 利用語音直接畫出人臉,AI再添新能力
利用語音直接畫出人臉,AI再添新能力

聽聲辨人,利用聲紋進行解鎖,這種技術已廣泛應用,人類的聲音含有該個體的一定特征,從而可以進行區分。那么僅通過聲音,能否畫出人像,并且盡可能地與講話者相似呢?
近日,卡內基梅隆大學的Yandong Wen 等人,利用生成對抗網絡模型(generative adversarial networks, GANs)首次對這一問題作出研究,利用講話者的語音生成一些匹配原說話者面部特征的人臉,并用交叉模態匹配(cross-modal matching task)評估了模型表現,可謂是語音畫像領域的一大突破。
模型框架
一個人的聲音和骨骼結構、發聲部位的形狀等特征的確有關,但利用語音直接畫出人臉,如何做到?
該由聲音重建人臉的模型框架主要由四個卷積網絡:語音嵌入模型(voice embedding network)、生成器(Generator)、判別器(Discriminator)、分類器(classifier)組成。
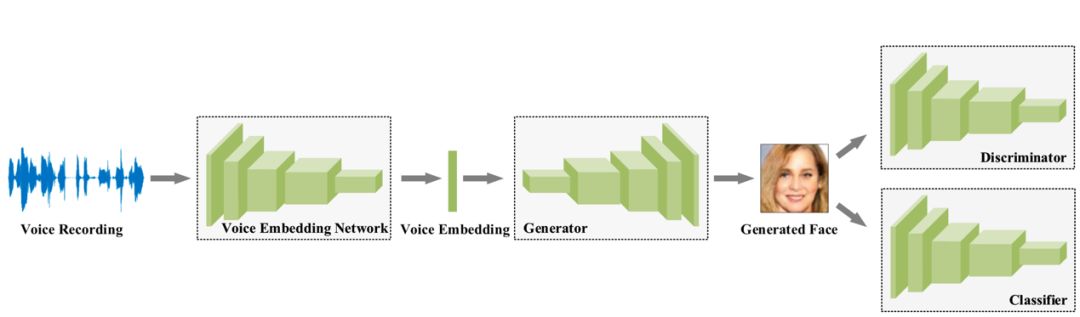
語音嵌入模型(voice embedding network)將輸入的語音數據,梅爾倒頻譜(log mel-spectrograms)轉換為含有該聲音特征的向量 e。該模型含有 5 層一維卷積神經網絡,每一層均是經由卷積核為 3、步長為 2、padding 為 1 得到,并且都經過歸一化層處理和 ReLU 單元激活,最后經過平均池化得到一個 64 維的向量。此模型是通過一個語音識別任務預先訓練得到參數,并且參數在生成人臉的訓練過程中保持不變。生成器(Generator)輸入為語音嵌入模型產生的向量 e,輸出是人臉 RGB 圖像 f',由 6 層二維反卷積網絡構成,激活函數采用 ReLU。
判別器(Discriminator)判斷輸入的圖像 f(或 f')是生成器偽造的圖像還是真實的人臉,如果判斷為偽造圖會加大損失 Ld。由 6 層激活單元為 Leaky ReLU 的二維卷積網絡構成,最后經過全連接層得到人臉圖像數據。
分類器(classifier)用來將人臉圖像與說話者匹配,如果匹配錯誤會加大損失 Lc。該模型由 6 層二維卷積網絡和一個全連接層組成。具體的結構如圖表,其中 Conv 3/2,1代表卷積核尺寸為 3,步長為 2,padding 填充為 1。
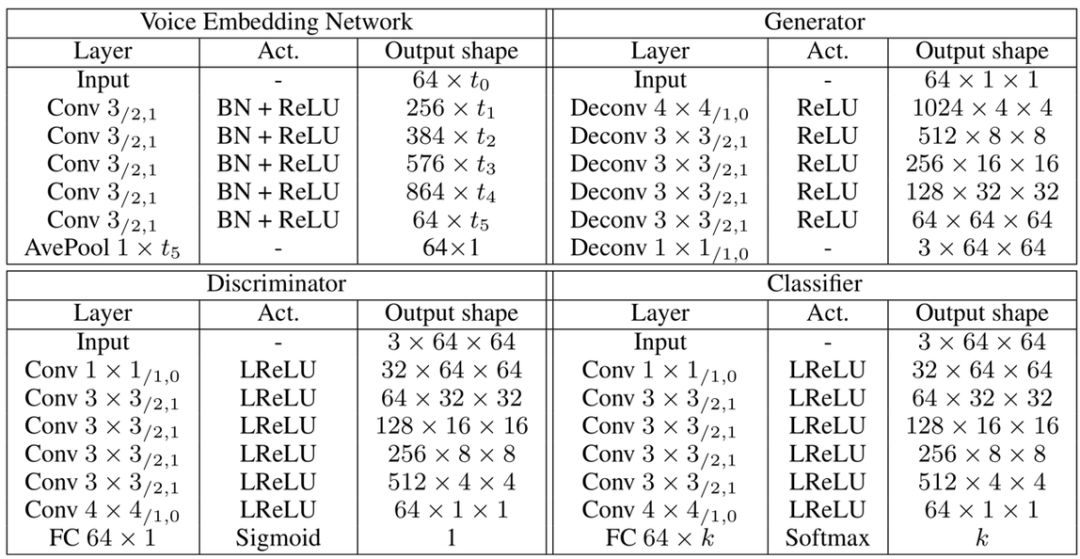
圖 | 從聲音重建人臉模型的具體結構。(來源:Yandong Wen, et al./CMU)模型通過最小化判別器與分類器的交叉熵損失 Ld 和 Lc 來訓練,以期得到圖像逼真且符合說話者特征的人臉。值得一提的是,此模型的測試集和訓練集以及驗證集相互獨立,即測試時的聲音是未聽過的,人臉也未知。
模型表現
不特意挑選那些人臉和真實講話者完美一致的結果,一般來講,該模型的確能輸出具有講話者特征的人臉,即使不完全一模一樣,從種族以及一些其他典型的面部特征來看,這個模型的確學習到了一些信息,輸出結果和原講話者非常像,并且語音時間越長,匹配的特征越多,兩者越類似。
圖 | 從不同時長的正常錄音生成人臉的結果圖,右側Ref為真實講話者的不同臉部照片,從上到下的 4 位 Speaker 分別是 Danica McKellar, Cindy Williams, Damian Lewis, and Eva Green. (來源:Yandong Wen, et al./CMU)當然,性別及年齡特征也可以很好地被學習到,左側輸出結果的年齡和性別與右側真實人臉的年齡性別保持一致。在整個測試集上,生成圖和真實講話者性別相同的概率可以達到 96.5%。
圖 | 從性別年齡的人臉重建,(a)是從老年聲音生成的人臉;(b)是男性聲音生成的人臉;(c)是女性聲音生成的人臉。其中左側為生成圖,右側為真實講話者。(來源:Yandong Wen, et al./CMU)如果用同一個人的不同語音片段,推測產生的人臉會保持相同特征嗎?模型結果告訴我們,是這樣。選用同一個講話者的 7 個不同語音片段,不特意挑選完美結果,模型所推測出的大概特征是十分一致的,這也側面說明,模型的確可以從一個人的語音抽取出一些特征,映射成其臉部的某些特征。
圖 | 利用一個人的 7 段不同語音重建人臉,左圖(a)是重建的 7 張人臉圖,右圖(b)是對應的真實人臉在不同情況的照片(來源:Yandong Wen, et al./CMU)進一步來講,如果從語音中學到的特征真的可以映射成面部的特征,那么生成人臉圖必定和真實講話者的臉部是對應匹配的。換句話說,聲音中的特征可以被生成人臉中蘊含的特征替代,那么由聲音重組人臉就變成了人臉識別問題,兩張臉(生成的和真實的)匹配,那么計劃可行,這個匹配率也就成了衡量模型表現的指標。在整個訓練集和測試集上,該模型的匹配率分別是 96.83% 和 76.07%;將訓練集和測試集按照性別分層,排除性別這一特征的助力,也就是直接比較同一性別上,生成的人臉和講話者是否相像,匹配率在訓練集和測試集上分別是 93.98%和 59.69%,這也證明了模型所學到的信息不僅僅是性別,還有其他更詳細的面部特征。該模型表現不僅優于 DIMNets-G,同時,測試集表現不如訓練集,說明模型還有很大提升空間。

圖 | 不同模型在性別分層以及不分層的數據集上的表現。(來源:Yandong Wen, et al./CMU)
展望
該模型雖然表現尚佳,但仍有可提升的地方,比如頭發和圖像背景等與聲音無關的特征,可以進行數據清洗將其去除,而有一些明顯與發聲有關的面部特征也可以加以利用,從而模型會更加精確。
總的來說,由音生貌,語音畫像問題的一塊空白得到了填補。
-
AI
+關注
關注
91文章
39793瀏覽量
301422 -
GaN
+關注
關注
21文章
2366瀏覽量
82344
原文標題:僅聽聲音就畫出人臉,GAN再添新能力
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
中軟國際在金融科技出海征程再添關鍵里程碑
水晶光電在ESG與AI領域再添殊榮
納芯微NSSine系列實時控制MCU/DSP再添新成員

【CPKCOR-RA8D1】關于AI人臉檢測移植遇到的一些問題
基于級聯分類器的人臉檢測基本原理
【CPKCOR-RA8D1】AI人臉檢測
如何使用語音指令控制串口輸出
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的科學應用
再掀語音交互革命,廣和通AI解決方案加速機器人聽覺進化
一顆TTS語音芯給產品增加智能語音播報能力
【嘉楠堪智K230開發板試用體驗】K230 AI 功能體驗
最新人工智能硬件培訓AI基礎入門學習課程參考2025版(離線AI語音視覺識別篇)
OBOO鷗柏丨AI數字人觸摸屏查詢觸控人臉識別語音交互一體機上市

90元打造小智AI腕表,語音交互超有趣!
上線!國產AI語音開發板,定制你的聊天伙伴助手,可直接調用DeepSeek/豆包/通義千問




 工商網監
工商網監
評論