 有關深度森林的新論文和Jeffery Dean機器學習進展研究綜述
有關深度森林的新論文和Jeffery Dean機器學習進展研究綜述

本周的論文既有周志華有關深度森林的新論文和Jeffery Dean機器學習進展研究綜述,也有華為和DeepMind的學術之爭。
目錄:
Multi-label Learning with Deep Forest
Unifying machine learning and quantum chemistry with a deep neural network for molecular wavefunctions
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
CenterMask : Real-Time Anchor-Free Instance Segmentation
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
EfficientDet: Scalable and Efficient Object Detection
α^α-Rank: Practically Scaling α-Rank through Stochastic Optimisation
論文 1:Multi-label Learning with Deep Forest
作者:Liang Yang、Xi-Zhu Wu、Yuan Jiang、Zhi-Hua Zhou
論文鏈接:https://arxiv.org/pdf/1911.06557.pdf
摘要:在多標簽學習領域,每個勢力都和多個表現相關聯,因此最重要的任務是如何讓構建的模型學到標簽關系。深度神經網絡通常會聯合嵌入特征和標簽信息到一個隱式空間,用于發掘表現關系。然而,這一方法能夠成功是因為對模型深度的準確選擇。深度森林是近來基于集成樹模型的深度學習框架,不依賴反向傳播。研究者采用了深度森林算法用于解決多標簽問題。因此,他們設計了 MLDF 方法,包括兩個機制:重復利用度量感知特征和度量感知層增長。度量感知特征重復利用機制能夠根據置信度重新使用之前層使用過的好的特征。而度量感知層增長機制則保證 MLDF 會根據性能瓶頸逐漸提升模型的復雜度。MLDF 同時解決了兩個問題:一個是控制模型復雜度以減少過擬合問題,另一個是根據用戶需求優化性能評價,因為在多標簽學習評價中有很多不同的度量標準。實驗說明,研究者提出的方法不僅在基準測試的 6 個評價標準上勝過了其他方法,還具有多標簽學習中標簽關系發掘和其他不錯的特性。
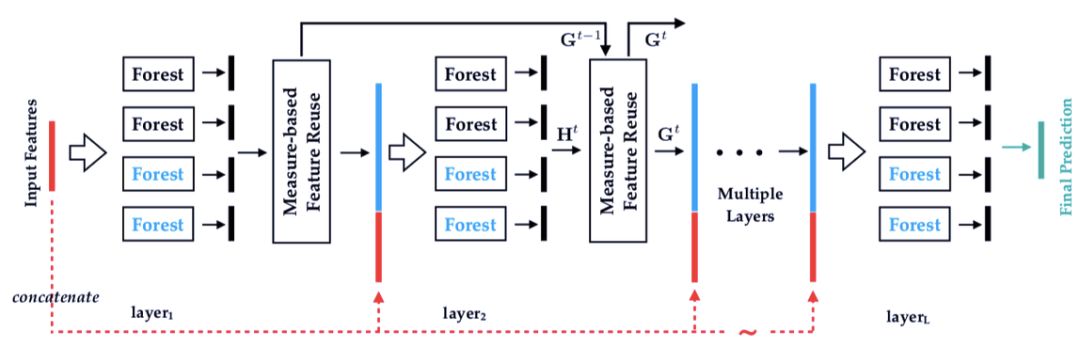
圖 1:多標簽深度森林算法(NLDF)。每個層集成兩個不同的森林(上部的黑色和下部的藍色)。

度量感知特性重復利用的算法圖示。

度量感知層增長的圖示。
推薦:近日,南大周志華等人首次提出使用深度森林方法解決多標簽學習任務。該方法在 9 個基準數據集、6 個多標簽度量指標上實現了最優性能。
論文 2:Unifying machine learning and quantum chemistry with a deep neural network for molecular wavefunctions
作者:K. T. Schütt、M. Gastegger、A. Tkatchenko、K.-R. Müller、R. J. Maurer
論文鏈接:https://www.nature.com/articles/s41467-019-12875-2
摘要:通過對基于量子化學計算的化學空間進行大規模探索,機器學習可以促進化學和材料科學的發展。雖然這些機器學習模型可以對原子化學屬性進行快速和準確的預測,但卻無法顯式地捕獲到分子的電子自由度,由此限制了它們對反應化學和化學分子的適用性。在本文中,研究者提出了一種深度學習框架,用于在原子軌道局部基中預測量子力學波函數,進而可以推導出其他基態性質。通過類力場效率下的波函數,這種方法可以繼續完全訪問電子結構,并以一種分析上可微的表征捕獲到了量子力學。在列舉的幾個例子中,研究者證明這將為針對電子性能優化的分子結構逆向設計提供有前途的方法,并為增強機器學習和量子化學之間的協同提供清晰的發展道路。
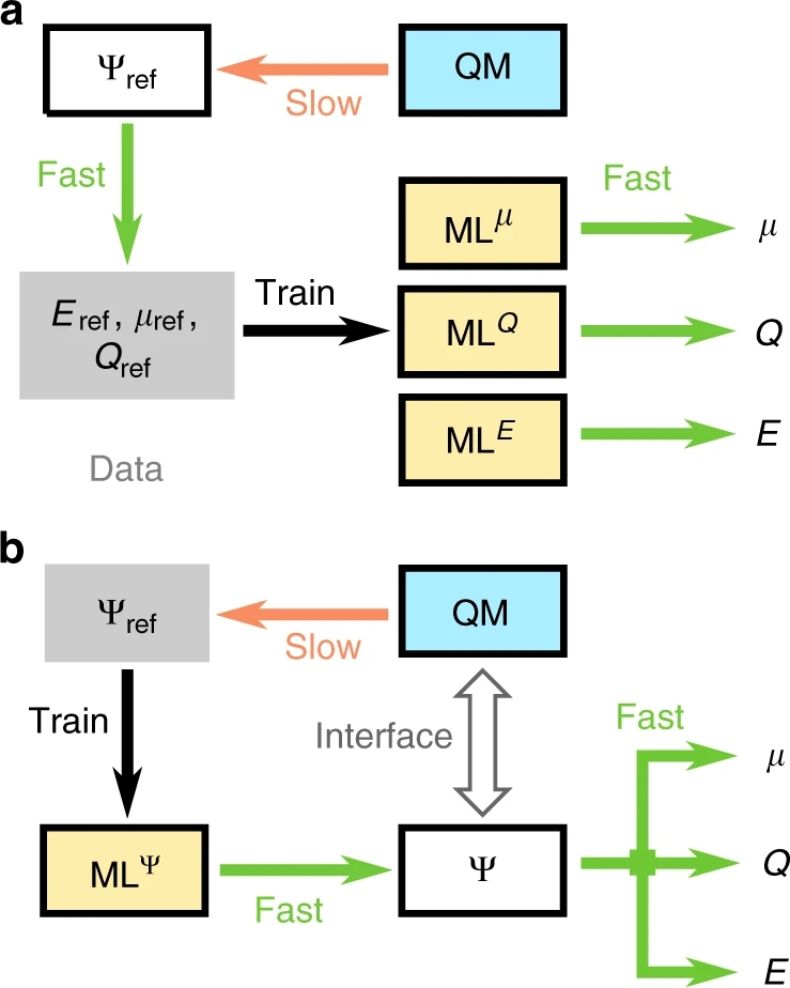
量子化學與機器學習的協同。a 表示前向模型,機器學習基于參考計算預測化學性能;b 表示混合模型,機器學習預測波函數。
推薦:本文作者通過一個新穎的深度學習框架,進一步探索了機器學習在量子化學領域的作用,刊登在了《Nature Communications》上。
論文 3:The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
作者:Jeffery Dean
論文鏈接:https://arxiv.org/abs/1911.05289
摘要:過去十年我們見證了機器學習的顯著進步,特別是基于深度學習的神經網絡。機器學習社區也一直在嘗試構建新模型,用于完成具有挑戰性的工作,包括使用強化學習,通過和環境進行交互的方式完成難度較大的任務,如下圍棋、玩電子游戲等。機器學習對算力的需求無疑是龐大的,從計算機視覺到自然語言處理,更大的模型和更多的數據往往能夠取得更好的性能。在摩爾定律時代,硬件進步帶來的算力增長尚且能夠滿足機器學習的需求,但當摩爾定律被榨干后,怎樣讓硬件中的算力資源被機器學習模型充分利用成了下一個需要探討的問題。
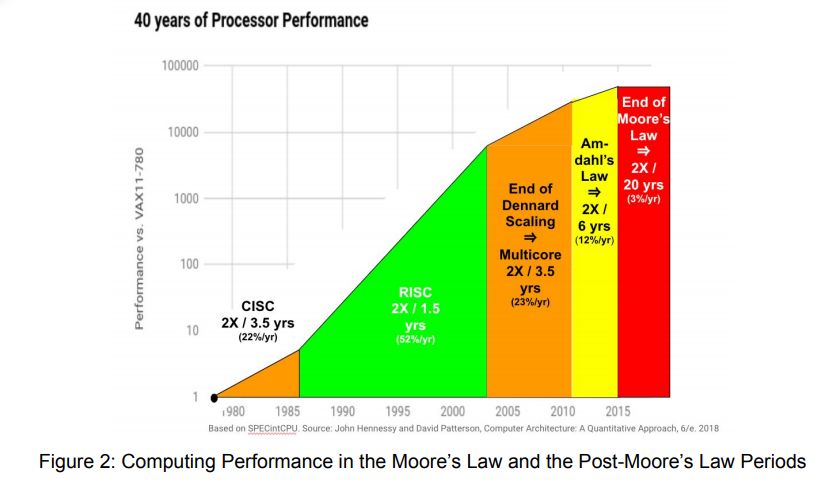
摩爾定律和后摩爾定律時代的計算需求增長態勢,其中自 1985 年至 2003 年,通用 CPU 性能每 1.5 年提升一倍;自 2003 年至 2010 年,通用 CPU 性能每 2 年提升一倍;而 2010 年以后,通用 CPU 性能預計每 20 年才能提升一倍。

AlexNet、GoogleNet、AlphaZero 等重要的機器學習網絡架構以及它們的計算需求增長態勢。
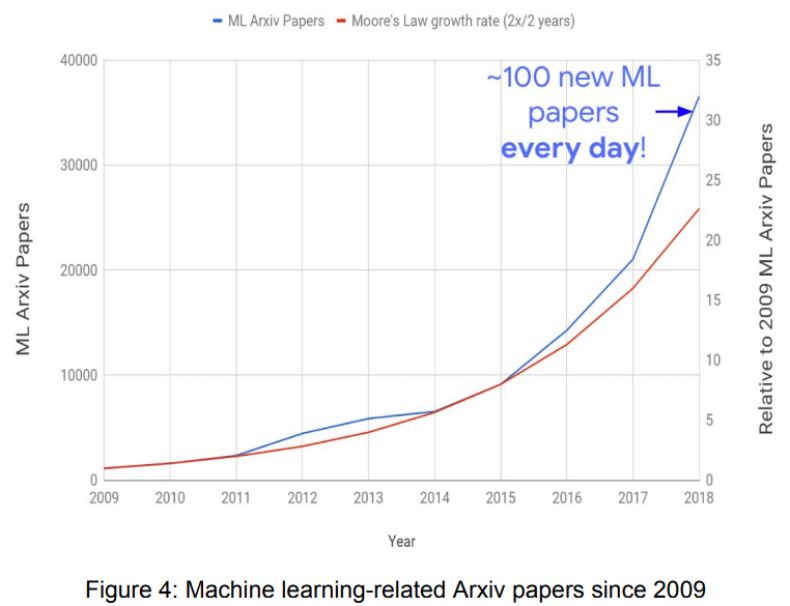
自 2009 年以來,機器學習相關 Arxiv 論文發表數量的增長態勢(藍)和摩爾定律增長率(紅)。
推薦:深度學習和硬件怎樣結合?Jeff Dean 長文介紹了后摩爾定律時代的機器學習研究進展,以及他對未來發展趨勢的預測判斷。
論文 4:CenterMask : Real-Time Anchor-Free Instance Segmentation
作者:Youngwan Lee、Jongyoul Park
論文鏈接:https://arxiv.org/abs/1911.06667
摘要:在本文中,來自韓國電子通訊研究院(ETRI)的兩位研究者提出了一種簡單卻高效的無錨點實例分割方法,被稱為 CenterMask,該方法將一個新穎的空間注意力導向 mask(SAG-Mask)添加進 anchor-free 單級目標檢測器中(FCOS),后者與 Mask R-CNN 相同。通 SAG-Mask 分支嵌入到 FCOS 目標檢測器中,它可以利用空間注意力地圖來每個框上預測分割掩碼,從而有助于分割掩碼。此外,研究者還展示了一種性能提升的 VoVNetV2,它有以下兩種有效策略:添加殘差連減弱接以緩解更大 VoVNet 的飽和問題;利用有效的擠壓-激勵(effective Squeeze-Excitation,eSE)處理原始 SE 的信息損失問題。借助于 SAG-Mask 和 VoVNetV2,研究者設計了分別針對大模型和小模型的 CenterMask 和 CenterMask-Lite。其中 CenterMask 的性能優于當前所有的 SOTA 模型,并且速度較這些模型更快;CenterMask-Lite 也實現了 33.4% 的 mask AP 和 38.0% 的 box AP 結果,并在 Titan Xp 顯卡上以 35fps 的速度分別超出了當前 SOTA 模型 2.6% 和 7.0% 的 AP gain。研究者希望 CenterMask 和 VoVNetV2 可以分別作為各種視覺任務上實時實例分割和骨干網絡的可靠基線。

CenterMask 架構。

CenterMask 與其他方法在 COCO tes-dev2017 數據集上的實例分割和檢測性能對比。
推薦:論文作者稱「CenterMask 的性能優于當前所有的 SOTA 模型,并且速度較這些模型更快」,分割精度也打敗了先前所有的 State-of-the-art!
論文 5:Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
作者:Julian Schrittwieser、Ioannis Antonoglou、Thomas Hubert 等
論文鏈接:https://arxiv.org/pdf/1911.08265.pdf
摘要:基于前向搜索的規劃算法已經在 AI 領域取得了很大的成功。在圍棋、國際象棋、西洋跳棋、撲克等游戲中,人類世界冠軍一次次被算法打敗。此外,規劃算法也已經在物流、化學合成等諸多現實世界領域中產生影響。然而,這些規劃算法都依賴于環境的動態變化,如游戲規則或精確的模擬器,導致它們在機器人學、工業控制、智能助理等領域中的應用受到限制。最受歡迎的方法是基于無模型強化學習的方法,即直接從智能體與環境的交互中估計優化策略和/或價值函數。但在那些需要精確和復雜前向搜索的領域(如圍棋、國際象棋),這種無模型的算法要遠遠落后于 SOTA。在新的研究中,DeepMind 聯合倫敦大學學院的研究者提出了 MuZero,這是一種基于模型的強化學習新方法。研究者在 57 個不同的雅達利游戲中評估了 MuZero,發現該模型在雅達利 2600 游戲中達到了 SOTA 表現。此外,他們還在不給出游戲規則的情況下,在國際象棋、日本將棋和圍棋中對 MuZero 模型進行了評估,發現該模型可以匹敵 AlphaZero 超越人類的表現,而且,在該實驗中,AlphaZero 提前獲知了規則。
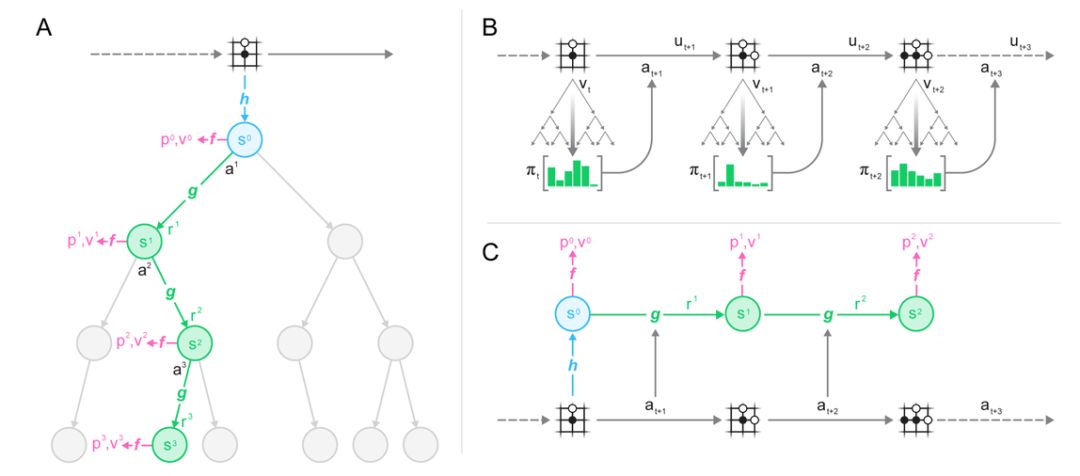
圖 1:用一個訓練好的模型進行規劃、行動和訓練。(A)MuZero 利用其模型進行規劃的方式;(B)MuZero 在環境中發生作用的方式;(C)MuZero 訓練其模型的方式。
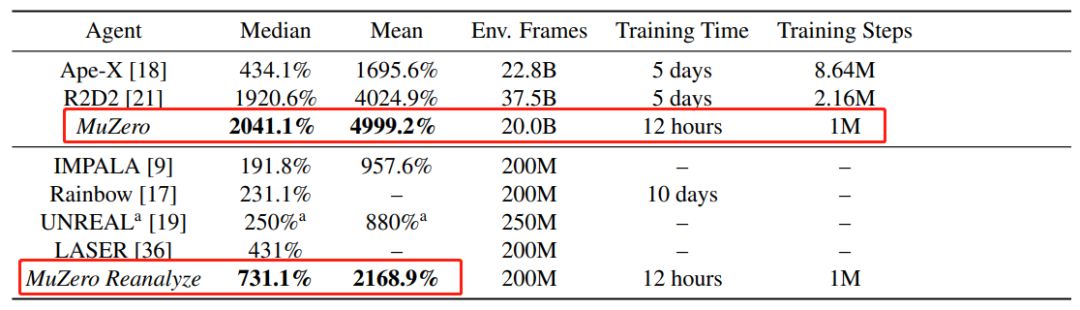
表 1:雅達利游戲中 MuZero 與先前智能體的對比。研究者分別展示了大規模(表上部分)和小規模(表下部分)數據設置下 MuZero 與其他智能體的對比結果,表明 MuZero 在平均分、得分中位數、Env. Frames、訓練時間和訓練步驟五項評估指標(紅框)取得了新的 SOTA 結果。
推薦:DeepMind 近期的一項研究提出了 MuZero 算法,該算法在不具備任何底層動態知識的情況下,通過結合基于樹的搜索和學得模型,在雅達利 2600 游戲中達到了 SOTA 表現,在國際象棋、日本將棋和圍棋的精確規劃任務中可以匹敵 AlphaZero,甚至超過了提前得知規則的圍棋版 AlphaZero。
論文 6:EfficientDet: Scalable and Efficient Object Detection
作者:Mingxing Tan、Ruoming Pang、Quoc V. Le
論文鏈接:https://arxiv.org/abs/1911.09070
摘要:在計算機視覺領域,模型效率已經變得越來越重要。在本文中,研究者系統地研究了用于目標檢測的各種神經網絡架構設計選擇,并提出了一些關鍵的優化措施來提升效率。首先,他們提出了一種加權雙向特征金字塔網絡(weighted bi-directional feature pyramid network,BiFPN),該網絡可以輕松快速地進行多尺度特征融合;其次,他們提出了一種復合縮放方法,該方法可以同時對所有骨干、特征網絡和框/類預測網絡的分辨率、深度和寬度進行統一縮放。基于這些優化,研究者開發了一類新的目標檢測器,他們稱之為 EfficientDet。在廣泛的資源限制條件下,該檢測器始終比現有技術獲得更高數量級的效率。具體而言,在沒有附屬條件的情況下,EfficientDet-D7 在 52M 參數和 326B FLOPS1 的 COCO 數據集上實現了 51.0 mAP 的 SOTA 水平,體積縮小了 4 倍,使用的 FLOPS 減少了 9.3 倍,但仍比先前最佳的檢測器還要準確(+0.3% mAP)。
推薦:本文探討了計算機視覺領域的模型效率問題,分別提出了加權雙向特征金字塔網絡和復合縮放方法,進而開發了一種新的 EfficientDet 目標檢測器,實現了新的 SOTA 水平。
論文 7:α^α-Rank: Practically Scalingα-Rank through Stochastic Optimisation
作者:Yaodong Yang、Rasul Tutunov、Phu Sakulwongtana、Haitham Bou Ammar
論文鏈接:https://arxiv.org/abs/1909.11628
摘要:作為 DeepMind「阿爾法」家族的一名新成員,α-Rank 有關強化學習,并于今年 7 月登上了《Nature Scientific Reports》。研究人員稱,α-Rank 是一種全新的動態博弈論解決方法,這種方法已在 AlphaGo、AlphaZero、MuJoCo Soccer 和 Poker 等場景上進行了驗證,并獲得了很好的結果。但是,華為的這篇論文指出,DeepMind 的這項研究存在多個問題。研究者認為,如果要復現這篇論文,需要動用高達一萬億美元的算力,這是全球所有算力加起來都不可能實現的。
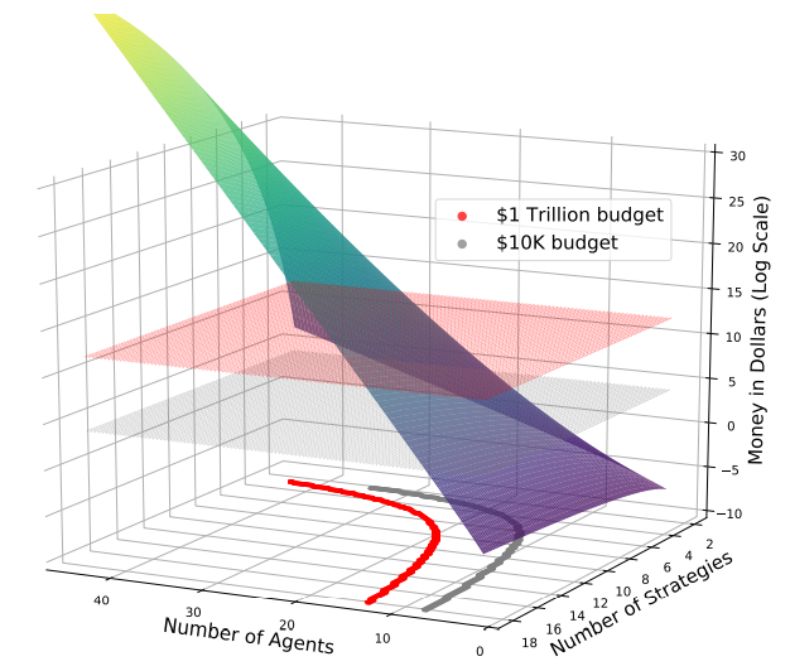
計算α-Rank 時構造轉換矩陣 T 的花銷成本。這里請注意,當前全球計算機的總算力約為 1 萬億美元(紅色平面)。投影輪廓線表明,由于α-Rank「輸入」的算力需求呈指數級增長,用十個以上的智能體進行多智能體評估是根本不可能的。
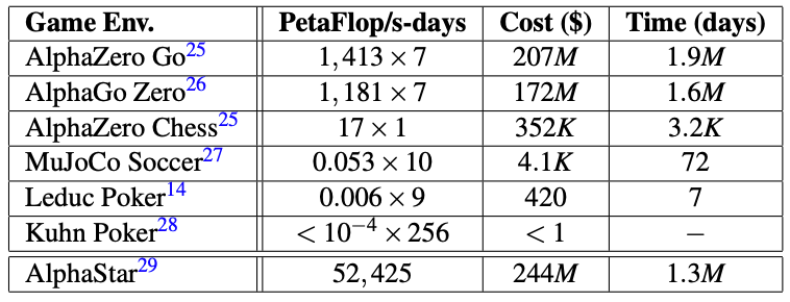
其他的算法也都不可行——在華為研究人員估算下,即使將收益矩陣加入α-Rank 跑 DeepMind 幾個著名算法需要用到的資金花費和時間都是天文數字。注意:在這里預設使用全球所有的算力。
推薦:近日,DeepMind 之前時間發表在 Nature 子刊的論文被嚴重質疑。來自華為英國研發中心的研究者嘗試實驗了 DeepMind 的方法,并表示該論文需要的算力無法實現。
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107808 -
深度學習
+關注
關注
73文章
5599瀏覽量
124401
原文標題:7 papers | 周志華深度森林新論文;谷歌目標檢測新SOTA
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
人工智能與機器學習在這些行業的深度應用
梁文鋒署名DeepSeek新論文:突破GPU內存限制的技術革命
機器學習和深度學習中需避免的 7 個常見錯誤與局限性

穿孔機頂頭檢測儀 機器視覺深度學習
如何深度學習機器視覺的應用場景
如何在機器視覺中部署深度學習神經網絡

中軟國際AI深度應用創新論壇成功舉辦
中國科學院西安光機所在計算成像可解釋性深度學習重建方法取得進展
機器學習賦能的智能光子學器件系統研究與應用

貿澤電子2025技術創新論壇探討“邊緣AI與機器學習”新紀元

智聚邊緣 創見未來丨貿澤電子2025技術創新論壇探討“邊緣AI與機器學習”新紀元

智聚邊緣 創見未來 貿澤電子2025技術創新論壇探討“邊緣AI與機器學習”新紀元
上海光機所在基于深度時空先驗的動態定量相位成像研究方面取得進展



 工商網監
工商網監
評論