") 基于FPGA的神經(jīng)網(wǎng)絡(luò)加速硬件和網(wǎng)絡(luò)設(shè)計的協(xié)同
基于FPGA的神經(jīng)網(wǎng)絡(luò)加速硬件和網(wǎng)絡(luò)設(shè)計的協(xié)同

引言
很久沒有看基于FPGA的神經(jīng)網(wǎng)絡(luò)實現(xiàn)的文章了,因為神經(jīng)網(wǎng)絡(luò)加速設(shè)計做的久了就會發(fā)現(xiàn),其實架構(gòu)都差不多。大家都主要集中于去提高以下幾種性能:FPGA算力,網(wǎng)絡(luò)精度,網(wǎng)絡(luò)模型大小。FPGA架構(gòu)也差不多這幾個模塊:片上緩存,卷積加速模塊,pool模塊,load,save,指令控制模塊。硬件架構(gòu)上并不是太難,難的反而是軟件編譯這塊。因為其要去適應(yīng)不同的網(wǎng)絡(luò)模型,還要能兼容FPGA硬件的變化,同時要為客戶提供一個容易操作的接口。這些在目前情景下還比較困難。首先是FPGA硬件的變化太多,各個模塊可配參數(shù)的變化(比如卷積模塊并行數(shù)的變化),另外一個是網(wǎng)絡(luò)模型多種多樣以及開源的網(wǎng)絡(luò)模型平臺也很多(tensorflow,pytorch等)。網(wǎng)絡(luò)壓縮也有很多種算法,這些算法基本上都會導(dǎo)致網(wǎng)絡(luò)模型精度的降低。一般基于FPGA的網(wǎng)絡(luò)加速設(shè)計都會強調(diào)模型被壓縮了多少以及FPGA上可以跑得多快,卻很少集中于去改善精度。
這篇文獻從概念上提出了硬件和網(wǎng)絡(luò)的協(xié)同設(shè)計,是很好的一個思路。因為之前神經(jīng)網(wǎng)絡(luò)加速硬件設(shè)計和網(wǎng)絡(luò)壓縮是分開的,只是在網(wǎng)絡(luò)壓縮的時候盡可能考慮到硬件的特點,讓網(wǎng)絡(luò)模型更加適合硬件架構(gòu)。這篇論文其實也是在做這樣類似的工作,我并不認為它真正的實現(xiàn)了硬件和網(wǎng)絡(luò)設(shè)計的協(xié)同(雖然其標榜自己如此)。但是它確實給我們提供了一個新的研究思路:如何從一開始就設(shè)計一個能夠適用于硬件的網(wǎng)絡(luò)。好的,廢話不多說,來看論文。
1. 來自作者的批判
發(fā)表論文,總是要先去總結(jié)以往論文的優(yōu)缺點,然后指出其中不足,凸顯自己的優(yōu)勢。這篇文章也花費了很大篇幅來批判了過去研究的不足。總結(jié)起來有以下幾點:
1) 過去的研究都是用一些老的網(wǎng)絡(luò),比如VGG,resnet,alexnet等,這些網(wǎng)絡(luò)已經(jīng)落伍了,市場上已經(jīng)不怎么用了;
2) 過去用的數(shù)據(jù)集也小,比如CIFAR10這類,包含的圖片種類和數(shù)量都太少,不太適合商業(yè)應(yīng)用;
3) 壓縮老的網(wǎng)絡(luò)的技術(shù)手段不再適用于最新的網(wǎng)絡(luò),比如像squeezeNet網(wǎng)絡(luò),它就比alexnet網(wǎng)絡(luò)小50倍,但是能達到和alexnet一樣的精度;
4) 以往的類似resnet的網(wǎng)絡(luò),有skip連接的,并不適合在FPGA上部署,因為增加了數(shù)據(jù)遷移;
5) 以往網(wǎng)絡(luò)的卷積核較大,如3x3,5x5等,也不適合硬件加速;
6) 以前網(wǎng)絡(luò)壓縮集中于老的那些網(wǎng)絡(luò),這些網(wǎng)絡(luò)本身就有很大的冗余,所以壓縮起來很容易,而最新的網(wǎng)絡(luò)比如ShuffleNet等壓縮起來就沒有那么容易了,但是這樣的報道很少;
總之,意思就是之前的文章都撿軟柿子捏,而且比較落后了。那么我們來看看在這樣狂妄口氣之下的成果如何。
2. shuffleNetV2到DiracDeltNet
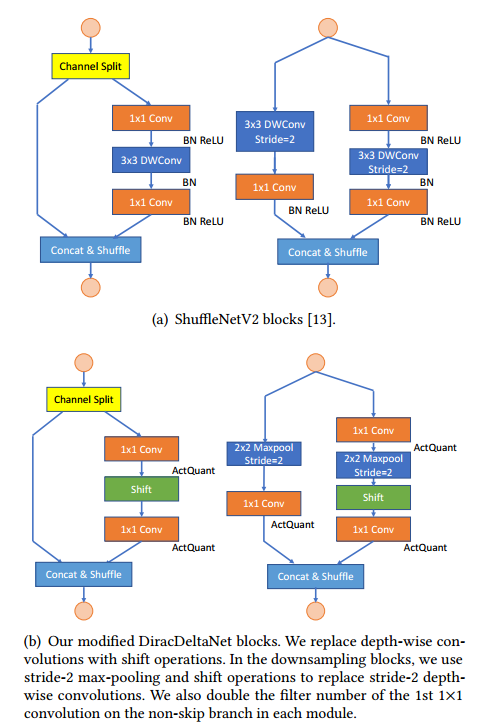
shuffleNetV2是新發(fā)展出來的一個神經(jīng)網(wǎng)絡(luò),它的網(wǎng)絡(luò)模型中參數(shù)更小(比VGG16小60倍),但是精度只比VGG16低2%。shuffleNet不再像resnet將skip連接的數(shù)據(jù)求和,而是skip連接的數(shù)據(jù)進行concat,這樣的操作降低了加法操作。Skip連接可以擴展網(wǎng)絡(luò)的深度和提高深層網(wǎng)絡(luò)精度。但是加法skip不利于FPGA實現(xiàn),一個是加法消耗資源和時間,另外一個是skip數(shù)據(jù)增加了遷移時間。Concat連接也和加法skip有相同的功能,增加網(wǎng)絡(luò)深度和精度。
作者對shuffleNetV2網(wǎng)絡(luò)結(jié)構(gòu)進行了更有利于FPGA部署的微調(diào)。有以下三個方面:
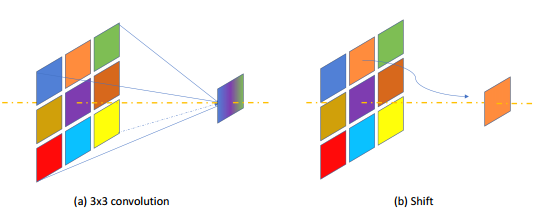
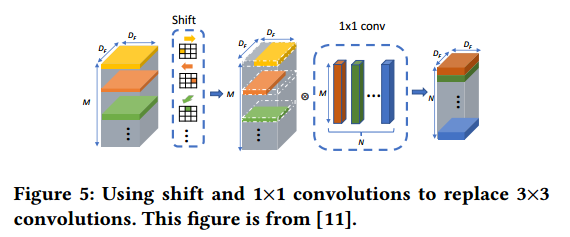
1) 將所有3x3卷積(包括3x3depth-wise卷積)都替換為shift和1x1卷積。這樣替換是能夠降低feature map數(shù)據(jù)的遷移,比如3x3的卷積每個圖像數(shù)據(jù)要使用3次,而1x1只需要搬移一次,降低了邏輯復(fù)雜性,也提高了運算速度。Shift操作是將某個范圍的pixel移動到中間作為結(jié)果,這樣的操作減少了乘法運算次數(shù)。這種替換會導(dǎo)致精度降低,但是可以減少FPGA運算次數(shù)。
2) 將3x3的maxpooling操作降低為2x2的。
3) 調(diào)整了channel的順序來適應(yīng)FPGA。
3. 量化
為了進一步降低網(wǎng)絡(luò)參數(shù)量,作者采用了DoReFa-Net網(wǎng)絡(luò)的量化方式,對全精度權(quán)重進行了量化。同時作者還對activation進行了量化。量化結(jié)果如下:
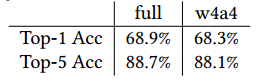
精度損失很小。
文獻中使用了很多對網(wǎng)絡(luò)修改的微調(diào)技術(shù),細節(jié)很多,可以看出對這樣一個已經(jīng)很少參數(shù)的網(wǎng)絡(luò)來說,要進一步壓縮確實要花費很大功夫。這可能不太具有普遍性。這些微調(diào)應(yīng)該會花費很多時間和精力。
4. 硬件架構(gòu)
硬件主要實現(xiàn)的操作很少,只有一下幾種:
1)1x1卷積
2)2x2的ma-pooling
3)shift
4)shuffle和concat
所以硬件架構(gòu)上也變得很簡潔,文章中說兩個人用HLS只做了一個月。
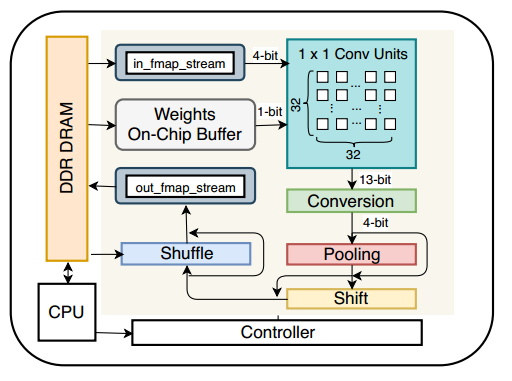
使用資源很少。

看以下和其他人的結(jié)果對比:
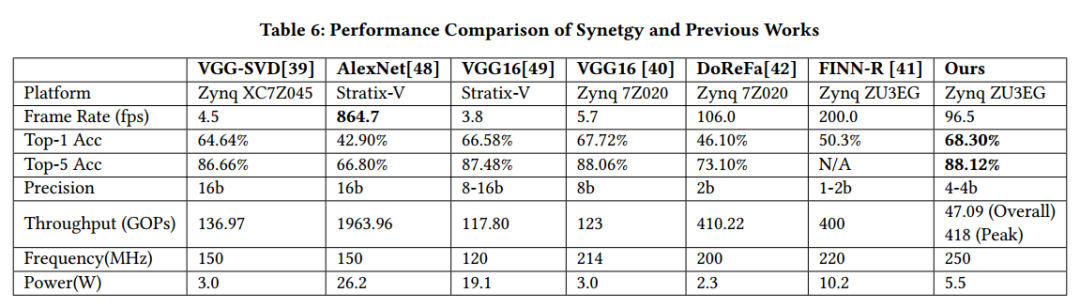
結(jié)論
這篇論文在shuffleNet網(wǎng)絡(luò)的基礎(chǔ)上,基于FPGA的特點進行了網(wǎng)絡(luò)修改。包括網(wǎng)絡(luò)結(jié)構(gòu)和量化,最終的精度都高于以往的幾個網(wǎng)絡(luò)。結(jié)果還是不錯的,只是這樣手動微調(diào)網(wǎng)絡(luò)并不是很具有普遍性,而且涉及到很多微調(diào)技術(shù),也不一定適合每個網(wǎng)絡(luò)。但是作者確實提供了一個思路:如何去設(shè)計一個能夠用于FPGA的網(wǎng)絡(luò),而且還可以保證很好的精度。
文獻
1. Yifan Yang, Q.H., Bichen Wu, Tianjun Zhang, Liang Ma, Giulio Gambardella, Michaela Blott, Luciano Lavagno, Kees Vissers, John Wawrzynek, Kurt Keutzer, Synetgy Algorithm-hardware Co-design for ConvNet Accelerators on Embedded FPGAs. arXiv preprint, 2019.
-
FPGA
+關(guān)注
關(guān)注
1660文章
22412瀏覽量
636364 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107795
發(fā)布評論請先 登錄
從網(wǎng)絡(luò)接口到 DMA,一套面向工程師的 FPGA 網(wǎng)絡(luò)開發(fā)框架

神經(jīng)網(wǎng)絡(luò)的初步認識

CNN卷積神經(jīng)網(wǎng)絡(luò)設(shè)計原理及在MCU200T上仿真測試
NMSIS神經(jīng)網(wǎng)絡(luò)庫使用介紹
在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗
CICC2033神經(jīng)網(wǎng)絡(luò)部署相關(guān)操作
液態(tài)神經(jīng)網(wǎng)絡(luò)(LNN):時間連續(xù)性與動態(tài)適應(yīng)性的神經(jīng)網(wǎng)絡(luò)
神經(jīng)網(wǎng)絡(luò)的并行計算與加速技術(shù)
基于神經(jīng)網(wǎng)絡(luò)的數(shù)字預(yù)失真模型解決方案
無刷電機小波神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)子位置檢測方法的研究
神經(jīng)網(wǎng)絡(luò)專家系統(tǒng)在電機故障診斷中的應(yīng)用
神經(jīng)網(wǎng)絡(luò)RAS在異步電機轉(zhuǎn)速估計中的仿真研究
基于FPGA搭建神經(jīng)網(wǎng)絡(luò)的步驟解析

MAX78000采用超低功耗卷積神經(jīng)網(wǎng)絡(luò)加速度計的人工智能微控制器技術(shù)手冊



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論