 TensorFlow Lite (TFLite) 在內存使用方面的改進
TensorFlow Lite (TFLite) 在內存使用方面的改進

文 /Juhyun Lee 和 Yury Pisarchyk,軟件工程師
由于資源限制嚴重,必須在苛刻的功耗要求下使用資源有限的硬件,因此在移動和嵌入式設備上進行推理頗有難度。在本文中,我們將展示 TensorFlow Lite (TFLite) 在內存使用方面的改進,更適合在邊緣設備上運行推理。
中間張量
一般而言,神經網絡可以視為一個由算子(例如 CONV_2D 或 FULLY_CONNECTED)和保存中間計算結果的張量(稱為中間張量)組成的計算圖。這些中間張量通常是預分配的,目的是減少推理延遲,但這樣做會增加內存用量。不過,如果只是以簡單的方式實現,那么在資源受限的環境下代價有可能很高,它會占用大量空間,有時甚至比模型本身高幾倍。例如,MobileNet v2 中的中間張量占用了 26MB 的內存(圖 1),大約是模型本身的兩倍。
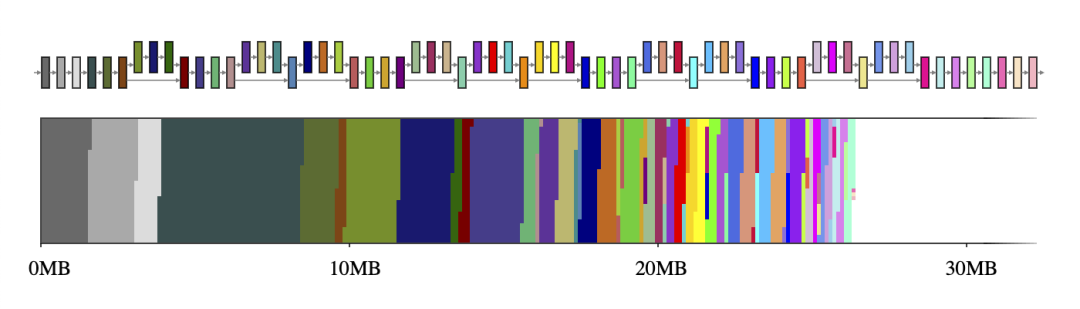
圖 1. MobileNet v2 的中間張量(上圖)及其到二維內存空間大小的映射(下圖)。如果每個中間張量分別使用一個專用的內存緩沖區(用 65 種不同的顏色表示),它們將占用約 26MB 的運行時內存
好消息是,通過數據相關性分析,這些中間張量不必共存于內存中。如此一來,我們便可以重用中間張量的內存緩沖區,從而減少推理引擎占用的總內存。如果網絡呈簡單的鏈條形狀,則兩個大內存緩沖區即夠用,因為它們可以在整個網絡中來回互換。然而,對于形成復雜計算圖的任意網絡,這個NP 完備(NP-complete)資源分配問題需要一個良好的近似算法。
我們針對此問題設計了許多不同的近似算法,這些算法的表現取決于神經網絡和內存緩沖區的屬性,但都通過張量使用記錄。中間張量的張量使用記錄是一種輔助數據結構,其中包含有關張量的大小以及在給定的網絡執行計劃中首次最后一次使用時間的信息。借助這些記錄,內存管理器能夠在網絡執行的任何時刻計算中間張量的使用情況,并優化其運行時內存以最大限度減少占用空間。
共享內存緩沖區對象
在 TFLite GPU OpenGL 后端中,我們為這些中間張量采用 GL 紋理。這種方式有幾個有趣的限制:(a) 紋理一經創建便無法修改大小,以及 (b) 在給定時間只有一個著色器程序可以獨占訪問紋理對象。在這種共享內存緩沖區對象模式的目標是最小化對象池中創建的所有共享內存緩沖區對象的大小總和。這種優化與眾所周知的寄存器分配問題類似,但每個對象的大小可變,因此優化起來要復雜得多。
根據前面提到的張量使用記錄,我們設計了 5 種不同的算法,如表 1 所示。除了“最小成本流”以外,它們都是貪心算法,每個算法使用不同的啟發式算法,但仍會達到或非常接近理論下限。根據網絡拓撲,某些算法的性能要優于其他算法,但總體來說,GREEDY_BY_SIZE_IMPROVED 和 GREEDY_BY_BREADTH 產生的對象分配占用內存最小。
理論下限
https://arxiv.org/abs/2001.03288
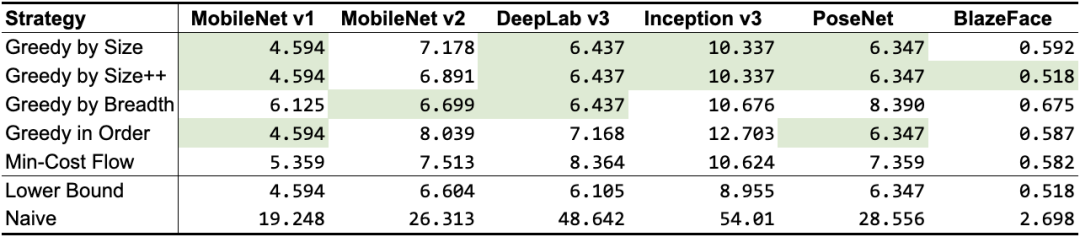
表 1. “共享對象”策略的內存占用量(以 MB 為單位;最佳結果以綠色突出顯示)。前 5 行是我們的策略,后 2 行用作基準(“下限”表示最佳數的近似值,該值可能無法實現,而“樸素”表示為每個中間張量分配專屬內存緩沖區的情況下可能的最差數)
回到我們的第一個示例,GREEDY_BY_BREADTH 在 MobileNet v2 上表現最佳,它利用了每個算子的寬度,即算子配置文件中所有張量的總和。圖 2,尤其是與圖 1 相比,突出了使用智能內存管理器的優勢。
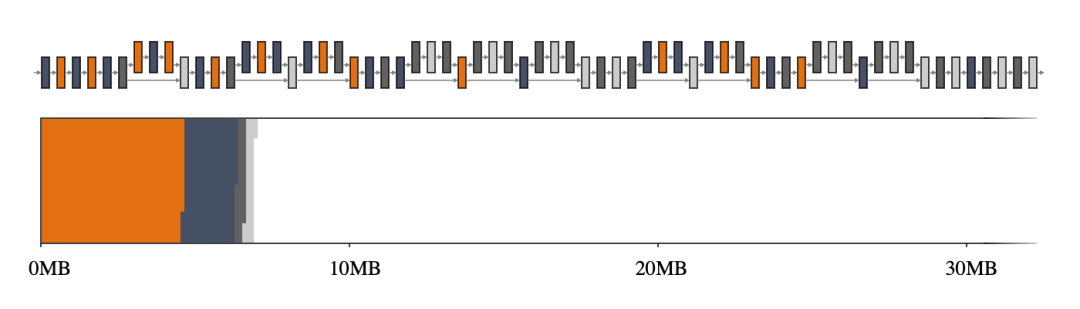
圖 2. MobileNet v2 的中間張量(上圖)及其大小到二維內存空間的映射(下圖)。如果中間張量共享內存緩沖區(用 4 種不同的顏色表示),它們僅占用大約 7MB 的運行時內存
內存偏移量計算
對于在 CPU 上運行的 TFLite,適用于 GL 紋理的內存緩沖區屬性不適用。因此,更常見的做法是提前分配一個大內存空間,并通過給定偏移量訪問內存在所有不干擾其他讀取和寫入操作的讀取器和寫入器之間共享。這種內存偏移量計算法的目的是最大程度地減小內存空間的大小。
我們針對此優化問題設計了 3 種不同的算法,同時還分析了先前的研究工作(Sekiyama 等人于 2018 年提出的 Strip Packing)。與“共享對象”法類似,根據網絡的不同,一些算法的性能優于其他算法,如表 2 所示。這項研究的一個收獲是:“偏移量計算”法通常比“共享對象”法占用的空間更小。因此,如果適用,應該選擇前者而不是后者。
Strip Packing
https://arxiv.org/abs/1804.10001

表 2. “偏移量計算”策略的內存占用量(以 MB 為單位;最佳結果以綠色突出顯示)。前 3 行是我們的策略,接下來 1 行是先前的研究,后 2 行用作基準(“下限”表示最佳數的近似值,該值可能無法實現,而“樸素”表示為每個中間張量分配專屬內存緩沖區的情況下可能的最差數)
這些針對 CPU 和 GPU 的內存優化默認已隨過去幾個穩定的 TFLite 版本一起提供,并已證明在支持更苛刻的最新模型(如 MobileBERT)方面很有優勢。直接查看 GPU 實現和 CPU 實現,可以找到更多關于實現的細節。
MobileBERT
https://tfhub.dev/tensorflow/lite-model/mobilebert/1/default/1
GPU 實現
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/delegates/gpu/common/memory_management
CPU 實現
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/simple_memory_arena.h
致謝
感謝 Matthias Grundmann、Jared Duke 和 Sarah Sirajuddin,特別感謝 Andrei Kulik 參加了最開始的頭腦風暴,同時感謝 Terry Heo 完成 TFLite 的最終實現。
責任編輯:xj
原文標題:優化 TensorFlow Lite 推理運行環境內存占用
文章出處:【微信公眾號:TensorFlow】歡迎添加關注!文章轉載請注明出處。
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107747 -
張量
+關注
關注
0文章
7瀏覽量
2692 -
tensorflow
+關注
關注
13文章
334瀏覽量
62173 -
TensorFlow Lite
+關注
關注
0文章
26瀏覽量
828
原文標題:優化 TensorFlow Lite 推理運行環境內存占用
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于芯科科技xG24開發套件實現語音控制燈光的簡易步驟
Redis內存管理、持久化策略與慢查詢排查分析
IMX95 - NPU 不工作的原因?怎么解決?
借助谷歌LiteRT構建下一代高性能端側AI

容易造成單片機內存溢出的幾個陷阱介紹
如何在TensorFlow Lite Micro中添加自定義操作符(1)
【上海晶珩睿莓1開發板試用體驗】將TensorFlow-Lite物體歸類(classify)的輸出圖片移植到LVGL9.3界面中
【上海晶珩睿莓1開發板試用體驗】TensorFlow-Lite物體歸類(classify)
了解SOLIDWORKS202仿真方面的改進
瀾起科技憑借在內存接口和高速互連芯片領域的突破性創新榮膺《財富》中國科技50強
如何進行tflite模型量化
無法將Tensorflow Lite模型轉換為OpenVINO?格式怎么處理?
通過什么方法能獲得關于Ethercat方面的設計方案和設計資料
FlexBuild構建Debian 12,在“tflite_ethosu_delegate”上構建失敗了怎么解決?
用樹莓派搞深度學習?TensorFlow啟動!




 工商網監
工商網監
評論