 PCIe鏈路端到端的數據傳遞 PCLe總線的層次結構
PCIe鏈路端到端的數據傳遞 PCLe總線的層次結構

PCIe總線概述
隨著現代處理器技術的發展,在互連領域中,使用高速差分總線替代并行總線是大勢所趨。與單端并行信號相比,高速差分信號可以使用更高的時鐘頻率,從而使用更少的信號線,完成之前需要許多單端并行數據信號才能達到的總線帶寬。
PCI總線使用并行總線結構,在同一條總線上的所有外部設備共享總線帶寬,而PCIe總線使用了高速差分總線,并采用端到端的連接方式,因此在每一條PCIe鏈路中只能連接兩個設備。這使得PCIe與PCI總線采用的拓撲結構有所不同。PCIe總線除了在連接方式上與PCI總線不同之外,還使用了一些在網絡通信中使用的技術,如支持多種數據路由方式,基于多通路的數據傳遞方式,和基于報文的數據傳送方式,并充分考慮了在數據傳送中出現服務質量QoS (Quality of Service)問題。
PCIe總線的基礎知識
與PCI總線不同,PCIe總線使用端到端的連接方式,在一條PCIe鏈路的兩端只能各連接一個設備,這兩個設備互為是數據發送端和數據接收端。PCIe總線除了總線鏈路外,還具有多個層次,發送端發送數據時將通過這些層次,而接收端接收數據時也使用這些層次。PCIe總線使用的層次結構與網絡協議棧較為類似。
1.1 端到端的數據傳遞
PCIe鏈路使用“端到端的數據傳送方式”,發送端和接收端中都含有TX(發送邏輯)和RX(接收邏輯),其結構如圖41所示。
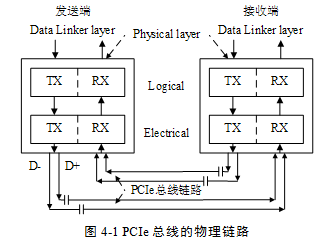
由上圖所示,在PCIe總線的物理鏈路的一個數據通路(Lane)中,由兩組差分信號,共4根信號線組成。其中發送端的TX部件與接收端的RX部件使用一組差分信號連接,該鏈路也被稱為發送端的發送鏈路,也是接收端的接收鏈路;而發送端的RX部件與接收端的TX部件使用另一組差分信號連接,該鏈路也被稱為發送端的接收鏈路,也是接收端的發送鏈路。一個PCIe鏈路可以由多個Lane組成。
高速差分信號電氣規范要求其發送端串接一個電容,以進行AC耦合。該電容也被稱為AC耦合電容。PCIe鏈路使用差分信號進行數據傳送,一個差分信號由D+和D-兩根信號組成,信號接收端通過比較這兩個信號的差值,判斷發送端發送的是邏輯“1”還是邏輯“0”。
與單端信號相比,差分信號抗干擾的能力更強,因為差分信號在布線時要求“等長”、“等寬”、“貼近”,而且在同層。因此外部干擾噪聲將被“同值”而且“同時”加載到D+和D-兩根信號上,其差值在理想情況下為0,對信號的邏輯值產生的影響較小。因此差分信號可以使用更高的總線頻率。
此外使用差分信號能有效抑制電磁干擾EMI(Electro Magnetic Interference)。由于差分信號D+與D-距離很近而且信號幅值相等、極性相反。這兩根線與地線間耦合電磁場的幅值相等,將相互抵消,因此差分信號對外界的電磁干擾較小。當然差分信號的缺點也是顯而易見的,一是差分信號使用兩根信號傳送一位數據;二是差分信號的布線相對嚴格一些。
PCIe鏈路可以由多條Lane組成,目前PCIe鏈路可以支持1、2、4、8、12、16和32個Lane,即×1、×2、×4、×8、×12、×16和×32寬度的PCIe鏈路。每一個Lane上使用的總線頻率與PCIe總線使用的版本相關。
第1個PCIe總線規范為V1.0,之后依次為V1.0a,V1.1,V2.0和V2.1。目前PCIe總線的最新規范為V2.1,而V3.0正在開發過程中,預計在2010年發布。不同的PCIe總線規范所定義的總線頻率和鏈路編碼方式并不相同,如表41所示。
表41 PCIe總線規范與總線頻率和編碼的關系
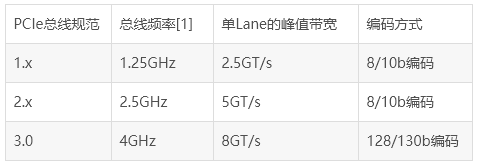
如上表所示,不同的PCIe總線規范使用的總線頻率并不相同,其使用的數據編碼方式也不相同。PCIe總線V1.x和V2.0規范在物理層中使用8/10b編碼,即在PCIe鏈路上的10 bit中含有8 bit的有效數據;而V3.0規范使用128/130b編碼方式,即在PCIe鏈路上的130 bit中含有128 bit的有效數據。
由上表所示,V3.0規范使用的總線頻率雖然只有4GHz,但是其有效帶寬是V2.x的兩倍。下文將以V2.x規范為例,說明不同寬度PCIe鏈路所能提供的峰值帶寬,如表42所示。
表42 PCIe總線的峰值帶寬

由上表所示,×32的PCIe鏈路可以提供160GT/s的鏈路帶寬,遠高于PCI/PCI-X總線所能提供的峰值帶寬。而即將推出的PCIe V3.0規范使用4GHz的總線頻率,將進一步提高PCIe鏈路的峰值帶寬。
在PCIe總線中,使用GT(Gigatransfer)計算PCIe鏈路的峰值帶寬。GT是在PCIe鏈路上傳遞的峰值帶寬,其計算公式為總線頻率×數據位寬×2。
在PCIe總線中,影響有效帶寬的因素有很多,因而其有效帶寬較難計算。盡管如此,PCIe總線提供的有效帶寬還是遠高于PCI總線。PCIe總線也有其弱點,其中最突出的問題是傳送延時。
PCIe鏈路使用串行方式進行數據傳送,然而在芯片內部,數據總線仍然是并行的,因此PCIe鏈路接口需要進行串并轉換,這種串并轉換將產生較大的延時。除此之外PCIe總線的數據報文需要經過事務層、數據鏈路層和物理層,這些數據報文在穿越這些層次時,也將帶來延時。
在基于PCIe總線的設備中,×1的PCIe鏈路最為常見,而×12的PCIe鏈路極少出現,×4和×8的PCIe設備也不多見。Intel通常在ICH中集成了多個×1的PCIe鏈路用來連接低速外設,而在MCH中集成了一個×16的PCIe鏈路用于連接顯卡控制器。而PowerPC處理器通常能夠支持×8、×4、×2和×1的PCIe鏈路。
PCIe總線物理鏈路間的數據傳送使用基于時鐘的同步傳送機制,但是在物理鏈路上并沒有時鐘線,PCIe總線的接收端含有時鐘恢復模塊CDR(Clock Data Recovery),CDR將從接收報文中提取接收時鐘,從而進行同步數據傳遞。
值得注意的是,在一個PCIe設備中除了需要從報文中提取時鐘外,還使用了REFCLK+和REFCLK-信號對作為本地參考時鐘,這個信號對的描述見下文。
1.2 PCIe總線使用的信號
PCIe設備使用兩種電源信號供電,分別是Vcc與Vaux,其額定電壓為3.3V。其中Vcc為主電源,PCIe設備使用的主要邏輯模塊均使用Vcc供電,而一些與電源管理相關的邏輯使用Vaux供電。在PCIe設備中,一些特殊的寄存器通常使用Vaux供電,如Sticky Register,此時即使PCIe設備的Vcc被移除,這些與電源管理相關的邏輯狀態和這些特殊寄存器的內容也不會發生改變。
在PCIe總線中,使用Vaux的主要原因是為了降低功耗和縮短系統恢復時間。因為Vaux在多數情況下并不會被移除,因此當PCIe設備的Vcc恢復后,該設備不用重新恢復使用Vaux供電的邏輯,從而設備可以很快地恢復到正常工作狀狀態。
PCIe鏈路的最大寬度為×32,但是在實際應用中,×32的鏈路寬度極少使用。在一個處理器系統中,一般提供×16的PCIe插槽,并使用PETp0~15、PETn0~15和PERp0~15、PERn0~15共64根信號線組成32對差分信號,其中16對PETxx信號用于發送鏈路,另外16對PERxx信號用于接收鏈路。除此之外PCIe總線還使用了下列輔助信號。
1 PERST#信號
該信號為全局復位信號,由處理器系統提供,處理器系統需要為PCIe插槽和PCIe設備提供該復位信號。PCIe設備使用該信號復位內部邏輯。當該信號有效時,PCIe設備將進行復位操作。PCIe總線定義了多種復位方式,其中Cold Reset和Warm Reset這兩種復位方式的實現與該信號有關,詳見第1.5節。
2 REFCLK+和REFCLK-信號
在一個處理器系統中,可能含有許多PCIe設備,這些設備可以作為Add-In卡與PCIe插槽連接,也可以作為內置模塊,與處理器系統提供的PCIe鏈路直接相連,而不需要經過PCIe插槽。PCIe設備與PCIe插槽都具有REFCLK+和REFCLK-信號,其中PCIe插槽使用這組信號與處理器系統同步。
在一個處理器系統中,通常采用專用邏輯向PCIe插槽提供REFCLK+和REFCLK-信號,如圖42所示。其中100Mhz的時鐘源由晶振提供,并經過一個“一推多”的差分時鐘驅動器生成多個同相位的時鐘源,與PCIe插槽一一對應連接。
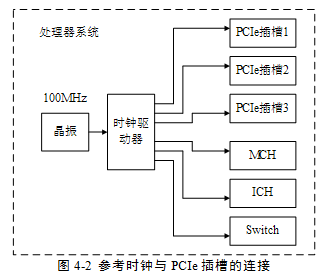
PCIe插槽需要使用參考時鐘,其頻率范圍為100MHz±300ppm。處理器系統需要為每一個PCIe插槽、MCH、ICH和Switch提供參考時鐘。而且要求在一個處理器系統中,時鐘驅動器產生的參考時鐘信號到每一個PCIe插槽(MCH、ICH和Swith)的距離差在15英寸之內。通常信號的傳播速度接近光速,約為6英寸/ns,由此可見,不同PCIe插槽間REFCLK+和REFCLK-信號的傳送延時差約為2.5ns。
當PCIe設備作為Add-In卡連接在PCIe插槽時,可以直接使用PCIe插槽提供的REFCLK+和REFCLK-信號,也可以使用獨立的參考時鐘,只要這個參考時鐘在100MHz±300ppm范圍內即可。內置的PCIe設備與Add-In卡在處理REFCLK+和REFCLK-信號時使用的方法類似,但是PCIe設備可以使用獨立的參考時鐘,而不使用REFCLK+和REFCLK-信號。
在PCIe設備配置空間的Link Control Register中,含有一個“Common Clock Configuration”位。當該位為1時,表示該設備與PCIe鏈路的對端設備使用“同相位”的參考時鐘;如果為0,表示該設備與PCIe鏈路的對端設備使用的參考時鐘是異步的。
在PCIe設備中,“Common Clock Configuration”位的缺省值為0,此時PCIe設備使用的參考時鐘與對端設備沒有任何聯系,PCIe鏈路兩端設備使用的參考時鐘可以異步設置。這個異步時鐘設置方法對于使用PCIe鏈路進行遠程連接時尤為重要。
在一個處理器系統中,如果使用PCIe鏈路進行機箱到機箱間的互連,因為參考時鐘可以異步設置,機箱到機箱之間進行數據傳送時僅需要差分信號線即可,而不需要參考時鐘,從而極大降低了連接難度。
3 WAKE#信號
當PCIe設備進入休眠狀態,主電源已經停止供電時,PCIe設備使用該信號向處理器系統提交喚醒請求,使處理器系統重新為該PCIe設備提供主電源Vcc。在PCIe總線中,WAKE#信號是可選的,因此使用WAKE#信號喚醒PCIe設備的機制也是可選的。值得注意的是產生該信號的硬件邏輯必須使用輔助電源Vaux供電。
WAKE#是一個Open Drain信號,一個處理器的所有PCIe設備可以將WAKE#信號進行線與后,統一發送給處理器系統的電源控制器。當某個PCIe設備需要被喚醒時,該設備首先置WAKE#信號有效,然后在經過一段延時之后,處理器系統開始為該設備提供主電源Vcc,并使用PERST#信號對該設備進行復位操作。此時WAKE#信號需要始終保持為低,當主電源Vcc上電完成之后,PERST#信號也將置為無效并結束復位,WAKE#信號也將隨之置為無效,結束整個喚醒過程。
PCIe設備除了可以使用WAKE#信號實現喚醒功能外,還可以使用Beacon信號實現喚醒功能。與WAKE#信號實現喚醒功能不同,Beacon使用In-band信號,即差分信號D+和D-實現喚醒功能。Beacon信號DC平衡,由一組通過D+和D-信號生成的脈沖信號組成。這些脈沖信號寬度的最小值為2ns,最大值為16us。當PCIe設備準備退出L2狀態(該狀態為PCIe設備使用的一種低功耗狀態)時,可以使用Beacon信號,提交喚醒請求。
4 SMCLK和SMDAT信號
SMCLK和SMDAT信號與x86處理器的SMBus(System Mangement Bus)相關。SMBus于1995年由Intel提出,SMBus由SMCLK和SMDAT信號組成。SMBus源于I2C總線,但是與I2C總線存在一些差異。
SMBus的最高總線頻率為100KHz,而I2C總線可以支持400KHz和2MHz的總線頻率。此外SMBus上的從設備具有超時功能,當從設備發現主設備發出的時鐘信號保持低電平超過35ms時,將引發從設備的超時復位。在正常情況下,SMBus的主設備使用的總線頻率最低為10KHz,以避免從設備在正常使用過程中出現超時。
在SMbus中,如果主設備需要復位從設備時,可以使用這種超時機制。而I2C總線只能使用硬件信號才能實現這種復位操作,在I2C總線中,如果從設備出現錯誤時,單純通過主設備是無法復位從設備的。
SMBus還支持Alert Response機制。當從設備產生一個中斷時,并不會立即清除該中斷,直到主設備向0b0001100地址發出命令。
上文所述的SMBus和I2C總線的區別還是局限于物理層和鏈路層上,實際上SMBus還含有網絡層。SMBus還在網絡層上定義了11種總線協議,用來實現報文傳遞。
SMBus在x86處理器系統中得到了大規模普及,其主要作用是管理處理器系統的外部設備,并收集外設的運行信息,特別是一些與智能電源管理相關的信息。PCI和PCIe插槽也為SMBus預留了接口,以便于PCI/PCIe設備與處理器系統進行交互。
在Linux系統中,SMBus得到了廣泛的應用,ACPI也為SMBus定義了一系列命令,用于智能電池、電池充電器與處理器系統之間的通信。在Windows操作系統中,有關外部設備的描述信息,也是通過SMBus獲得的。
5 JTAG信號
JTAG(Joint Test Action Group)是一種國際標準測試協議,與IEEE 1149.1兼容,主要用于芯片內部測試。目前絕大多數器件都支持JTAG測試標準。JTAG信號由TRST#、TCK、TDI、TDO和TMS信號組成。其中TRST#為復位信號;TCK為時鐘信號;TDI和TDO分別與數據輸入和數據輸出對應;而TMS信號為模式選擇。
JTAG允許多個器件通過JTAG接口串聯在一起,并形成一個JTAG鏈。目前FPGA和EPLD可以借用JTAG接口實現在線編程ISP(In-System Programming)功能。處理器也可以使用JTAG接口進行系統級調試工作,如設置斷點、讀取內部寄存器和存儲器等一系列操作。除此之外JTAG接口也可用作“逆向工程”,分析一個產品的實現細節,因此在正式產品中,一般不保留JTAG接口。
6 PRSNT1#和PRSNT2#信號
PRSNT1#和PRSNT2#信號與PCIe設備的熱插拔相關。在基于PCIe總線的Add-in卡中,PRSNT1#和PRSNT2#信號直接相連,而在處理器主板中,PRSNT1#信號接地,而PRSNT2#信號通過上拉電阻接為高。PCIe設備的熱插拔結構如圖43所示。
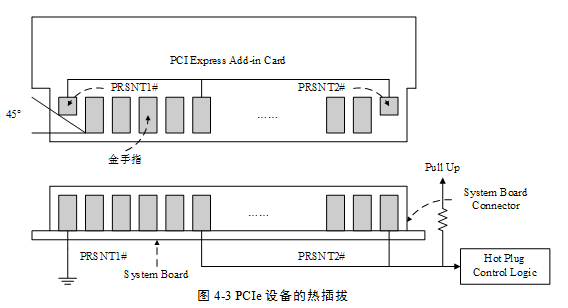
如上圖所示,當Add-In卡沒有插入時,處理器主板的PRSNT2#信號由上拉電阻接為高,而當Add-In卡插入時主板的PRSNT2#信號將與PRSNT1#信號通過Add-In卡連通,此時PRSNT2#信號為低。處理器主板的熱插拔控制邏輯將捕獲這個“低電平”,得知Add-In卡已經插入,從而觸發系統軟件進行相應地處理。
Add-In卡拔出的工作機制與插入類似。當Add-in卡連接在處理器主板時,處理器主板的PRSNT2#信號為低,當Add-In卡拔出后,處理器主板的PRSNT2#信號為高。處理器主板的熱插拔控制邏輯將捕獲這個“高電平”,得知Add-In卡已經被拔出,從而觸發系統軟件進行相應地處理。
不同的處理器系統處理PCIe設備熱拔插的過程并不相同,在一個實際的處理器系統中,熱拔插設備的實現也遠比圖43中的示例復雜得多。值得注意的是,在實現熱拔插功能時,Add-in Card需要使用“長短針”結構。
如圖43所示,PRSNT1#和PRSNT2#信號使用的金手指長度是其他信號的一半。因此當PCIe設備插入插槽時,PRSNT1#和PRSNT2#信號在其他金手指與PCIe插槽完全接觸,并經過一段延時后,才能與插槽完全接觸;當PCIe設備從PCIe插槽中拔出時,這兩個信號首先與PCIe插槽斷連,再經過一段延時后,其他信號才能與插槽斷連。系統軟件可以使用這段延時,進行一些熱拔插處理。
1.3 PCLe總線的層次結構
PCIe總線采用了串行連接方式,并使用數據包(Packet)進行數據傳輸,采用這種結構有效去除了在PCI總線中存在的一些邊帶信號,如INTx和PME#等信號。在PCIe總線中,數據報文在接收和發送過程中,需要通過多個層次,包括事務層、數據鏈路層和物理層。PCIe總線的層次結構如圖44所示。
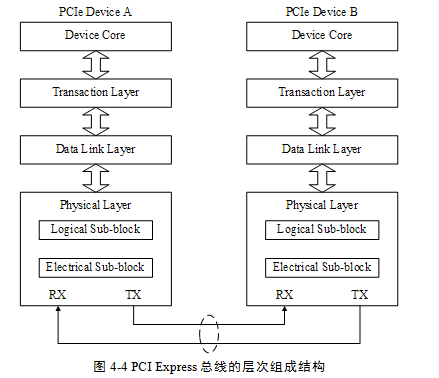
PCIe總線的層次組成結構與網絡中的層次結構有類似之處,但是PCIe總線的各個層次都是使用硬件邏輯實現的。在PCIe體系結構中,數據報文首先在設備的核心層(Device Core)中產生,然后再經過該設備的事務層(Transaction Layer)、數據鏈路層(Data Link Layer)和物理層(Physical Layer),最終發送出去。而接收端的數據也需要通過物理層、數據鏈路和事務層,并最終到達Device Core。
1 事務層
事務層定義了PCIe總線使用總線事務,其中多數總線事務與PCI總線兼容。這些總線事務可以通過Switch等設備傳送到其他PCIe設備或者RC。RC也可以使用這些總線事務訪問PCIe設備。
事務層接收來自PCIe設備核心層的數據,并將其封裝為TLP(Transaction Layer Packet)后,發向數據鏈路層。此外事務層還可以從數據鏈路層中接收數據報文,然后轉發至PCIe設備的核心層。
事務層的一個重要工作是處理PCIe總線的“序”。在PCIe總線中,“序”的概念非常重要,也較難理解。在PCIe總線中,事務層傳遞報文時可以亂序,這為PCIe設備的設計制造了不小的麻煩。事務層還使用流量控制機制保證PCIe鏈路的使用效率。有關事務層的詳細說明見第6章。
2 數據鏈路層
數據鏈路層保證來自發送端事務層的報文可以可靠、完整地發送到接收端的數據鏈路層。來自事務層的報文在通過數據鏈路層時,將被添加Sequence Number前綴和CRC后綴。數據鏈路層使用ACK/NAK協議保證報文的可靠傳遞。
PCIe總線的數據鏈路層還定義了多種DLLP(Data Link Layer Packet),DLLP產生于數據鏈路層,終止于數據鏈路層。值得注意的是,TLP與DLLP并不相同,DLLP并不是由TLP加上Sequence Number前綴和CRC后綴組成的。
3 物理層
物理層是PCIe總線的最底層,將PCIe設備連接在一起。PCIe總線的物理電氣特性決定了PCIe鏈路只能使用端到端的連接方式。PCIe總線的物理層為PCIe設備間的數據通信提供傳送介質,為數據傳送提供可靠的物理環境。
物理層是PCIe體系結構最重要,也是最難以實現的組成部分。PCIe總線的物理層定義了LTSSM(Link Training and Status State Machine)狀態機,PCIe鏈路使用該狀態機管理鏈路狀態,并進行鏈路訓練、鏈路恢復和電源管理。
PCIe總線的物理層還定義了一些專門的“序列”,有的書籍將物理層這些“序列”稱為PLP(Phsical Layer Packer),這些序列用于同步PCIe鏈路,并進行鏈路管理。值得注意的是PCIe設備發送PLP與發送TLP的過程有所不同。對于系統軟件而言,物理層幾乎不可見,但是系統程序員仍有必要較為深入地理解物理層的工作原理。
1.4 數據鏈路的擴展
PCIe鏈路使用端到端的數據傳送方式。在一條PCIe鏈路中,這兩個端口是完全對等的,分別連接發送與接收設備,而且一個PCIe鏈路的一端只能連接一個發送設備或者接收設備。因此PCIe鏈路必須使用Switch擴展PCIe鏈路后,才能連接多個設備。使用Switch進行鏈路擴展的實例如圖45所示。
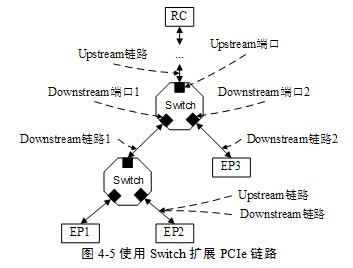
在PCIe總線中,Switch[2]是一個特殊的設備,該設備由1個上游端口和2~n個下游端口組成。PCIe總線規定,在一個Switch中可以與RC直接或者間接相連[3]的端口為上游端口,在PCIe總線中,RC的位置一般在上方,這也是上游端口這個稱呼的由來。在Switch中除了上游端口外,其他所有端口都被稱為下游端口。下游端口一般與EP相連,或者連接下一級Switch繼續擴展PCIe鏈路。其中與上游端口相連的PCIe鏈路被稱為上游鏈路,與下游端口相連的PCIe鏈路被稱為下游鏈路。
上游鏈路和下游鏈路是一個相對的概念。如上圖所示,Switch與EP2連接的PCIe鏈路,對于EP2而言是上游鏈路,而對Switch而言是下游鏈路。
在上圖所示的Switch中含有3個端口,其中一個是上游端口(Upstream Port),而其他兩個為下游端口(Downstream Port)。其中上游端口與RC或者其他Switch的下游端口相連,而下游端口與EP或者其他Switch的上游端口相連。
在Switch中,還有兩個與端口相關的概念,分別是Egress端口和Ingress端口。這兩個端口與通過Switch的數據流向有關。其中Egress端口指發送端口,即數據離開Switch使用的端口;Ingress端口指接收端口即數據進入Switch使用的端口。
Egress端口和Ingress端口與上下游端口沒有對應關系。在Switch中,上下游端口可以作為Egress端口,也可以作為Ingress端口。如圖45所示,RC對EP3的內部寄存器進行寫操作時,Switch的上游端口為Ingress端口,而下游端口為Egress端口;當EP3對主存儲器進行DMA寫操作時,該Switch的上游端口為Egress端口,而下游端口為Ingress端口。
PCIe總線還規定了一種特殊的Switch連接方式,即Crosslink連接模式。支持這種模式的Switch,其上游端口可以與其他Switch的上游端口連接,其下游端口可以與其他Switch的下游端口連接。
PCIe總線提供CrossLink連接模式的主要目的是為了解決不同處理器系統之間的互連,如圖46所示。使用CrossLink連接模式時,雖然從物理結構上看,一個Switch的上/下游端口與另一個Switch的上/下游端口直接相連,但是這個PCIe鏈路經過訓練后,仍然是一個端口作為上游端口,而另一個作為下游端口。
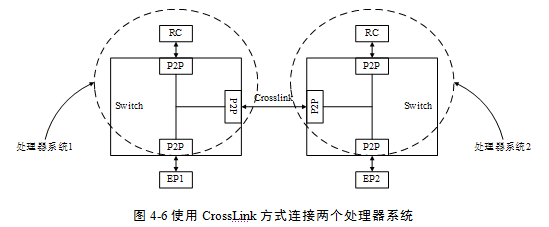
處理器系統1與處理器系統2間的數據交換可以通過Crosslink進行。當處理器系統1(2)訪問的PCI總線域的地址空間或者Requester ID不在處理器系統1(2)內時,這些數據將被Crosslink端口接收,并傳遞到對端處理器系統中。Crosslink對端接口的P2P橋將接收來自另一個處理器域的數據請求,并將其轉換為本處理器域的數據請求。
使用Crosslink方式連接兩個拓撲結構完全相同的處理器系統時,仍然有不足之處。假設圖46中的處理器系統1和2的RC使用的ID號都為0,而主存儲器都是從0x0000-0000開始編址時。當處理器1讀取EP2的某段PCI總線空間時,EP2將使用ID路由方式,將完成報文傳送給ID號為0的PCI設備,此時是處理器2的RC而不是處理器1的RC收到EP2的數據。因為處理器1和2的RC使用的ID號都為0,EP2不能區分這兩個RC。
由上所述,使用Crosslink方式并不能完全解決兩個處理器系統的互連問題,因此在有些Switch中支持非透明橋結構。這種結構與PCI總線非透明橋的實現機制類似,本章對此不做進一步說明。
使用非透明橋僅解決了兩個處理器間數據通路問題,但是不便于NUMA結構對外部設備的統一管理。PCIe總線對此問題的最終解決方法是使用MR-IOV技術,該技術要求Switch具有多個上游端口分別與不同的RC互連。目前PLX公司已經可以提供具有多個上游端口的Switch,但是尚未實現MR-IOV技術涉及的一些與虛擬化相關的技術。
即便MR-IOV技術可以合理解決多個處理器間的數據訪問和對PCIe設備的配置管理,使用PCIe總線進行兩個或者多個處理器系統間的數據傳遞仍然是一個不小問題。因為PCIe總線的傳送延時仍然是制約其在大規模處理器系統互連中應用的重要因素。
編輯:hfy
-
處理器
+關注
關注
68文章
20255瀏覽量
252296 -
PCIe
+關注
關注
16文章
1461瀏覽量
88422 -
PCIE總線
+關注
關注
0文章
58瀏覽量
14019 -
差分信號
+關注
關注
4文章
408瀏覽量
29010 -
數據鏈路
+關注
關注
0文章
28瀏覽量
9154
發布評論請先 登錄
深入剖析DS80PCI102:PCIe鏈路擴展的得力助手
端到端自動駕駛仿真新范式:aiSim如何解決智駕測試的"災難性挑戰"

如何訓練好自動駕駛端到端模型?

自動駕駛中“一段式端到端”和“二段式端到端”有什么區別?
端到端自動駕駛相較傳統自動駕駛到底有何提升?
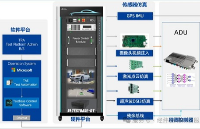
自主工具鏈助力端到端組合輔助駕駛算法驗證
NVMe高速傳輸之擺脫XDMA設計20: PCIe應答模塊設計
NVMe高速傳輸之擺脫XDMA設計14: PCIe應答模塊設計
PCIe協議分析儀在數據中心中有何作用?
為什么自動駕駛端到端大模型有黑盒特性?

端到端數據標注方案在自動駕駛領域的應用優勢
一文帶你厘清自動駕駛端到端架構差異



 工商網監
工商網監
評論