 AI使用音頻剪輯對與語音匹配的真實感面部建模
AI使用音頻剪輯對與語音匹配的真實感面部建模

您是否曾經僅僅根據他們的聲音來構造一個從未見過的人的心理形象?人工智能(AI)現在可以做到這一點,僅使用簡短的音頻剪輯作為參考即可生成人臉的數字圖像。
這個名為“ Speech2Face” 的神經網絡(一種以類似于人腦的方式“思考”的計算機)經過科學家培訓,接受了來自互聯網的數百萬個教育視頻,顯示了100,000多個不同的人在說話。
研究人員在一項新研究中寫道,Speech2Face通過該數據集學習了語音提示與人臉某些物理特征之間的關聯。然后,AI使用音頻剪輯對與語音匹配的真實感面部建模。
值得慶幸的是,人工智能還不能僅僅根據他們的聲音確切地知道特定的人是什么樣。研究作者報告說,神經網絡識別語音中的某些標記,這些標記指向性別,年齡和種族,是許多人共有的特征。
科學家寫道:“因此,該模型只會產生看上去普通的面孔。” “它不會產生特定個人的圖像。”
盡管坦率地說,對貓的解釋有點讓人恐懼,但AI已經證明它可以產生出異常準確的人臉。
由Speech2Face生成的臉部-均面向正面并具有中性表情-與聲音背后的人并不完全匹配。但是,根據這項研究,這些圖像通常確實可以捕捉到正確的年齡范圍,種族和性別。
但是,該算法的解釋遠非完美。當面對語言變化時,Speech2Face表現出“混合表現”。例如,當AI收聽亞洲人講中文的音頻片段時,該程序會產生亞洲人臉的圖像。然而,據科學家報道,當同一個人用不同的音頻片段講英語時,人工智能產生了白人的面孔。
該算法還顯示出性別偏見,將低音調的聲音與男性面孔相關聯,將高音調的聲音與女性面孔相關聯。研究人員寫道,由于訓練數據集僅代表YouTube上的教育視頻,因此“并不代表整個世界人口。”
-
數字圖像
+關注
關注
2文章
122瀏覽量
19581 -
人工智能
+關注
關注
1817文章
50094瀏覽量
265276 -
數據集
+關注
關注
4文章
1236瀏覽量
26190
發布評論請先 登錄

語音跳線:構建高效音頻傳輸系統的核心組件
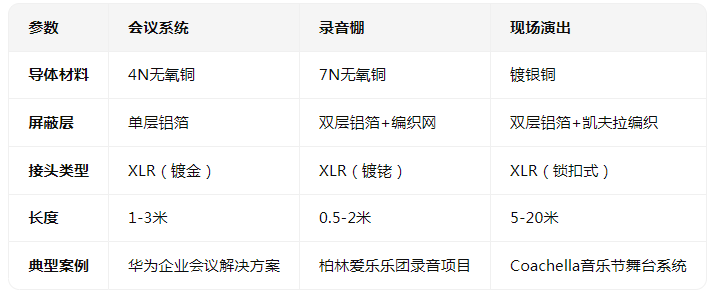
應用 I 音頻接口防護方案

新品 | Module ASR,AI智能離線語音模塊

深度解析:康謀雙模態仿真測試解決方案!
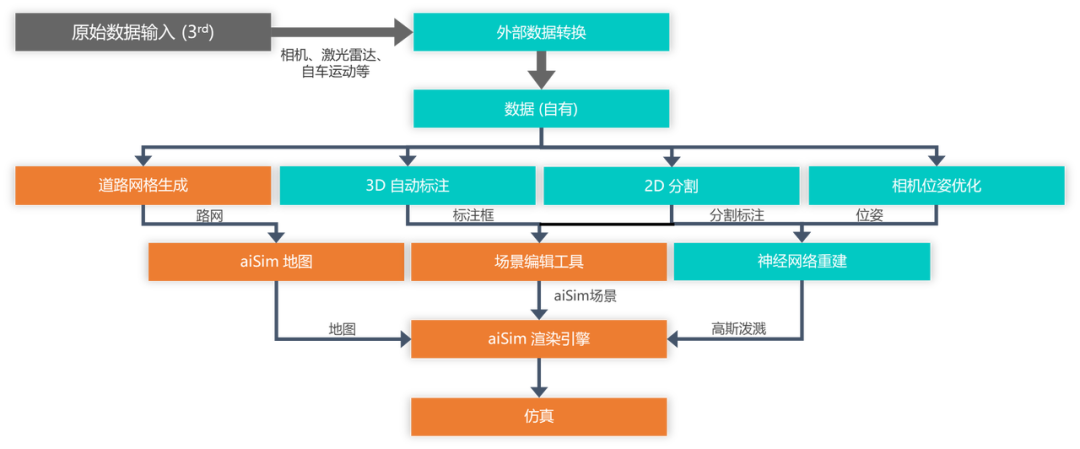
安信可小智AI語音模組實測:實現語音控制關燈

【AI語音模組】自制小智管家?安信可Ai-WV01-32S測試體驗

炬芯科技亮相2025亞洲AI音頻大會
唯創知音AI語音交互芯片與模組介紹




 工商網監
工商網監
評論