") GitHub上現(xiàn)在托管有超過300種編程語言
GitHub上現(xiàn)在托管有超過300種編程語言

OctoLingua的目標(biāo)是提供一種服務(wù),支持從多個粒度級別(從文件級別或片段級別到潛在的行級語言檢測和分類)進行強大可靠的語言檢測。最終,該服務(wù)可以支持代碼搜索和共享、語法高亮顯示和差異渲染等,旨在支持開發(fā)人員進行日常開發(fā)工作,同時幫助編寫高質(zhì)量的代碼。
GitHub上現(xiàn)在托管有超過300種編程語言。從最廣泛使用的語言比如Python,Java、Javascript等,到一些非常非常小眾的語言例如Befunge,應(yīng)有盡有。
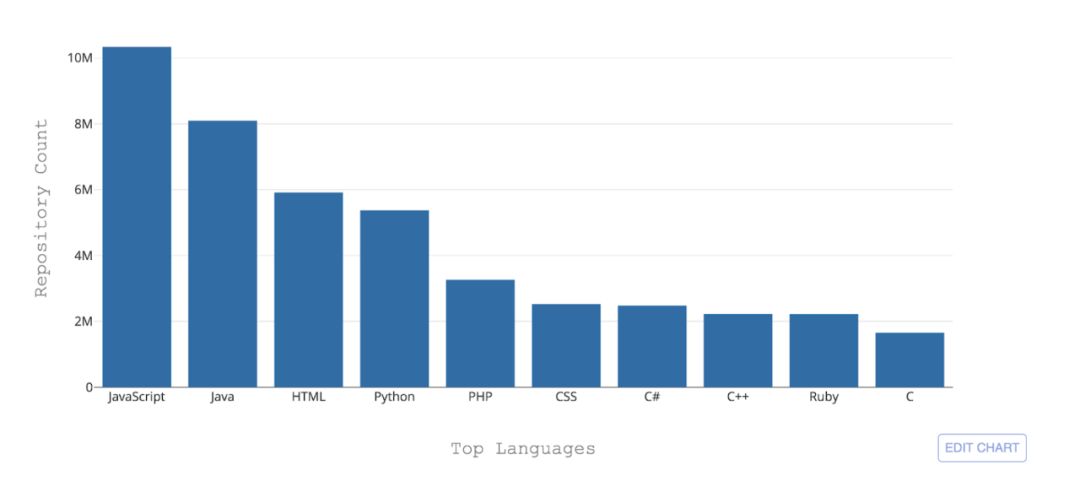
但豐富的語種帶來的一個挑戰(zhàn)就是,如何即時鑒別它們?這影響到如何更好的搜索、發(fā)現(xiàn)其中的安全漏洞或者采取什么樣的語法高亮。
而且編程語言識別起來,看似簡單實則非常困難。文件擴展名是一個非常重要的區(qū)分標(biāo)準(zhǔn),但很多時候非常混亂。比如“.pl”, “.pm”, “.t”, “.pod”,都跟Perl有關(guān)系;而“.h”,C、C++、Objective-C也都有在用。
甚至還會出現(xiàn)沒有擴展名的情況,例如一些可執(zhí)行腳本(curl,get,makefile等)。
Linguist已經(jīng)可以完成84%的語言檢測
那么GitHub是怎么解決上述問題呢?GitHub高級數(shù)據(jù)科學(xué)家Kavita Ganesan首先介紹了目前GitHub官方使用的語言鑒別工具:Linguist。
Linguist是一個基于Ruby的應(yīng)用程序,它使用多種策略進行語言檢測。比如利用命名約定和文件擴展名,考慮Vim或Emacs模型,以及文件頂部的內(nèi)容(shebang)等。
Linguist通過啟發(fā)式方法,通過一個小樣本數(shù)據(jù)訓(xùn)練的樸素貝葉斯分類器來進行語言消歧義。
雖然Linguist在文件級語言預(yù)測方面做得很好(準(zhǔn)確率為84%),但是當(dāng)文件使用非常特殊的命名約定時,準(zhǔn)確率就大幅下降了。更重要的是,當(dāng)遇到?jīng)]有提供文件擴展名的情況比如Gist、README文件、issue或者拉取請求中的代碼片段,Linguist就無能為力了。
人工智能幫助完成剩下的語言檢測工作
為了使語言檢測能夠更加健壯和可維護,GitHub又開發(fā)了一款名為OctoLingua的機器學(xué)習(xí)分類器,它基于人工神經(jīng)網(wǎng)絡(luò)(ANN)架構(gòu),可以處理棘手場景中的語言預(yù)測。
該模型的當(dāng)前版本能夠?qū)itHub托管的前50種語言進行預(yù)測,并在準(zhǔn)確性和性能方面超越Linguist。
OctoLingua從頭開始使用Python + Keras,以及TensorFlow后端進行構(gòu)建,非常準(zhǔn)確、健壯且易于維護。
數(shù)據(jù)源
OctoLingua的當(dāng)前版本使用了從Rosetta Code檢索的文件和內(nèi)部眾包的一組質(zhì)量庫的訓(xùn)練。語言集限制為GitHub上托管的Top 50。
Rosetta Code是一個出色的入門數(shù)據(jù)集,因為它包含用不同編程語言表示的相同任務(wù)的源碼。例如,生成Fibonacci序列的任務(wù)可以用C、C ++、CoffeeScript、D、Java、Julia等表示。
但是,跨語言的覆蓋范圍并不統(tǒng)一,其中某些語言只有少量文件而某些文件的填充程度過于稀疏。因此,需要增加一些額外來源的訓(xùn)練集,以提高語言覆蓋率和性能。
目前添加新語言的流程現(xiàn)已完全自動化,以編程方式從GitHub上的公共倉庫收集源碼。選擇滿足最低資格標(biāo)準(zhǔn)的倉庫,例如具有最小數(shù)量的分支,以及涵蓋目標(biāo)語言和涵蓋特定文件擴展名。
對于此階段的數(shù)據(jù)收集,使用Linguist的分類確定倉庫的主要語言。
特點:利用先驗知識
傳統(tǒng)上,對于神經(jīng)網(wǎng)絡(luò)的文本分類問題,通常采用基于存儲器的體系結(jié)構(gòu),例如遞歸神經(jīng)網(wǎng)絡(luò)(RNN)和長短期記憶網(wǎng)絡(luò)(LSTM)。
但是,鑒于編程語言在詞匯、評論風(fēng)格、文件擴展名、結(jié)構(gòu)、庫導(dǎo)入風(fēng)格和其他微小差異,GitHub選擇了一種更簡單的方法:通過以表格形式提取某些相關(guān)功能來利用所有這些信息,并投喂給分類器。目前提取的功能如下:
每個文件的前五個特殊字符
每個文件前20個令牌
文件擴展名
存在源碼文件中常用的某些特殊字符如冒號、花括號和分號
人工神經(jīng)網(wǎng)絡(luò)(ANN)模型
上述特征作為使用具有Tensorflow后端的Keras構(gòu)建的雙層人工神經(jīng)網(wǎng)絡(luò)的輸入。
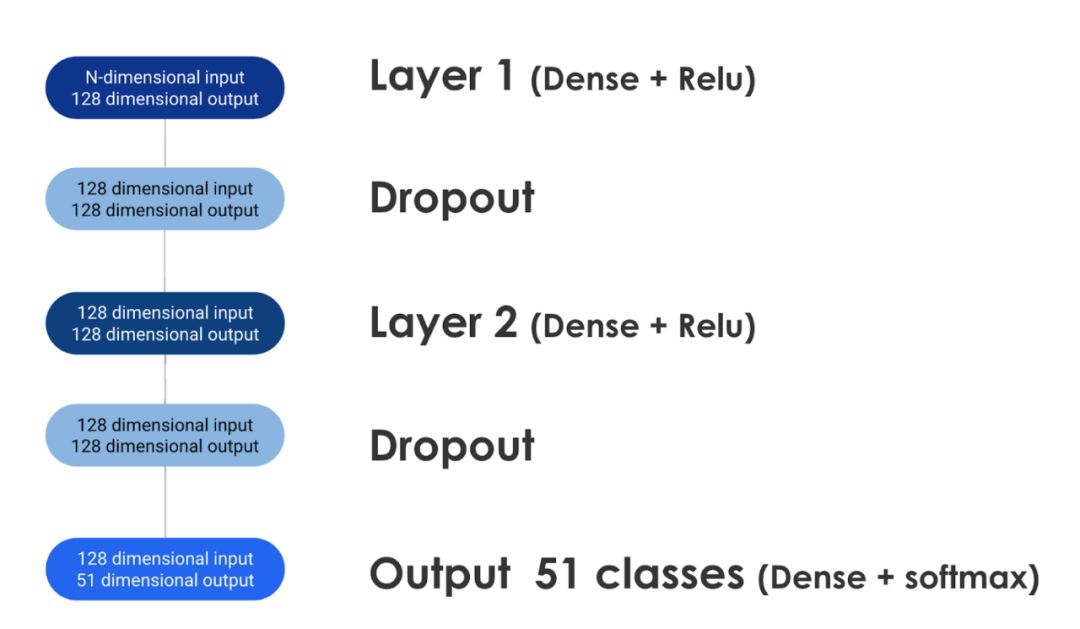
下圖顯示特征提取步驟為分類器生成n維表格輸入。當(dāng)信息沿著網(wǎng)絡(luò)層移動時,它通過dropout正則化并最終產(chǎn)生51維輸出,該輸出表示給定代碼在前50種GitHub語言中每一種寫入的預(yù)測概率加不寫入的概率。
GitHub使用90%的數(shù)據(jù)集進行大約8個epochs的訓(xùn)練。此外,在訓(xùn)練步驟中從訓(xùn)練數(shù)據(jù)中刪除了一定百分比的文件擴展名,以鼓勵模型從文件的詞匯表中學(xué)習(xí),而不是過度填充文件擴展功能。
基準(zhǔn)
下圖顯示了在同一測試集上計算的OctoLingua和Linguist的F1得分(精確度和召回之間的調(diào)和平均值)。
這里展示三個測試。第一個是測試集不受任何干預(yù);第二個測試使用同一組測試文件,刪除了文件擴展名信息;第三個測試也使用相同的文件集,但這次文件擴展名被加擾,以便混淆分類器(例如,Java文件可能有“.txt”擴展名、Python文件可能具有“.java”)擴展名。
在測試集中加擾或刪除文件擴展名的目的是評估OctoLingua在刪除關(guān)鍵功能或誤導(dǎo)時對文件進行分類的穩(wěn)健性。不嚴(yán)重依賴擴展的分類器對要點和片段進行分類非常有用,因為在這些情況下,人們通常不提供準(zhǔn)確的擴展信息(例如,許多與代碼相關(guān)的文件具有.txt擴展名)。
下表顯示了OctoLingua如何在各種條件下保持良好的性能,表明該模型主要從代碼的詞匯表中學(xué)習(xí),而不是從元信息(即文件擴展名)中學(xué)習(xí)。但是沒有擴展名的話Linguist完全無法鑒別。

上圖是OctoLingua與Linguist在同一測試集上的表現(xiàn)。
在訓(xùn)練期間刪除文件擴展名的效果
如前所述,在訓(xùn)練期間,從訓(xùn)練數(shù)據(jù)中刪除了一定百分比的文件擴展名,以鼓勵模型從文件的詞匯表中學(xué)習(xí)。下表顯示了模型在訓(xùn)練期間刪除了不同分?jǐn)?shù)的文件擴展名的性能。

上圖在三個測試變體中刪除了不同百分比的文件擴展名后,OctoLingua的表現(xiàn)
請注意,在訓(xùn)練期間沒有刪除文件擴展名的情況下,OctoLingua對沒有擴展名和隨機擴展名的測試文件的性能與常規(guī)測試數(shù)據(jù)相比差距很大。而一旦在刪除某些文件擴展名的數(shù)據(jù)集上訓(xùn)練模型時,模型性能在修改的測試集上的差距就沒有那么大。
這證實了在訓(xùn)練時從一小部分文件中刪除文件擴展名,會使分類器從詞匯表中學(xué)到更多。它還表明,文件擴展功能雖然具有高度預(yù)測性,但卻傾向于支配并阻止將更多權(quán)重分配給內(nèi)容。
添加新語言支持
在OctoLingua中添加新語言非常簡單。它首先獲取新語言的大量文件,這些文件分為訓(xùn)練和測試集,然后通過預(yù)處理器和特征提取器運行。這個新的訓(xùn)練和測試裝置被添加到現(xiàn)有的訓(xùn)練和測試數(shù)據(jù)庫中。新的測試裝置允許驗證模型的準(zhǔn)確性是否仍然可以接受。

上圖使用OctoLingua添加新語言、
未來計劃
截至目前,OctoLingua正處于“先進的原型設(shè)計階段”。我們的語言分類引擎已經(jīng)強大且可靠,但還不支持我們平臺上的所有編碼語言。除了擴大語言支持 - 這將是相當(dāng)簡單的 - 我們的目標(biāo)是在各種粒度級別啟用語言檢測。我們當(dāng)前的實現(xiàn)已經(jīng)允許我們通過對機器學(xué)習(xí)引擎的一些小修改來對代碼片段進行分類。將模型帶到可以可靠地檢測和分類嵌入式語言的階段并不是太遙遠(yuǎn)。
我們也在考慮開源我們模型的可能性,如果您有興趣,我們很樂意聽取社區(qū)的意見。
-
編程語言
+關(guān)注
關(guān)注
10文章
1964瀏覽量
39563 -
人工智能
+關(guān)注
關(guān)注
1817文章
50095瀏覽量
265309 -
GitHub
+關(guān)注
關(guān)注
3文章
488瀏覽量
18664
原文標(biāo)題:GitHub機器學(xué)習(xí)代碼分類器:僅憑代碼輕松鑒別300種編程語言
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
GitHub王炸:AI編程進入"多智能體時代",1.8億人徹夜未眠

為什么單片機還在用C語言編程?
C語言的編程技巧
C語言和單片機C語言有什么差異
一文了解Mojo編程語言
Linux 編程語言盤點:從內(nèi)核到AI的全棧選擇
微軟開源GitHub Copilot Chat,AI編程迎來新突破
深入理解C語言:C語言循環(huán)控制

Windows Arm64托管運行器正式支持GitHub Actions
Gitee倉庫鏡像管理功能介紹

如何在 樹莓派 上編寫和運行 C 語言程序?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論