 電子發燒友App
電子發燒友App



?本文由奇異摩爾編譯自Semiengineering
國際能源署(IEA)報告指出,2020年,全球數據中心的用電量為200-250TWh,占約1%的全球總電力需求。而來自幾個大型網絡運營商的數據表明,能源效率的提高有助于將數據流量與能源使用脫鉤。在芯片功耗方面,任何幅度的降低都將大有助益,Chiplet設計的應用被認為可能有助于控制人工智能的電力消耗。
3D Chiplet設計能有效應對高性能計算挑戰,在近年來受到了越來越多高性能計算、AI芯片廠商的關注。在制程不變的情況下,基于異構計算的Chiplet能帶來算力的持續增長,實現大芯片功耗的大幅下降。不論對企業增長,還是對世界能源未來,都是一項值得推進的舉措。
----Kiwimoore”
機器學習正在消耗過多的能源,這種模式成本高昂、效率低下且不可持續。
很大程度上,機器學習是一個全新、令人興奮的且正在迅速增長的領域。機器學習原本的設計目的是在準確性和性能方面實現新的突破。但在今天,往往也意味著更大的模型和更大的訓練集,需要指數級增長的算力,訓練和推理都會在數據中心消耗大量電力。
機器學習所耗費的功率數目令人觸目驚心。在最近的Design Automation Conference上,AMD 首席技術官 Mark Papermaster 展示了一張幻燈片,展示了 ML 系統的能耗(圖1)與世界能源產量的對比。
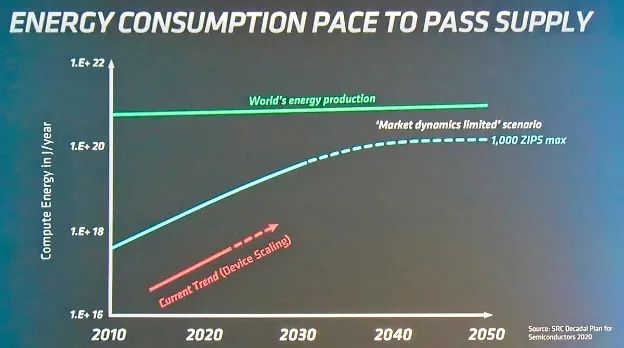
圖 1:ML 的能耗。資料來源:AMD
并非只有Papermaster在敲響警鐘。"我們已經忘記了,過去100年創新的驅動力是效率,"Perceive的首席執行官Steve Teig說。"這就是推動摩爾定律的原因。我們現在正處在一個反效率的時代。"
而Synopsys董事長兼首席執行官 Aart de Geus代表地球植物生態懇求對此有所行動。“能理解這件事的人,也應當有所做為。”
為什么能源消耗上升得如此之快?“神經網絡的計算需求是無法滿足的,” Arm研究員兼高級技術總監 Ian Bratt 說。“網絡越大,結果越好,你能解決的問題就越多。能源的使用與網絡規模成正比。因此,為了能夠采用越來越復雜的神經網絡和增強的用例,如實時語音和視覺應用,節能推理是絕對必要的。”
不幸的是,并不是每個人都關心效率問題。Mythic 負責產品和業務開發的高級副總裁 Tim Vehling 說:“你可以去看看超大規模公司在做什么,他們正在努力獲得更好、更準確的語音識別、語音文字識別、智能推薦系統。”?“這是一個跟錢直接掛鉤的問題。精確度越高,他們能服務的客戶就越多,也就能產生更多的利潤。看看數據中心的訓練和這些非常大的NLP模型的推理,那是消耗大量電力的地方。而且我不知道在這些應用中是否有任何動力來優化電力。"
當然,也有人的確在乎。Synopsys 的科學家 Alexander Wakefield 說:“有一些商業壓力要減少這些公司的碳影響,不是直接的財務政策,更重要的是部分消費者開始只接受碳中和的解決方案。”?“這是來自綠色能源方面的壓力,如果這些供應商之一說他們是碳中和的,更多的消費者可能會愿意埋單。"
但并非所有能源都是在云中被消耗的。越來越多的智能邊緣設備也導致了這個問題。"Aspinity公司戰略和技術營銷總監Marcie Weinstein說:“有數十億臺的設備構成了物聯網,在不遠的將來的某個時間點,它們將會耗費掉比我們在世界上產生的更多的電力。”?“消耗電力來收集和傳輸,并要用收集的數據做所需要的任何事情。”
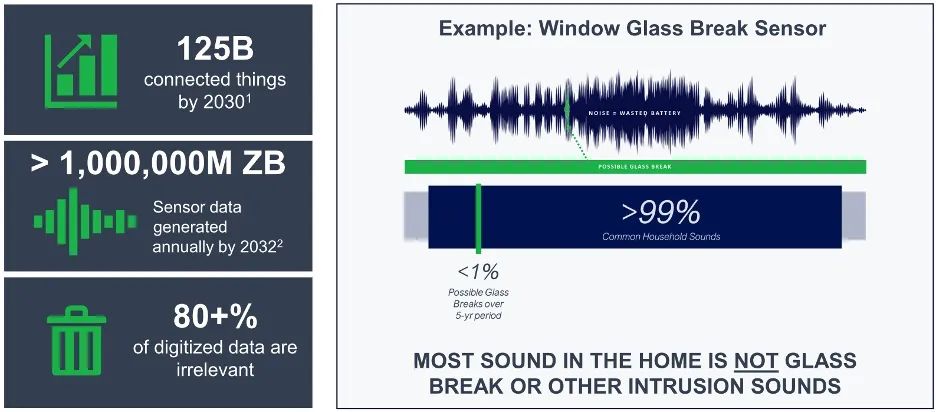
圖 2:邊緣處理的低效率。資料來源:Aspinity/ IHS / SRC
降低功耗
過去,科技界依靠半導體的縮放來使產品更加節能。“但我們的工藝技術正在接近物理極限” Arteris IP研究員兼系統架構師 Michael Frank 說。?“晶體管寬度在二氧化硅的 10 到 20 晶格常數之間。我們有更多帶有雜散電容的電線,并且在這些電線的充電和放電過程中會損失大量能量。在進入非線性區域之前,我們無法顯著的降低電壓,在該區域中,操作的結果是統計描述的,而不是確定性的。從技術方面來說,我無法給大家描述一個更好的未來。然而,有一個事實是,有一種設備只需要消耗大約 20 瓦就完成所有這些事情,包括學習。這就是所謂的大腦。”
那么 ML 是否比替代方案更有效?ICVS 產品經理 Joe Hupcey 說:“必須從其應用系統的角度考慮 ML 的功耗,其中權衡取決于包含 ML 與整個系統的功率配置文件所帶來的整體性能增益。”適用于西門子 EDA。“在許多應用領域中,業界已經開發出高效的 ML FPGA 和 ASIC,以降低訓練和推理的功耗,并且正在進行大量投資來延續這一趨勢。”
有一個影響可能迫使人們更加關注功率。"因為熱問題的存在,一些公司正在研究每平方微米的功率" Synopsys公司的科學家Godwin Maben說。"每個人都在擔心發熱問題。當你在一個小區域內把大量的gate堆在一起時,功率密度很高,溫度上升,你就會接近熱失控。功率密度現在正限制著性能。作為一個EDA供應商,我們不僅僅關注功率,因為當熱能進入畫面時,每瓦的性能,然后是每平方微米的每瓦性能,就變得很重要了。"
有幾種方法 “我通常喜歡查看每次推斷的能量,而不是功率,”西門子 EDA 的 HLS 平臺總監 Russ Klein 說。“單看功率可能有點誤導。例如,通常 CPU 比 GPU 消耗更少的功率。但 GPU 執行推理的速度比 CPU 快得多。結果是,如果我們查看每次推理的功率,GPU 可以使用 CPU 所需能量的一小部分來執行推理。”
消耗最多能量的地方尚不清楚,雖然這似乎很明顯,但結果卻頗有爭議。有兩個方面需要考慮——訓練與推理,以及邊緣與云。
訓練與推理
為什么訓練會消耗如此多的能量?“當您對同一個數據集進行多次迭代時,會消耗大量的能量,”Arteris 的 Frank 說。“你正在做梯度下降類型的近似。該模型基本上是一個超維曲面,你所做一些梯度是由通過多維向量空間下降的微商定義的。”
這樣做所消耗的能量正在迅速增加。“如果你看看兩年前訓練一個模型所需的能量,一些變壓器模型的能量在 27 千瓦時的范圍內,”Synopsys 的 Maben 說。“如果你看看今天的變壓器,它超過了 50 萬千瓦時。參數的數量從大約 5000 萬增加到 2 億。參數數量增加了四倍,但能量增加了超過 18,000 倍。歸根結底,它歸結為碳足跡以及這會產生多少磅的 CO2。”
這與推理相比如何?Cadence Tensilica AI 產品的產品營銷總監 Suhas Mitra 說:“訓練涉及向前和向后傳遞,而推理只是向前傳遞。”?“因此,推理的能力總是較低。此外,在訓練期間,批量大小可能很大,而在推理過程中,批量大小可能會更小。”
當你試圖估計這兩個函數消耗的總功率時,它會引起爭議。“關于哪個消耗更多能量、訓練或推理存在爭議,”馬本說。“訓練一個模型會消耗大量的能量,而根據這些數據進行訓練所需的天數是巨大的。但它是否比推理需要更多的能量?訓練是一次性費用。你花了很多時間在訓練上。訓練階段的問題是參數的數量,有些模型有 1500 億個參數。”
此外,訓練通常不止一次。“訓練不是一勞永逸的,”Mythic 的 Vehling 說。“他們不斷地重新訓練、重新優化模型,因此訓練是恒定的。他們不斷地調整模型,尋找增強功能,增強數據集,因此它或多或少是一項持續的活動。”
然而,推理可能會被重復多次。“你訓練一個模型,它可能是為自動駕駛汽車開發的,現在每輛車都使用這個模型,”Maben 補充道。“現在我們正在談論在大約 1 億輛汽車中進行推理。一項預測是,超過 70% 到 80% 的能量將用于推理而不是訓練。”
有一些數據可以支持這一點。"在Northeastern University和MIT最近的一篇論文認為,推理對能源消耗的影響大大超過了訓練,"Untether AI的高級產品總監Philip Lewer說。"這是因為模型是專門為推理而建立的,因此在推理模式下的運行頻率大大高于訓練模式--實質上就是訓練一次,多處運行。"
云與邊緣
將應用程序從云端遷移到邊緣可能是出于很多不同的原因。Expedera 營銷副總裁 Paul Karazuba 說:“市場已經看到,有些項目最好推到邊緣而不是云端。”?“我認為在邊緣完成什么和不做什么以及如何做出這些決定之間沒有明確的界限。我們看到了對邊緣更多 AI 的渴望,我們看到了對邊緣更多關鍵任務應用程序的渴望,而不是把人工智能作為盒子外面的一個印章。人工智能實際上是在設備中做一些有用的事情,不僅僅存在于那里。”
這并不是要你將云模型移動到邊緣。“假設你有一個自然語音、語音識別應用程序,”Mythic 的 Vehling 說。“你正在云端訓練這些模型。大多數時候,您都在運行這些模型以在云中進行推理。如果你查看更多位于邊緣的推理應用程序,那些不基于云的應用,你可以針對這些本地資源訓練模型。所以你要解決的幾乎是兩個不同的問題:一種是基于云的,另一種是基于邊緣的,它們不一定有聯系。”
模型的建立必須知道它們最終將在哪里運行。“你通常會發現數十億參數模型在云中運行,但這只是一種模型,”Vehling 補充道。“在另一個極端,你有少量的喚醒詞模型,它們占用的資源非常少——稱它們為小 ml 甚至更低。然后在中間是模型類別,例如可視化分析模型,你可能會在基于相機的應用程序中看到這些模型。它們比云中的模型小得多,但也比這種非常簡單的喚醒詞大得多。”
而且,處于邊緣的不僅僅是推理。我們可能會看到越來越多的訓練。“聯合學習就是一個例子,”Expedera 的首席科學家 Sharad Chole 說。“已經使用的一個領域是自動完成。每個人的自動完成功能可能會有所不同,如何學習?如何定制?必須在保護用戶隱私的情況下完成。這是個挑戰。”
邁向更高的效率
將應用程序從訓練系統轉移到邊緣涉及到重要的軟件堆棧。“一旦你通過了初始訓練階段,后續優化會提供明顯更輕的模型,而性能幾乎沒有下降”西門子的 Hupcey 說。“模型簡化技術用于降低推理過程中的功耗。模型簡化技術被用來降低推理過程中的功耗。量化、權重修剪和近似被廣泛用于模型訓練后或模型部署前的過程中。其中最明顯的兩個案例是TinyML和GPT-3的輕型版本"。
Klein補充道。"刪除和修剪是一個好的開始。量化為更小的數字表示也有幫助。可以將網絡的規模減少99%或更多,并且在許多情況下精度下降不到1%。有些人還研究了模型中的通道與層之間的交易,以產生更小的網絡而不影響準確性。
Klein 補充道:"刪除和修剪是一個好的開始。量化為更小的數字也有幫助。積極地進行,這些可以將網絡的大小減少 99% 或更多,并且在許多情況下導致精度下降不到 1%。有些人還研究了模型中的通道與層之間的交易,以在不影響準確性的情況下產生更小的網絡。”
這些技術既減小了模型的大小,又直接降低了能源需求,更多的改進是可能的。“現在我們看到了對混合精度的支持,每一層都可以量化到不同的域,”Expedera 的 Chole 說。“這種做法可以被進一步推動。也許將來權重的每個維度都可以量化為不同的精度。這種推動是有意義的,因為這樣一來,在訓練期間,數據科學家會意識到他們如何能夠降低功率,以及在降低功率的同時,他們正在做什么樣的準確性權衡。”
結論
模型變得越來越大以試圖獲得更高的準確性,但這種趨勢必須停止,因為它消耗的電量正在不成比例地增加。雖然云計算由于其商業模式,今天可以負擔得起,但邊緣卻不能。隨著越來越多的公司投資于邊緣應用,我們可以期待看到對能源優化的更多關注。
編輯:黃飛
?












 工商網監
工商網監
評論