 解讀NLPCC最佳學生論文:數據和預訓練模型
解讀NLPCC最佳學生論文:數據和預訓練模型

在2020年初開始的新冠病毒蔓延影響下,NLPCC 2020采取線上+線下的會議方式,線上線下共繳費注冊496人,其中現場參會總人數達372人,線上參會人數124人,另有15個贊助單位參展。匯聚了眾多國內外NLP領域的知名學者。 本次會議總投稿數是445篇,會議有效投稿404篇。其中,主會有效總投稿377篇,Workshop有效投稿27篇。 在主會377篇有效投稿中,英文論文315篇,中文論文62篇;接收Oral論文83篇,其中英文論文70篇,中文論文13篇,錄用率為22%;接收Poster 論文30篇。Workshop共計錄取14篇論文。 在本次會議上評選出最佳論文、最佳學生論文各1篇,并進行了頒獎儀式。 來自清華大學朱小燕、黃民烈團隊的王義達作為一作發表的《A Large-Scale Chinese Short-Text Conversation Dataset》獲得了最佳學生論文,以下是王義達本人對獲獎論文的親自解讀。

基于Transformer的大規模預訓練語言模型極大地促進了開放領域對話的研究進展。然而目前這一技術在中文對話領域并未被廣泛應用,主要原因在于目前缺乏大規模高質量的中文對話開源數據。 為了推動中文對話領域的研究,彌補中文對話語料不足這一問題,我們發布了一個包含1200萬對話的大規模中文對話數據集LCCC,并開源了在LCCC上預訓練的大規模中文對話生成模型CDial-GPT。 開源地址:https://github.com/thu-coai/CDial-GPT 1
LCCC數據集的構建
LCCC(Large-scale Cleaned Chinese Conversation)數據集有LCCC-base與LCCC-large兩個版本,其中LCCC-base和LCCC-large中各包含6.8M和12M對話。這些數據是從79M原始對話數據中經過嚴格清洗得到的,也是目前所開源的規模最大、清洗最嚴格的中文對話數據集。
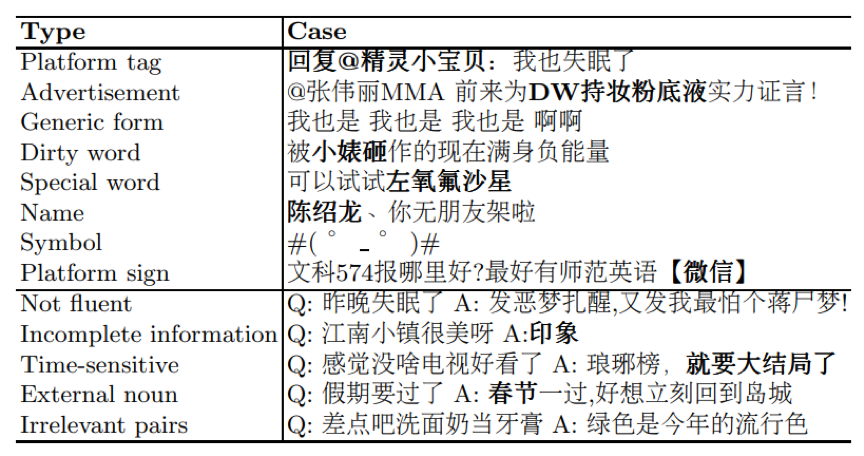
表1. 被過濾掉的噪音數據 開放領域對話數據的構建通常有三種方式:1、抽取劇本對話;2、人工眾包構建對話;3、爬取社交媒體上用戶的交流記錄。 使用第一種方式構建的對話在內容上依賴于特定劇情和場景,與日常對話有較大差異。使用第二種方式構建的對話質量最高,但是由于人力成本過高,無法使用這一方式構建大規模數據集。使用第三種方式可以較為廉價地獲取大規模對話數據,因此LCCC數據集中的原始數據主要使用第三種方式收集。 我們同時注意到,來自社交媒體的對話數據中存在各種各樣的噪音(表1),為了保證LCCC中對話數據的質量,我們設計了如下數據獲取和清洗策略:
1. 數據獲取我們的數據獲取流程分為兩個階段。在第一個階段,我們挑選了微博上由專業媒體團隊運營的新聞媒體賬號,然后收集了一批在這些新聞媒體下留言互動的活躍用戶。在第二個階段中,我們收集了這些活躍用戶微博下的留言互動,并將其作為我們的原始數據。微博下的留言回復一般以一個樹形結構展開,我們將這一樹形回復結構中每一條從根節點到葉子節點的路徑作為一個完整對話,最終共收集到了79M對話數據。
2. 數據清洗為了保證數據質量,我們對收集到的原始對話數據進行了兩個階段的清洗。 第一階段的清洗主要基于手工規則。這一階段的主要目的是為了過濾掉對話數據中的明顯噪聲,如臟話、特殊符號、病句、復讀機句式、廣告、違法暴力信息等。在這一階段中,我們花費了數周時間使用人工排查的方式優化規則。
第二階段的清洗主要基于分類器過濾。在這一階段中,我們基于BERT訓練了兩個文本分類器,第一個分類器主要用于甄別那些無法通過規則檢測的噪音,如:1、語義模糊、語法錯亂或有嚴重拼寫錯誤的語句;2、時效性太強的對話;3、與上下文語義不相關的回復。 第二個分類器主要用于甄別那些需要依賴額外上下文信息,如圖片或視頻等,才能理解的對話。這兩個分類器均使用人工標注數據訓練,我們為其標注了共計11萬對話數據,最終的分類器在人工標注的測試集上分別達到了73.76%和77.60%的準確率。我們通過F1-score選擇閾值來過濾得到高質量的對話數據。
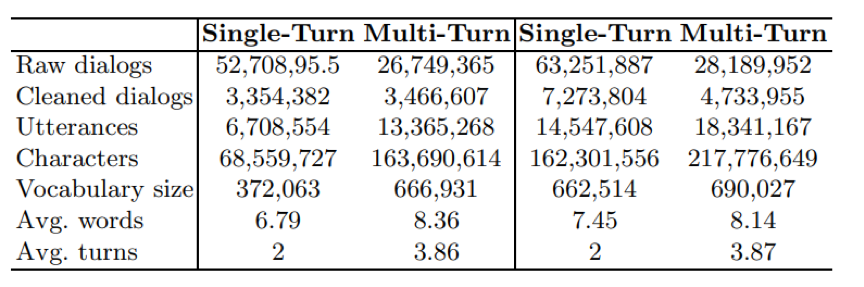
表2. 數據統計信息,左側為LCCC-base,右側為LCCC-large 最終我們基于上述原始對話數據過濾得到了6.8M高質量的對話數據LCCC-base。此外,我們還收集了目前已公開的其他對話數據,并使用同樣的清洗流程,結合LCCC-base構造了包含12M對話的數據集LCCC-large。表2展示了這兩個數據集中單輪對話和多輪對話的詳細統計信息。 2
中文對話預訓練模型CDial-GPT
為促進中文對話預訓練模型的發展,我們基于LCCC數據集預訓練了大規模中文對話生成模型CDial-GPT。該模型的訓練過程包含兩個階段,首先,我們在總計5億字符、包含各類題材的小說數據上訓練得到了一個中文小說GPT預訓練模型,然后在該模型的基礎上,我們使用LCCC中的對話數據繼續對模型進行訓練,最終得到了中文對話預訓練模型CDial-GPT。
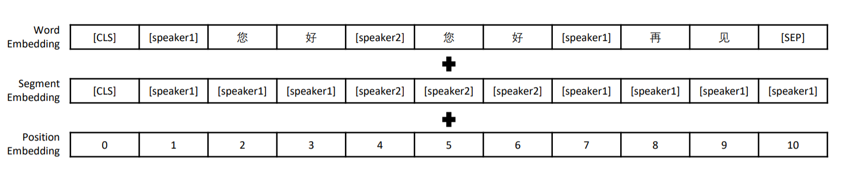
圖1. 輸入編碼示例 該模型擁有12層Transformer結構,我們按字分詞,字典大小13088,字向量維度768,最長上下文長度為513。我們沿用TransferTransfo的方式對對話進行建模,即把對話歷史拼接為長文本,并使用段分割向量加以區分。具體來說:我們使用[CLS]字符標志文本起始,在段落后使用[SEP]字符表示段落結束,在段落中對相鄰輪次對話使用[speaker1]、[speaker2]交替分割,并在segment embedding中使用[speaker1]、[speaker2]進行編碼。圖1為輸入數據示例。 3
模型效果評測
為了評估對話預訓練模型的質量,我們在440萬規模的中文對話數據集STC上對其進行了評測實驗,并對比了現有的中文對話預訓練模型和一些經典的非預訓練對話模型。我們主要通過PPL這一指標來反映模型的擬合能力,PPL越低表示模型的擬合能力越強。我們通過基于n-gram重合度的指標BLEU和基于Embedding相似度的指標Greedy Matching 和Embedding Average來衡量對話回復與真實回復的相關性,并通過Dist-n指標來衡量生成回復的多樣性。實驗結果展示在表3中。可以看到我們的模型在絕大多數指標上達到了最好的效果。由于自動指標無法完全反映生成對話的質量,于是我們對各模型生成的對話進行了人工評測。
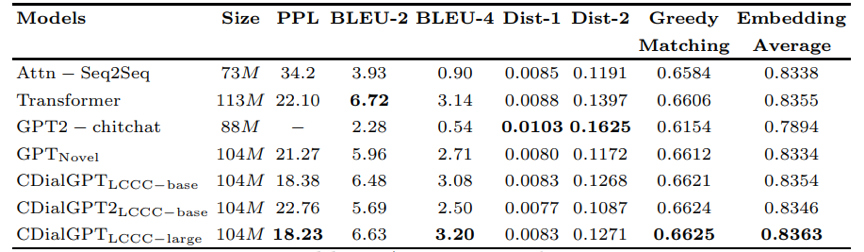
表3. 自動指標評估
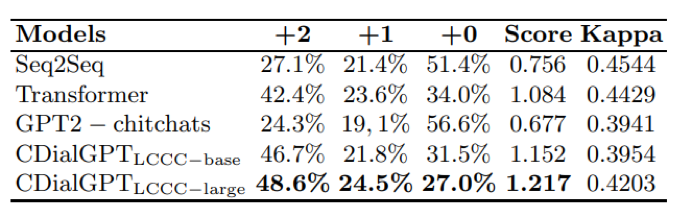
表4. 人工評價 在人工評測中我們主要考慮3個方面:1、語法性,也就是生成語句的流暢性;2、相關性,即生成語句與對話上文的相關性;3、信息量,即生成結果自身含有的信息量。具體來說,不符合語法性或與對話上文不相關的生成結果我們給予0分;語句流暢、和對話上文相關但信息量不足的生成結果給予1分;語句流暢、和對話上文相關并且信息量充足的生成結果給予2分,我們將人工評測結果展示在表4中。實驗結果顯示,我們的預訓練模型擁有出色的生成質量,可以在生成信息量充足的回復的同時,保持較高的流暢性與相關性,優于其他基線模型,一些生成例子展示在表5,6中。
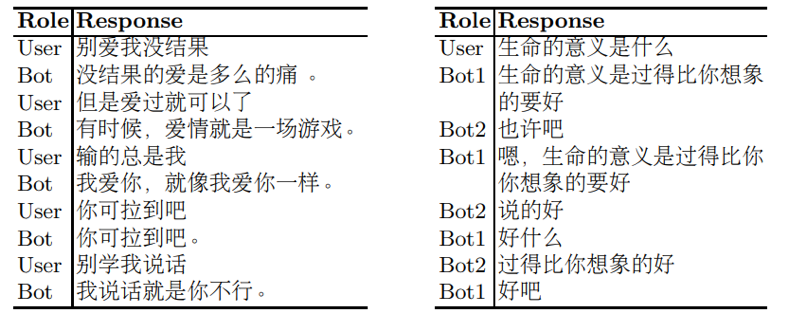
表5. 人機交互示例 (左)和 模型互相交互示例(右)
表6.在STC微調的生成結果示例 目前CDial-GPT模型以及LCCC數據集都已公開,我們提供了訓練以及微調代碼,可以方便地應用于各種數據和下游任務上。
責任編輯:xj
原文標題:一作解讀NLPCC最佳學生論文:1200萬中文對話數據和預訓練模型CDial-GPT
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
數據
+關注
關注
8文章
7335瀏覽量
94773 -
nlp
+關注
關注
1文章
491瀏覽量
23280 -
訓練模型
+關注
關注
1文章
37瀏覽量
4071
原文標題:一作解讀NLPCC最佳學生論文:1200萬中文對話數據和預訓練模型CDial-GPT
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
從訓練到推理:大模型算力需求的新拐點已至

什么是大模型,智能體...?大模型100問,快速全面了解!
自動駕駛大模型的訓練數據有什么具體要求?

基于大規模人類操作數據預訓練的VLA模型H-RDT

Analog Devices LT6654 AMPS6-3.3器件參數特性解讀 EDA模型 數據手冊免費下載
大模型時代的深度學習框架

請問如何在imx8mplus上部署和運行YOLOv5訓練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集


憶聯PCIe 5.0 SSD支撐大模型全流程訓練



 工商網監
工商網監
評論