題:【SCIR AAAI2021】數據增強沒效果?試試用Cluster-to-Cluster生成更多樣化的新數據吧
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
數據
+關注
關注
8文章
7335瀏覽量
94755 -
自然語言
+關注
關注
1文章
292瀏覽量
13986 -
nlp
+關注
關注
1文章
491瀏覽量
23280
原文標題:【SCIR AAAI2021】數據增強沒效果?試試用Cluster-to-Cluster生成更多樣化的新數據吧
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
探索DeepSeek多樣化技術路徑,英特爾架構師用至強CPU嘗鮮
探索TRAVEO? T2G Cluster 6M Lite Kit:功能、應用與編程指南
NVIDIA發布Isaac GR00T-Dreams合成數據生成與神經仿真框架
Redis Sentinel和Cluster模式如何選擇
NVIDIA助力湯元科技突破智能駕駛數據獲取與生成瓶頸
iTOF技術,多樣化的3D視覺應用
接口多樣化:M-ITX國產主板的豐富連接性能

T2G Cluster 4M Lite 上的 (S26HL512T) 中的數據在重置后會被覆蓋,如何確保持久性?
華興變壓器:SG-10kVA三相隔離變壓器,定制化服務滿足高海拔地區多樣化需求

介紹三種常見的MySQL高可用方案
適配多種系統,米爾瑞芯微RK3576核心板解鎖多樣化應用
米爾RK3576核心板適配多種系統,解鎖多樣化應用

滿足多樣化需求的 MCX 連接器解決方案

閃迪攜創新閃存解決方案亮相CFMS,以多樣化產品組合賦能企業構建數字世界的"記憶宮殿"




 工商網監
工商網監
評論