 深度學習:四種利用少量標注數據進行命名實體識別的方法
深度學習:四種利用少量標注數據進行命名實體識別的方法

導讀
近年來,深度學習方法在特征抽取深度和模型精度上表現優異,已經超過了傳統方法,但無論是傳統機器學習還是深度學習方法都依賴大量標注數據來訓練模型,而現有的研究對少量標注數據學習問題探討較少。本文將整理介紹四種利用少量標注數據進行命名實體識別的方法。
面向少量標注數據的NER方法分類
基于規則、統計機器學習和深度學習的方法在通用語料上能取得良好的效果,但在特定領域、小語種等缺乏標注資源的情況下,NER 任務往往得不到有效解決。然而遷移學習利用領域相似性,在領域之間進行數據共享和模型共建,為少量標注數據相關任務提供理論基礎。本文從遷移的方法出發,按照知識的表示形式不同,將少量標注數據NER 方法分為基于數據增強、基于模型遷移、基于特征變換、基于知識鏈接的方法。如圖1所示,在這 20 多年間,四種方法的發文數量基本呈上升趨勢,整體而言,當前的研究以數據增強、模型遷移為主,而其他的方法通常配合前兩種方法使用,在研究中也值得關注。
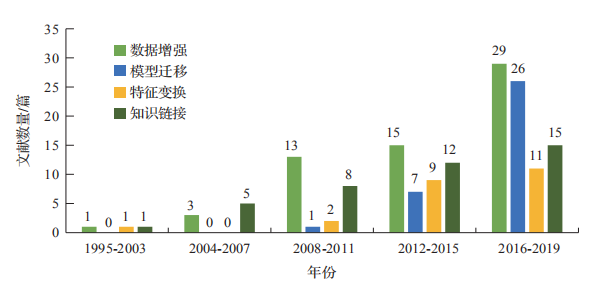
圖1 1995年-2019年四種方法的使用情況
基于數據增強的NER方法
數據增強的方法即:在少量數據集訓練模型導致過擬合時,通過樣本選擇、權重調整等策略以創建高質量樣本集,再返回分類器中迭代學習,使之能夠較好地完成學習任務的方法。
(1)樣本選擇。在面向少量標注數據時,最直接的策略是挑選出高質量樣本以擴大訓練數據。其中,樣本選擇是數據增強式 NER 的核心模塊,它通過一定的度量準則挑選出置信度高、信息量大的樣本參與訓練,一種典型的思路為主動學習采樣,例如 Shen 等利用基于“不確定性”標準,通過挖掘實體內蘊信息來提高數據質量。在實踐中,對于給定的序列 X=(x1, x2,…xi) 和標記序列Y=(y1, y2,…yi),x 被預測為 Y 的不確定性可以用公式(1)來度量,其中 P(y) 為預測標簽的條件分布概率,M 為標簽的個數,n 為序列的長度:
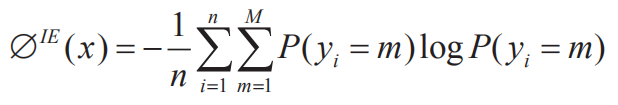
為了驗證主動學習采樣的性能,在人民日報(1998 年)語料中進行實驗,共迭代十次,其中 Random 為迭代中隨機采樣,ALL 為一次訓練完所有數據的結果,Active-U 為利用數據增強的結果。實驗結果(如圖 2)表明,利用數據增強方法在第 7 次迭代中就能達到擬合,節省了 30% 的標注成本。
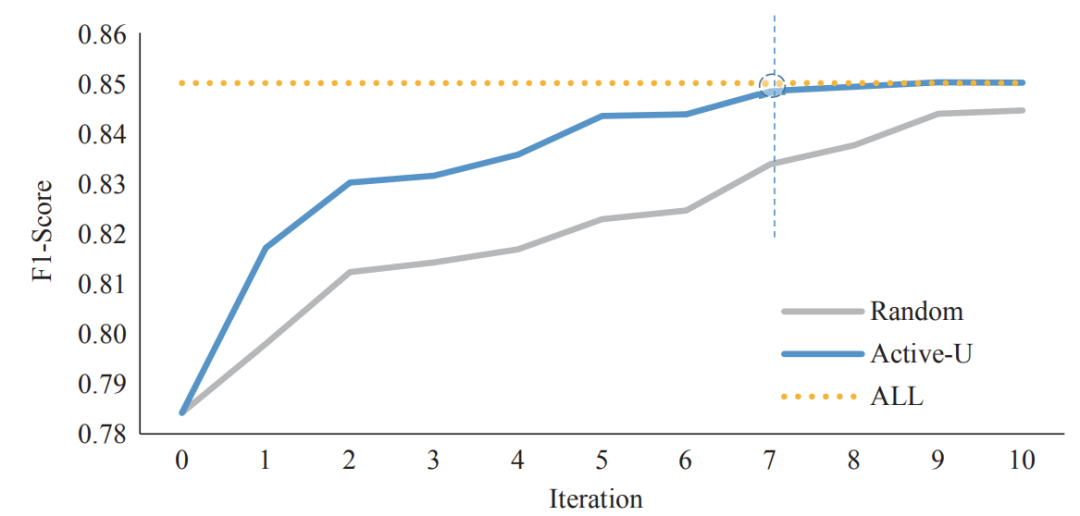
圖2基于數據增強方法的實例
也有不同學者利用其他的度量準則,例如高冰濤等人通過評估源域樣本在目標領域中的貢獻度,并使用單詞相似性和編輯距離,在源域樣本集和目標樣本集上計算權值來實現迭代學習。Zhang 等人充分考慮領域相似性,分別進行域區分、域依賴和域相關性計算來度量。這些方法利用無監督模式通過降低統計學習的期望誤差來對未標記樣本進行優化選擇,能夠有效減少標注數據的工作量。此外,半監督采樣也是一種新的思路。例如在主動學習的基礎上加入自學習(Self-Training)、自步學習(Self-Paced Learning,SPL)過程,這些方式通過對噪聲樣本增大學習難度,由易到難地控制選擇過程,讓樣本選擇更為精準。
(2)分類器集成。在數據增強中,訓練多個弱分類器來獲得一個強分類器的學習方式也是一種可行的思路。其中典型的為 Dai 等人提出集成式 TrAdaBoost 方法,它擴展了 AdaBoost 方法,在每次迭代的過程中,通過提高目標分類樣本的采樣權重、降低誤分類實例樣本的權重來提高弱分類器的學習能力。TrAdaBoost 利用少量的標簽數據來構建對源域標簽數據的樣本增強,最后通過整合基準弱分類器為一個強分類器來進行訓練,實現了少樣本數據的學習。之后的研究針對 TrAdaBoost 進行了相應的改進也取得了不錯的效果。例如,王紅斌等人在分類器集成中增加遷移能力參數,讓模型充分表征語義信息,在 NER 中提高精度也能顯著減少標注成本。
基于模型遷移的NER方法
基于模型遷移的基本框架如圖 3 所示,其核心思想是利用分布式詞表示構建詞共享語義空間,然后再遷移神經網絡的參數至目標領域,這是一種固定現有模型特征再進行微調(Fine-Tuning) 的方法,在研究中共享詞嵌入和模型參數的遷移對 NER 性能產生較大影響。
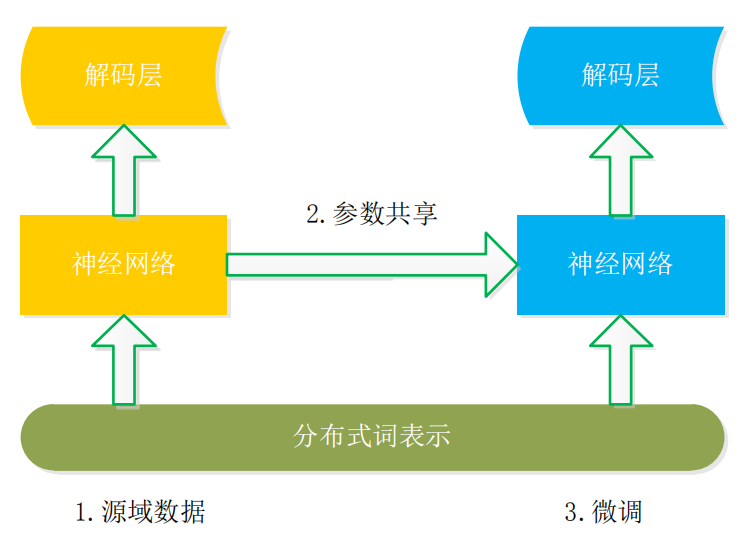
圖3模型遷移基本結構
(1)共享詞嵌入。在 NLP 中,前期工作通常會借助語言預訓練模型學習文本的詞義信息,這種方式構建了公共的詞嵌入表示空間,詞嵌入在 NER 中通常作為輸入。詞向量是共享詞嵌入的初步形式,此后,ELMo模型利用上下文信息的方式能解決傳統詞向量不擅長的一詞多義問題,還能在一定程度上對詞義進行預測逐漸受到人們關注。而 2018 年谷歌提出的 BERT預訓練模型更是充分利用了詞義和語義特性,BERT 是以雙向 Transformer為編碼器棧的語言模型,它能強有力地捕捉潛在語義和句子關系,基于 BERT 的 NER 在多個任務上也取得 state-of-the-art,其基本網絡結構如圖4所示。
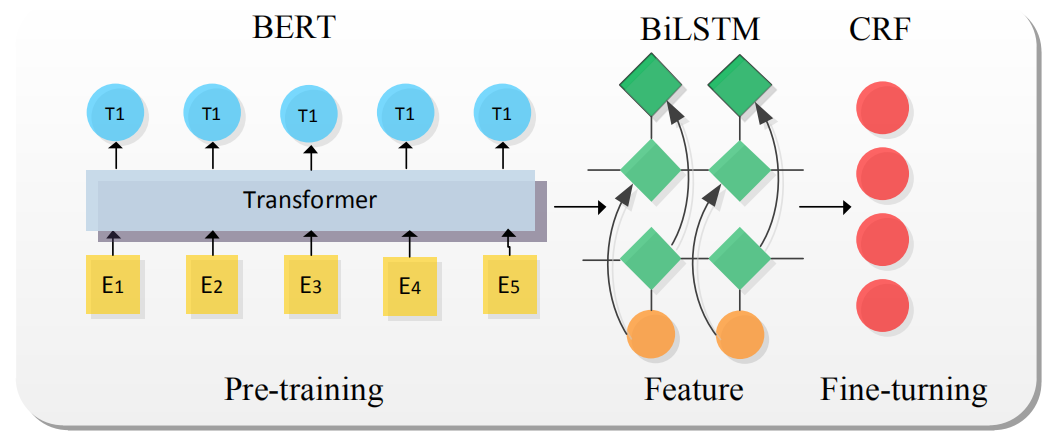
圖4模型遷移的基礎方法-BERT-BiLSTM-CRF
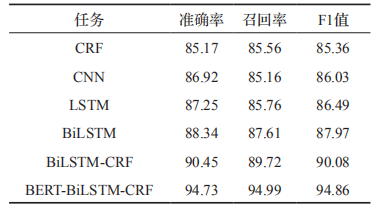
其中 BERT 作為語義表示輸入,BiLSTM抽取特征,CRF 獲取概率最大標簽。與傳統的NER 模型相比,該模型最關鍵的是 BERT 語言模型的引入,BERT 通過無監督建模的方式學習海量互聯網語義信息,能充分表征實體的語義信息。在人民日報(1998年)語料中進行實驗,實驗結果(如表 1)表明,基于 BERT 的預訓練遷移學習模型能有效提高分類的準確率。
表1BERT-BiLSTM-CRF與其他方法的比較
(2)共享參數。共享詞嵌入側重于詞義的表示,而共享參數則側重于模型參數的遷移。例如,Jason 等人從神經網絡遷移機制以及遷移哪些層進行大量實驗,實驗結論顯示淺層網絡學習知識的通用特征,具有很好的泛化能力,當遷移到第 3 層時性能達到飽和,繼續遷移會導致“負遷移”的產生。Giorgi 等人基 于 LSTM 進行網絡權重的遷移,首先將源領域模型參數遷移至目標領域初始化,之后進行微調使適應任務需要。而 Yang 等人從跨領域、跨應用、跨語言遷移出發測試模型遷移的可行性, 在 一 些 benchmarks 上實現了 state-of-the-art。整體而言,在處理 NER 任務時良好的語義空間結合深度模型將起到不錯的效果,在遷移過程中模型層次的選擇和適應是難點。
基于特征變換的NER方法
在面向少量標注數據 NER 任務時,我們希望遷移領域知識以實現數據的共享和模型的共建,在上文中我們從模型遷移的角度出發,它們在解決領域相近的任務時表現良好,但當領域之間存在較大差異時,模型無法捕獲豐富、復雜的跨域信息。因此,在跨領域任務中,一種新的思路是在特征變換上改進,從而解決領域數據適配性差的問題。基于特征變換的方法是通過特征互相轉移或者將源域和目標域的數據特征映射到統一特征空間,來減少領域之間差異的學習過程,下面主要從特征選擇和特征映射的角度進行探討。
(1)特征選擇。即通過一定的度量方法選取相似特征并轉換,在源域和目標域之間構建有效的橋梁的策略。例如 Daume 等人通過特征空間預處理實現目標域和源域特征組合,在只有兩個域的任務中,擴展特征空間 R^F 至 R^3F,對應于域問題,擴展特征空間至 R^(K+1)F。然而當 Yi 與 YJ 標簽空間差異較大時,這種線性組合效果可能不理想,Kim 等人從不同的角度出發,進行標簽特征的變換,第一種是將細粒度標簽泛化為粗粒度標簽。例如源域標簽中
(2)特征映射。即為了減少跨領域數據的偏置,在不同領域之間構建資源共享的特征空間,并將各領域的初始特征映射到該共享空間上。利用預測的源標簽嵌入至目標領域是一種常見策略。例如,Qu 等人從領域和標簽差異出發,首先訓練大規模源域數據,再度量源域和目標域實體類型相關性,最后通過模型遷移的方式微調。其基本步驟為:
1、通過 CRF學習大規模數據的知識;
2、使用雙層神經網絡學習源域與目標域的命名實體的相關性;
3、利用 CRF 訓練目標域的命名實體。
實驗結果顯示相較于 Baseline 方法 Deep-CRF,TransInit 方法能提高 160% 的性能。
標簽嵌入的方式在領域之間有較多共享標簽特征時遷移效果不錯,但是這種假設在現實世界中并不普遍。一種新的思路是在編解碼中進行嵌入適配(如圖 5),這種方式利用來自預訓練源模型的參數初始化 Bi-LSTM-CRF 基礎模型,并嵌入詞語、句子和輸入級適配。具體而言,在詞級適配中,嵌入核心領域詞組以解決輸入特征空間的領域漂移現象。在句子級適配中,根據來自目標域的標記數據,映射學習過程中捕獲的上下文信息。在輸出級適配中將來自 LSTM 層輸出的隱藏狀態作為其輸入,為重構的 CRF 層生成一系列新的隱藏狀態,進而減少了知識遷移中的損失。
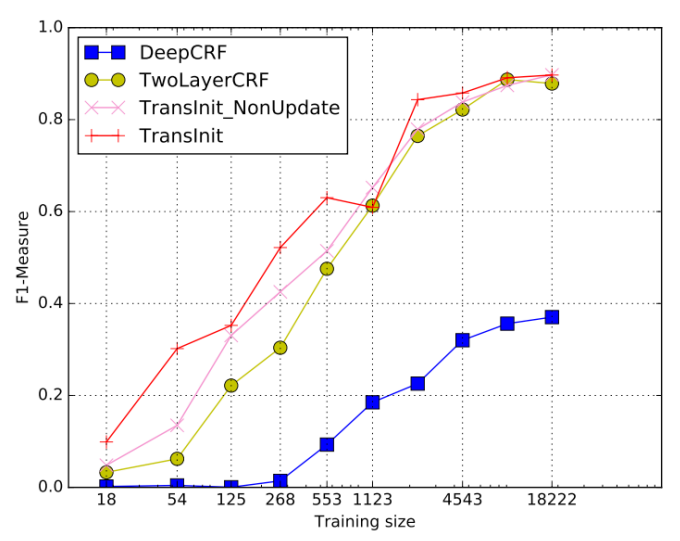
圖5特征變換方法TransInit實驗結果
基于知識鏈接的NER方法
基于知識鏈接的 NER,即使用本體、知識庫等結構化資源來啟發式地標記數據,將數據的結構關系作為共享對象,從而幫助解決目標 NER 任務,其本質上是一種基于遠程監督的學習方式,利用外部知識庫和本體庫來補充標注實體。例如 Lee 等人的框架(如圖 6),在 Distant supervision 模塊,將文本序列與 NE詞典中的條目進行匹配,自動為帶有 NE 類別的大量原始語料添加標簽,然后利用 bagging和主動學習完善弱標簽語料,從而實現語料的精煉。一般而言,利用知識庫和本體庫中的鏈接信息和詞典能實現較大規模的信息抽取任務,這種方法有利于快速實現任務需求。
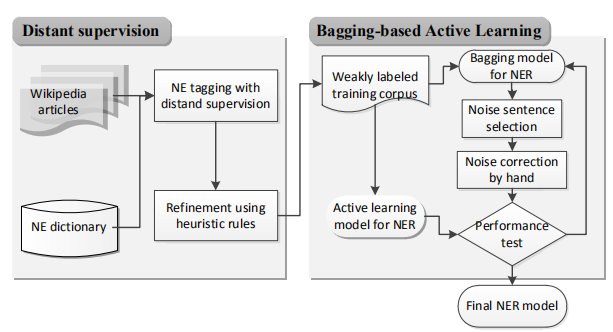
圖6知識鏈接與數據增強結合模型
(1)基于知識庫。這種方式通常借用外部的知識庫來處理 NER、關系抽取、屬性抽取等任務,在現實世界中如 Dbpedia、YAGO、百度百科等知識庫存在海量結構化信息,利用這些知識庫的結構化信息框、日志信息可以抽取出海量知識。例如,Richman 等人利用維基百科知識設計了一種 NER 的系統,這種方法利用維基百科類別鏈接將短語與類別集相關聯,然后確定短語的類型。類似地,Pan 等人利用一系列知識庫挖掘方法為 200 多種語言開發了一種跨語言的名稱標簽和鏈接結構。在實踐中,較為普遍的是聯合抽取實體和實體關系。例如Ren 等的做法,該方法重點解決領域上下文
無關和遠程監督中的噪聲問題,其基本步驟為:
1、利用 POS 對文本語料進行切割以獲得提及的實體;
2、生成實體關系對;
3、捕獲實體與實體關系的淺層語法及語義特征;
4、訓練模型并抽取正確的實體及關系。
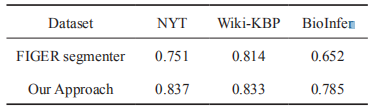
在 NYT 等語料上進行實驗(如表 2),基于知識庫的方法相較于基線方法有顯著提高。
表2不同語料下實體的F1值
(2)基于本體系統。該方式通過一定的規則,將本體庫中的概念映射為實體。例如史樹敏等人通過構建的 MPO 本體,首先利用CRF 獲得高召回率的實體,再融合規則過濾噪聲,最終獲得較為精確的匹配模式。相似地,Lima 等人通過開發出 OntoLPER 本體系統,并利用較高的表達關系假設空間來表示與實體—實體關系結構,在這個過程中利用歸納式邏輯編程產生抽取規則,這些抽取規則從基
于圖表示的句子模型中抽取特定的實體和實體關系實例。同樣地,李貫峰等人首先從 Web網頁提取知識構建農業領域本體,之后將本體解析的結果應用在 NER 任務中,使得 NER 的結果更為準確。這些方法利用本體中的語義結構和解析器完成實體的標準化,在面向少量標注的 NER 中也能發揮出重要作用。
四種方法比較
上述所介紹的 4 種面向少量標注的 NER 方法各有特點,本文從領域泛化能力、模型訓練速度、對標注數據的需求和各方法的優缺點進行了細致地比較,整理分析的內容如表 3 所示。
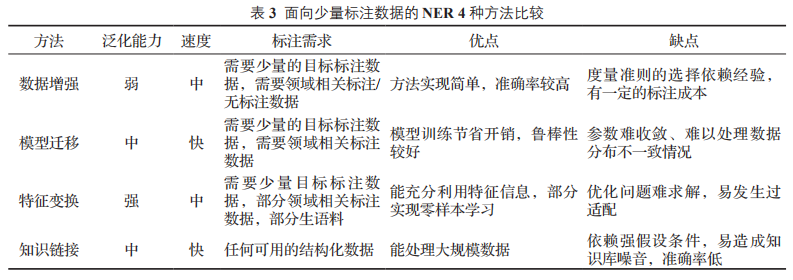
面向少量標注數據 NER,最直接的方法是數據增強,通過優先挑選高質量樣本參與訓練,這種方法在窄域中能實現較高的準確率。但是針對不同領域所需的策略也不同,領域的泛化能力一般。模型遷移從海量無結構化文本中獲取知識,這種方式對目標領域的數據需求較少,只需“微調”模型避免了重新訓練的巨大開銷,但是它依賴領域的強相關性,當領域差異性太大時,容易產生域適應問題。
相較于模型遷移,特征變換更加注重細粒度知識表示,這種方法利用特征重組和映射,豐富特征表示,減少知識遷移中的損失,在一定程度上能實現“零樣本”學習,但是這種方法往往難以求出優化解,過適配現象也會造成消極影響。知識鏈接能利用任何結構化信息,通過知識庫、本體庫中的語義關系來輔助抽取目標實體,但是這種方法易產生噪聲,實體的映射匹配依賴強假設條件,所需的知識庫通常難以滿足領域實體的抽取。
方法評測比較
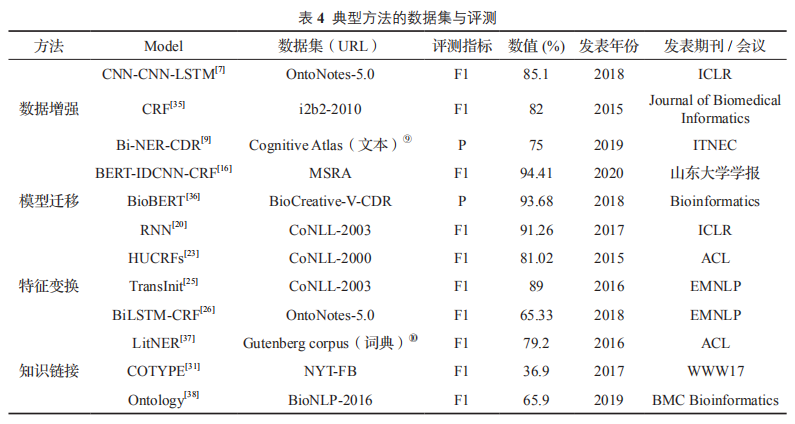
如表4所示四類面向少量標注數據的典型方法與評測信息如下:
結語
當有大量標注數據可供模型訓練時,NER任務往往能夠得到很好的結果。但是在一些專業領域比如生物醫藥領域,標注數據往往非常稀缺,又由于其領域的專業性,需要依賴領域專家進行數據標注,這將大大增加數據的標注成本。而如果只用少量的標注數據就能得到同等效果甚至更好的效果,這將有利于降低數據標注成本。
參考資料:
[1]石教祥,朱禮軍,望俊成,王政,魏超.面向少量標注數據的命名實體識別研究[J].情報工程,2020,6(04):37-50.
責任編輯:xj
原文標題:綜述 | 少量標注數據下的命名實體識別研究
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
數據
+關注
關注
8文章
7335瀏覽量
94755 -
深度學習
+關注
關注
73文章
5598瀏覽量
124396 -
nlp
+關注
關注
1文章
491瀏覽量
23280
原文標題:綜述 | 少量標注數據下的命名實體識別研究
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛數據標注是所有信息都要標注嗎?

【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
WTK6900FC鼾聲識別芯片在四種助眠場景中的應用

電壓放大器在全導波場圖像目標識別的損傷檢測實驗的應用

如何深度學習機器視覺的應用場景
一圖看懂綠電直連的四種玩法
從入門到精通:基于開源代碼的BLE四種模式開發詳解
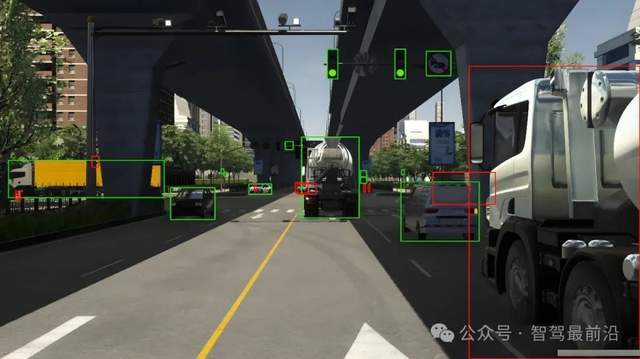
自動駕駛數據標注主要是標注什么?
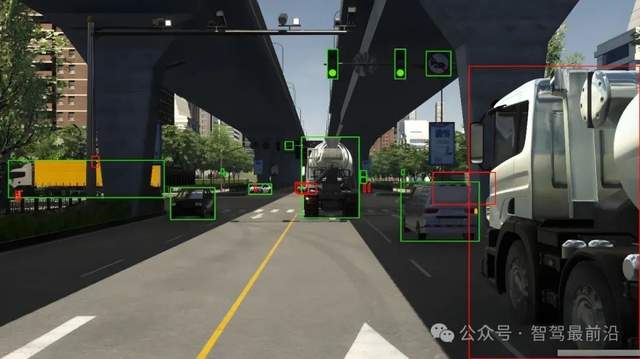
什么是自動駕駛數據標注?如何好做數據標注?
任正非說 AI已經確定是第四次工業革命 那么如何從容地加入進來呢?
RDMA簡介3之四種子協議對比

風華電容命名方法深度解析
數據標注服務—奠定大模型訓練的數據基石
標貝數據標注服務:奠定大模型訓練的數據基石




 工商網監
工商網監
評論