 如何使用FPGA實現FP16格式點積級聯運算
如何使用FPGA實現FP16格式點積級聯運算

通過使用Achronix Speedster7t FPGA中的機器學習加速器MLP72,開發人員可以輕松選擇浮點/定點格式和多種位寬,或快速應用塊浮點,并通過內部級聯可以達到理想性能。
神經網絡架構中的核心之一就是卷積層,卷積的最基本操作就是點積。向量乘法的結果是向量的每個元素的總和相乘在一起,通常稱之為點積。此向量乘法如下所示:

圖1 點積操作
該總和S由每個矢量元素的總和相乘而成,因此S=a1b1+a2b2+a3b3+…
本文講述的是使用FP16格式的點積運算實例,展示了MLP72支持的數字類型和乘數的范圍。
此設計實現了同時處理8對FP16輸入的點積。該設計包含四個MLP72,使用MLP內部的級聯路徑連接。每個MLP72將兩個并行乘法的結果相加(即aibi+ai+1bi+1),每個乘法都是i_a輸入乘以i_b輸入(均為FP16格式)的結果。來自每個MLP72的總和沿著MLP72的列級聯到上面的下一個MLP72塊。在最后一個MLP72中,在每個周期上,計算八個并行FP16乘法的總和。
最終結果是多個輸入周期內的累加總和,其中累加由i_first和i_last輸入控制。 i_first輸入信號指示累加和歸零的第一組輸入。 i_last信號指示要累加和加到累加的最后一組輸入。最終的i_last值可在之后的六個周期使用,并使用i_last o_valid進行限定。兩次運算之間可以無空拍。

那么,以上運算功能如何對應到MLP內部呢?其后的細節已分為MLP72中的多個功能階段進行說明。
● 進位鏈
首先請看下圖,MLP之間的進位鏈結構,這是MLP內部的專用走線,可以保證級聯的高效執行。
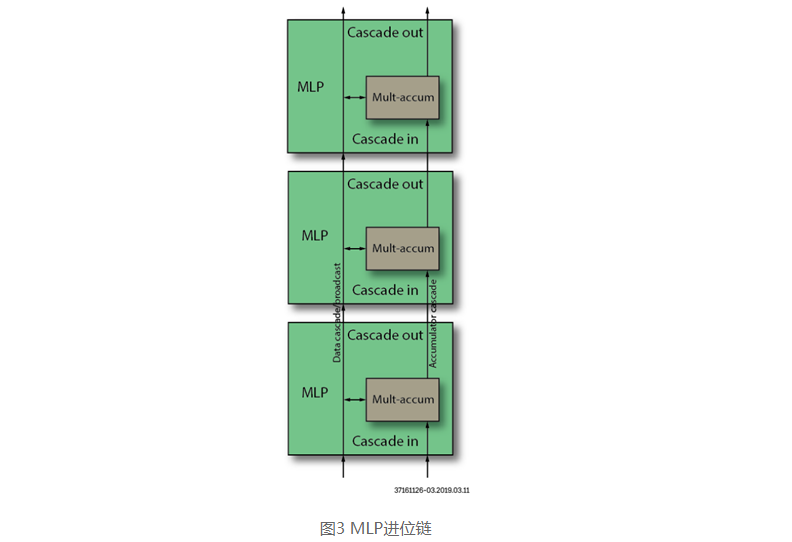
圖3 MLP進位鏈
● 乘法階段
下圖是MLP中浮點乘法功能階段,其中寄存器代表一級可選延遲。
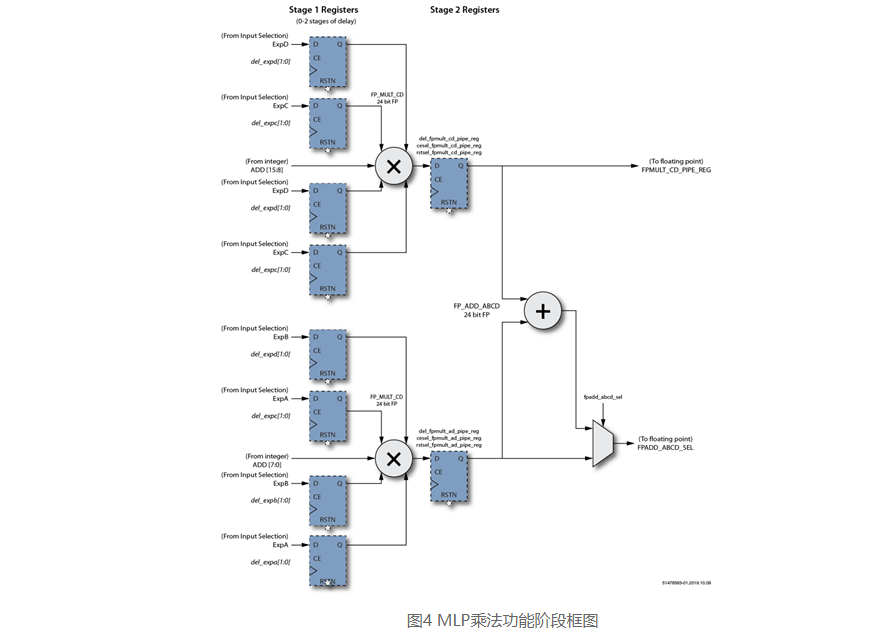
圖4 MLP乘法功能階段框圖
MLP72浮點乘法級包括兩個24位全浮點乘法器和一個24位全浮點加法器。兩個乘法器執行A×B和C×D的并行計算。加法器將兩個結果相加得到A×B + C×D。
乘法階段有兩個輸出。下半部分輸出可以在A×B或(A×B + C×D)之間選擇。上半部分輸出始終為C×D。
乘法器和加法器使用的數字格式由字節選擇參數以及和參數設置的格式確定。
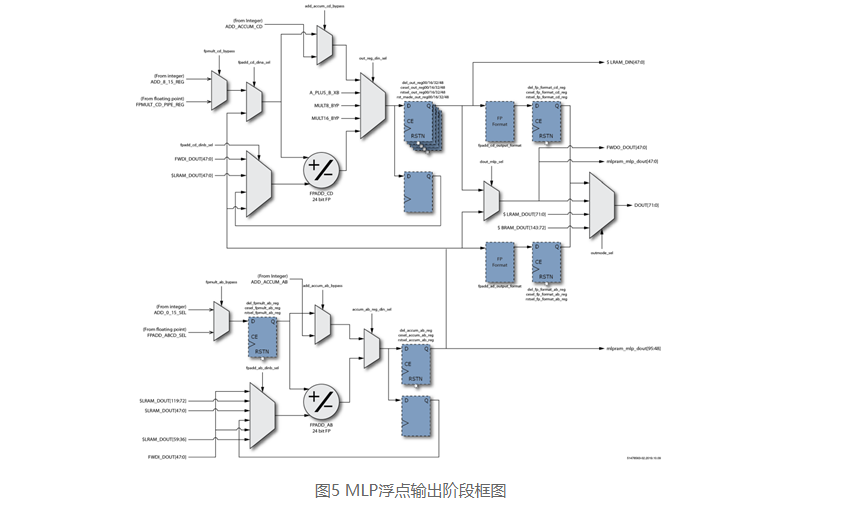
浮點輸出具有與整數輸出級相同的路徑和結構。MLP72可以配置為在特定階段選擇整數或等效浮點輸入。輸出支持兩個24位全浮點加法器,可以對其進行加法或累加配置。 進一步可以加載加法器(開始累加),可以將其設置為減法,并支持可選的舍入模式。
最終輸出階段支持將浮點輸出格式化為MLP72支持的三種浮點格式中的任何一種。 此功能使MLP72可以外部支持大小一致的浮點輸入和輸出(例如fp16或bfloat16),而在內部以fp24執行所有計算。
圖5 MLP浮點輸出階段框圖
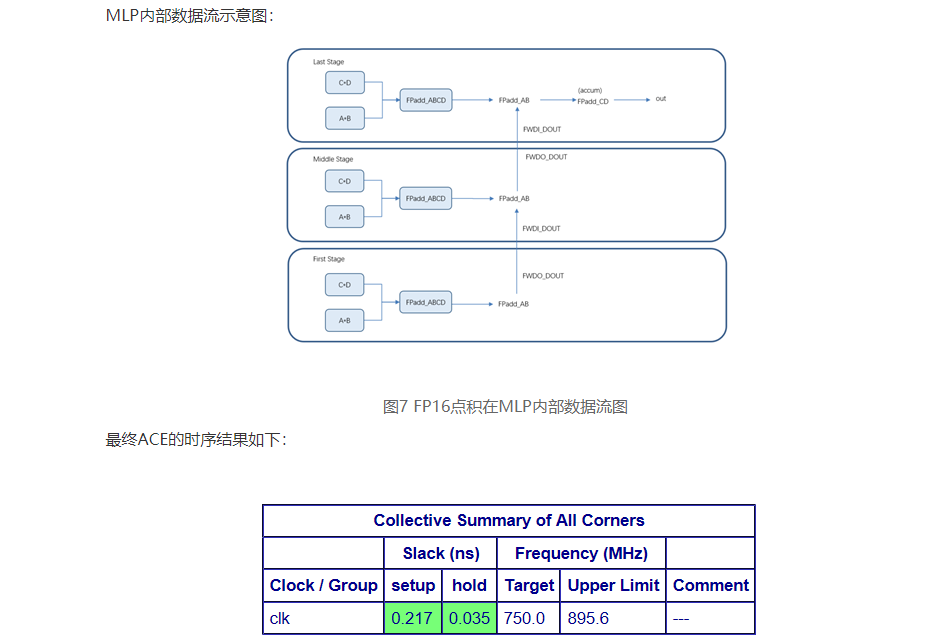
需要強調的是本設計輸入和輸出都是FP16格式,中間計算過程,即進位鏈上的fwdo_out和fwdi_dout 都是FP24格式。具體邏輯框圖如下所示:
圖6 FP16點積邏輯框圖
-
FPGA
+關注
關注
1660文章
22412瀏覽量
636303 -
卷積
+關注
關注
0文章
95瀏覽量
19011 -
機器學習
+關注
關注
66文章
8553瀏覽量
136946
發布評論請先 登錄
大模型推理服務的彈性部署與GPU調度方案
今日看點:消息稱 AMD、高通考慮導入 SOCAMM 內存;曦望發布新一代推理GPU芯片啟望S3
三電阻可調增益設計:FP130A與FP355的靈活配置實現

利用C語言union特性來定義RGB565格式
基于級聯分類器的人臉檢測基本原理
小白必讀:到底什么是FP32、FP16、INT8?

基于FP5207的兩級升壓方案,實現單節電池至48V高壓輸出

西井科技推出Hymala多式聯運物流樞紐大模型矩陣
計算精度對比:FP64、FP32、FP16、TF32、BF16、int8
將Whisper大型v3 fp32模型轉換為較低精度后,推理時間增加,怎么解決?
SiC MOSFET并聯運行實現靜態均流的基本要求和注意事項




 工商網監
工商網監
評論