 加速AI落地、推動邊緣計算應用實踐——開放計算在中國行至高潮
加速AI落地、推動邊緣計算應用實踐——開放計算在中國行至高潮

8年后,在中國再談開放計算,不論是技術原動力還是整個產業生態,都有了翻天覆地的變化。
時間撥回2011年,Facebook 主導發起了OCP(Open Compute Project; 開放計算項目),旨在以開源開放的方式,重構當時的數據中心硬件,發展面向下一代數據中心的服務器、存儲、網絡、基礎設施等。
當時,我國互聯網技術正以驚奇世界的姿態飛速發展著。軟件開源已經成為趨勢,但如果你提到硬件開源,那年剛剛出現的從英文“Maker”翻譯過來的“創客”,會和你聊聊樹莓派,聊聊包括電路原理圖、設計圖在內的開源許可。
但這并不是OCP的著眼點,IT基礎設施才是。
同年,阿里巴巴、百度、騰訊三家發起ODCC組織的前身“天蝎計劃”,并在同年年底確立了最初的技術規范。
百度從2011到2014年間,幾乎花了3年的時間與OCP社區進行溝通,試圖推動在數據中心的分享與合作。但現實的反差是巨大的,由于國內外數據中心的巨大差異、地區的差異、認知的差異等限制,最終沒有達成共識。
時間來到2019年,國內互聯網和泛互聯網產業取得長足發展,也使得更多的中國企業共同站在這個舞臺上面向未來進行深入探討。今年也是繼2014年之后,百度重新回歸OCP。此時,OCP的成員企業大約達到200家,包括英特爾、谷歌、微軟、Facebook、LinkedIn以及中國的阿里巴巴、百度、騰訊、浪潮等,囊括了全球服務器采購量最大的企業用戶。
浪潮與OCP聯合主辦的首屆OCP China Day(開放計算中國日)6月25日在北京舉行,那么,現在在中國聊起開放計算,我們都在關注什么?
關注一:OAM——簡化AI基礎架構設計,加速創新設計
AI是OCP China Day上多次被提及的話題之一。伴隨著AI的火熱,有越來越多的AI芯片出現。但是在推動芯片落地時卻發現很大的問題,需要從零開始進行板卡兼容等工作。AI加速器越來越多,技術更新也越來越快,AI硬件系統的技術挑戰和設計復雜度在增加,將加速器集成到系統中通常需要大約6-12個月。這種延遲阻礙了AI加速器的快速采用。
基于此,OCP社區在服務器項目組下設立了OAI(OpenAccelerator Infrastructure)小組,負責開發OAM(OCP Accelerator Module)規范,將加速器模塊標準化,簡化AI基礎架構的設計,縮短硬件設計周期。OAM規范的內容包括電源/冷卻,穩健性,可維護性,配置,編程,管理和調試,以及模塊間通信,以擴展和輸入/輸出帶寬。OAM目前仍在開發階段,已經在3月14日公布了第一個非正式版本V0.85,4月30日公布了第二個非正式版本0.9。OAM標準,就是針對上述問題設計的一套指導AI硬件加速模塊和系統設計的標準,它集合定義了AI硬件加速模塊本身、主板、互聯拓撲、機箱、供電、散熱以及系統管理等系列設計規范,主要目標是通過模塊化、標準化來增強不同AI硬件加速模塊和系統的互操作性,加速新的AI硬件加速模塊的落地和應用。
為什么需要OAM?
先從典型的AI加速系統設計來看,它通常由三部分構成,包括承載多個OAI模塊的基板,控制整個系統執行流程的CPU,連接AI芯片和CPU的PCIe開關。由于PCIe供電能力有限,無法很好地支持高速互聯,所以出現了很多新的解決方案,這樣就出現了非標準系統。由于AI芯片之間和CPU之間需要互聯起來,由于計算節點的限制,包括對于存儲的需求、I/O互聯的需求不一樣,所以在設計PCIe拓撲的時候有差異,導致硬件系統適應新的需求比較困難。
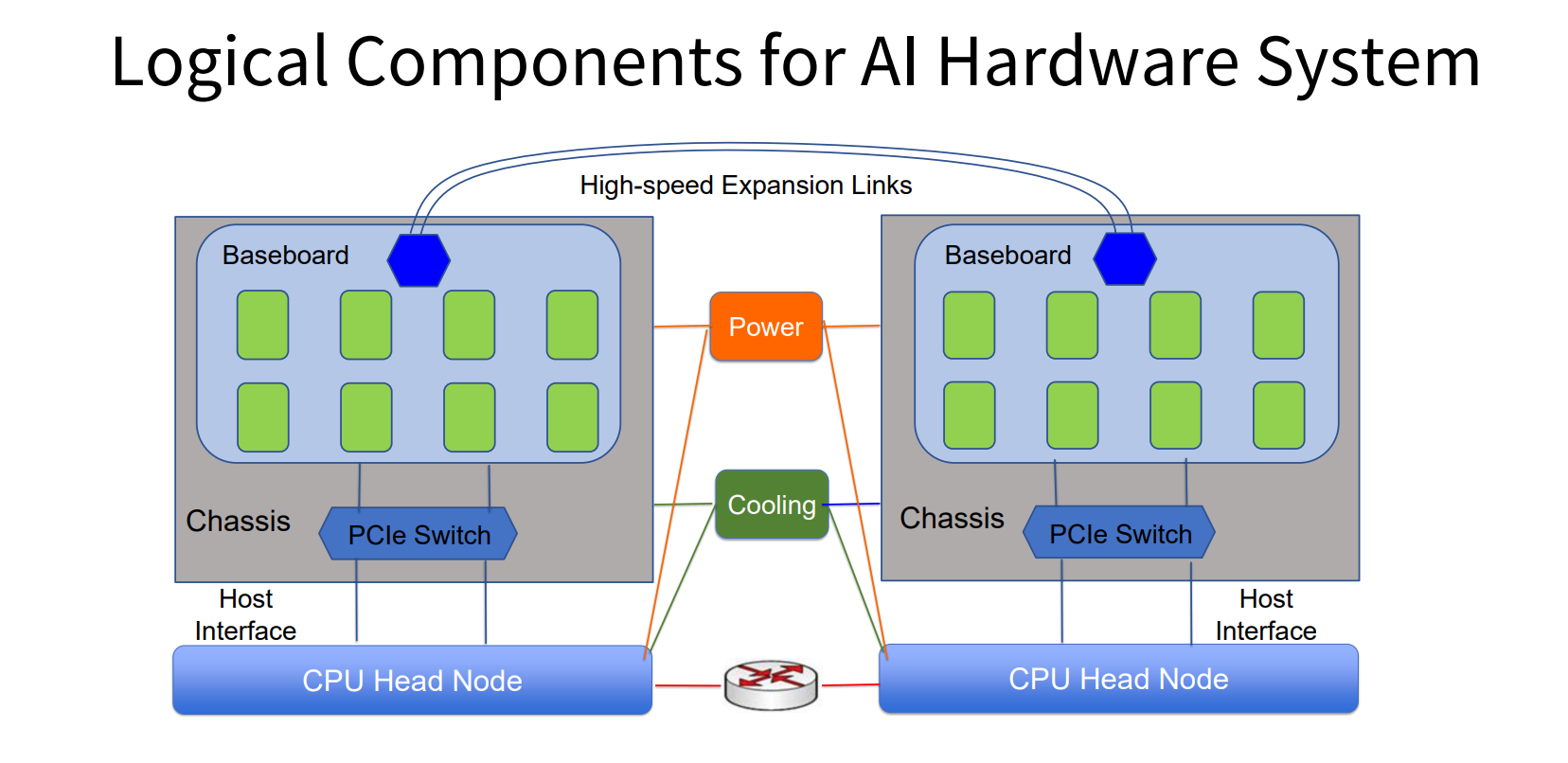
同時,大規模的AI的爆發需要很強大的算力,一個節點不夠用時,需要更好的擴展能力。有兩種典型方式:一是通過傳統的以太網交換機實現互聯,但是這個license費用比較高,互聯的帶寬也是有限的;二是通過新興技術實現AI加速芯片之間私有的互聯,這是一種更高速的互聯,有更低的延時,可以大幅提升大規模訓練的性能。從一個單機擴展到多機,構建了典型的大規模訓練系統。除此之外還有基礎設施,包括供電、散熱這些很有挑戰的問題。系統內不同模塊之間的組合能夠實現不同目標,取決于系統整體的權衡。
針對場景眾多的AI應用,不論是系統本身的設計,還是在系統的擴展方面,一家公司單槍匹馬攻克了一個目標之后,下一個目標可能又要重新設計方案。從這個角度看,長期快速跟進甚至引領市場比較困難,所以需要協作,開放AI加速的基礎架構,采用模塊化的思路,增強不同的模塊與系統之間的互操作性,加速相關技術的創新,推動新的AI芯片快速落地。
在這一過程中,OCP定義了AI加速的基礎架構規范,把相關模塊之間的邊界定義清楚,只要滿足相關接口都可以在系統中共存,這樣可以很好地將共性需求抽離出來,將特定的需求通過模塊化的形式去滿足,能夠更好地加速相關創新。
當前公布的OAM標準,是由參與OCP開放計算項目的百度、微軟、Facebook三家國際AI領先企業聯合定義,已經得到包括Google、阿里、騰訊等互聯網企業,英偉達、英特爾、AMD、高通、賽靈思等AI芯片企業,Graphcore、Habana Labs等AI芯片及處理器初創企業,以及IBM、浪潮等廠商的參與和支持。
關注二:邊緣計算的應用實踐
伴隨著5G的到來,邊緣計算也來了。目前看來,似乎只有自動駕駛、VR/AR等應用場景提出了低延遲、高帶寬的需求,智慧城市、工業互聯網等提出了高帶寬、低延時以及安全方面的要求。在此基礎上,如何發展邊緣計算?如何滿足邊緣計算的需求?仍然不清楚。
針對邊緣計算的實踐,百度提出了“DEC”(Device、Edge、Cloud)算力部署,中國移動認為運營商提供分流管道,邊緣計算業務由行業客戶自營。提到邊緣計算,勢必要考慮邊緣服務器的特性。它需要緊湊、可擴展的功能,并且提供短期高溫環境。
但是,服務器的研發周期很長,從研發到批量供貨需要1年時間,此后還會難以避免的進行部分升級換代,比如,主板升級、PCI-E模塊的升級等,這些升級很可能會帶來服務器主體設計的重構,很多時候不得不從頭開始研發新一代服務器。
對邊緣服務器的看法,中國移動主要看到三方面:業務需求、機房條件和本身的可維護性。可能在未來邊緣計算的大規模部署的時候,如果確定了一個比較具體的場景,會有一種模塊化的交付方式,使得能夠非常快速,大批量的跟軟件一起來交付。
騰訊與浪潮研發的T-Flex2.0架構就是為了解決上述問題,對空間進行有效規劃, 通過I/O池化技術(支持PCI-E交換和Gen-z兩類互聯協議)支持未來模塊化迭代和靈活組合, 服務器可以單獨升級部分模塊并不影響其他模塊,T-Fle2.0x是一個更為靈活的架構。
從前向后,T-Flex2.0高度為2OU,分為A、B、C等3個區,每個區域可以放置不同的模塊,實現服務器的主體功能,覆蓋各類應用場景,甚至可以去掉A區或者C區,減少長度成為一款邊緣計算服務器。
作為OCP、Open19和ODCC全球三大開放計算標準組織的共同成員,浪潮從貢獻IP,參與開發標準到主導標準制定,在開放硬件社區中的參與度越來越高,先后貢獻了首批基于Open19標準的服務器、第一款OCP標準基于Intel Skylake平臺的主板、第一款Olympus四路服務器。同時,浪潮還參與了OCP OAM項目,牽頭成立了OpenRMC項目,開發完成了全球第一個基于OCP標準的整機柜管理架構。
關注三:OpenRMC項目,下一代數據中心的管理框架
OpenRMC是OCP社區硬件管理項目組下的子項目組,由浪潮牽頭成立。該項目目標是完成OpenBMC與Redfish的融合,形成下一代數據中心管理的統一框架。OpenBMC是Facebook發起的開源項目,希望解決閉源的BMC(Baseboard Management Controller,基板管理控制器)以及相關的軟件包標準不一的問題,這個問題給數據中心統一管理帶來了很多技術障礙。DMTF(Distributed Management Task Force,分布式管理任務組)制定了下一代服務器管理技術標準Redfish,以取代當前IPMI 2.0,Redfish具有擴展性好、功能豐富、針對地址不同和供應商不同的基礎設施向客戶提供規范化管理接口的優點,能夠滿足現代數據中心的管理需求。
OpenRMC項目希望能夠解決兩個標準之間的互操作性等一系列問題,并建立協同機制,形成規范,推進下一代數據中心管理技術和產業的發展。
未來,數據中心繼續充滿挑戰,數據中心整合將繼續推進。邊緣計算也將以更快的速度實現增長。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
OCP
+關注
關注
0文章
83瀏覽量
17081 -
5G
+關注
關注
1367文章
49155瀏覽量
616658 -
邊緣計算
+關注
關注
22文章
3527瀏覽量
53457
發布評論請先 登錄
相關推薦
熱點推薦
重磅合作!Quintauris 聯手 SiFive,加速 RISC-V 在嵌入式與 AI 領域落地
(ADAS);
嵌入式平臺的 AI 與機器學習加速器;
工業物聯網與自動化系統(開放標準架構的優勢能充分發揮)。
對咱們開發者來說,這波合作最大的好處就是能拿到集成式解決方案,不僅能縮短開發周期,還能
發表于 12-18 12:01
一文了解ai計算盒子(邊緣計算盒子)是到底是什么產品?
在物聯網與人工智能深度融合的當下,數據處理的效率和實時性成為各行業數字化轉型的關鍵。ai計算盒子(又稱邊緣計算盒子、ai

邊緣計算中的AI加速器類型與應用
人工智能正在推動對更快速、更智能、更高效計算的需求。然而,隨著每秒產生海量數據,將所有數據發送至云端處理已變得不切實際。這正是邊緣計算中AI

【今晚7點半】正點原子 x STM32:智能加速邊緣AI應用開發!今晚正點原子B站直播間等你
【聯合直播】正點原子 x STM32:智能加速邊緣AI應用開發!
一、直播介紹 隨著人工智能技術在邊緣計算領域的快速發展,STM32系列
發表于 09-25 14:14
此芯科技發布“合一”AI加速計劃,賦能邊緣與端側AI創新
產品組合,覆蓋從1.5B至32B參數規模的端側AI模型推理需求,滿足工業、消費電子、智能終端等多樣化場景的部署需求,推動AI技術從云端向邊緣高效落地

智慧農業新基建:邊緣計算網關在精準農業中的落地實踐案例
智慧農業新基建:邊緣計算網關在精準農業中的落地實踐案例 傳統農業生產中,水肥管理依賴經驗判斷,往往造成資源浪費和產量不穩定;同時,惡劣的自然環境也給農業生產帶來諸多挑戰。而藍蜂
研華推出ACE應用導向邊緣計算解決方案及WISE-STACK私有云平臺
研華科技今日舉辦法說會,公司2025上半年營收呈雙位數成長。面對市場對邊緣計算與 AI 的高度需求,研華推出ACE應用導向邊緣計算方案與WI
AI 邊緣計算網關:開啟智能新時代的鑰匙?—龍興物聯
在數字化浪潮的當下,AI 邊緣計算網關正逐漸嶄露頭角,成為眾多行業轉型升級的關鍵力量。它宛如一座智能橋梁,一端緊密連接著各類物理設備,如傳感器、攝像頭、工業機器等,負責收集豐富的數據信息;另一端則
發表于 08-09 16:40
是德科技邀您相約2025開放計算創新技術大會
2025開放計算創新技術大會將于8月7日在北京國際飯店舉辦,圍繞“開放變革”主題,分享開放計算技術的創新與
Axelera AI:邊緣計算加速智能創新解決方案
。AxeleraAI憑借其卓越的AI加速解決方案,致力于協助企業快速部署高性能、低功耗的邊緣計算平臺,廣泛應用于智慧城市、智慧交通及工業檢測等領域。接下來說明AxeleraAI產品特色

AI芯片:加速人工智能計算的專用硬件引擎
人工智能(AI)的快速發展離不開高性能計算硬件的支持,而傳統CPU由于架構限制,難以高效處理AI任務中的大規模并行計算需求。因此,專為AI優
RK3588核心板在邊緣AI計算中的顛覆性優勢與場景落地
推理任務,需額外部署GPU加速卡,導致成本與功耗飆升。
擴展性受限:老舊接口(如USB 2.0、百兆網口)無法支持5G模組、高速存儲等現代外設,升級困難。
開發周期長:BSP適配不完善,跨平臺AI
發表于 04-15 10:48
英特爾借助開放生態系統,加速邊緣AI創新
的集成,這些解決方案精簡并加速了AI在邊緣的應用,包括在零售、制造、智慧城市、媒體和娛樂等行業的部署。 英特爾公司副總裁兼邊緣計算事業部總經
發表于 03-21 11:31
?333次閱讀

Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
低功耗特性。搭載 Renesas 獨有的 DRP-AI 加速器,支持 15 Sparse TOPS的 AI 計算能力,使其在計算機視覺、
發表于 03-19 17:54



 工商網監
工商網監
評論