 XGBoost號稱“比賽奪冠的必備大殺器”,橫掃機器學習競賽罕逢敵手
XGBoost號稱“比賽奪冠的必備大殺器”,橫掃機器學習競賽罕逢敵手

XGBoost號稱“比賽奪冠的必備大殺器”,橫掃機器學習競賽罕逢敵手,堪稱機器學習算法中的新女王!
在涉及非結構化數據(圖像、文本等)的預測問題中,人工神經網絡顯著優于所有其他算法或框架。但當涉及到中小型結構/表格數據時,基于決策樹的算法現在被認為是最佳方法。而基于決策樹算法中最驚艷的,非XGBoost莫屬了。
打過Kaggle、天池、DataCastle、Kesci等國內外數據競賽平臺之后,一定對XGBoost的威力印象深刻。XGBoost號稱“比賽奪冠的必備大殺器”,橫掃機器學習競賽罕逢敵手。最近甚至有一位大數據/機器學習主管被XGBoost在項目中的表現驚艷到,盛贊其為“機器學習算法中的新女王”!
XGBoost最初由陳天奇開發。陳天奇是華盛頓大學計算機系博士生,研究方向為大規模機器學習。他曾獲得KDD CUP 2012 Track 1第一名,并開發了SVDFeature,XGBoost,cxxnet等著名機器學習工具,是Distributed (Deep) Machine Learning Common的發起人之一。
XGBoost實現了高效、跨平臺、分布式gradient boosting (GBDT, GBRT or GBM) 算法的一個庫,可以下載安裝并應用于C++,Python,R,Julia,Java,Scala,Hadoop等。目前Github上超過15700星、6500個fork。
項目主頁:
https://XGBoost.ai/
XGBoost是什么
XGBoost全稱:eXtreme Gradient Boosting,是一種基于決策樹的集成機器學習算法,使用梯度上升框架,適用于分類和回歸問題。優點是速度快、效果好、能處理大規模數據、支持多種語言、支持自定義損失函數等,不足之處是因為僅僅推出了不足5年時間,需要進一步的實踐檢驗。
XGBoost選用了CART樹,數學公式表達XGBoost模型如下:
K是樹的數量,F表示所有可能的CART樹,f表示一棵具體的CART樹。這個模型由K棵CART樹組成。
模型的目標函數,如下所示:
XGBoost具有以下幾個特點:
靈活性:支持回歸、分類、排名和用戶定義函數
跨平臺:適用于Windows、Linux、macOS,以及多個云平臺
多語言:支持C++, Python, R, Java, Scala, Julia等
效果好:贏得許多數據科學和機器學習挑戰。用于多家公司的生產
云端分布式:支持多臺計算機上的分布式訓練,包括AWS、GCE、Azure和Yarn集群。可以與Flink、Spark和其他云數據流系統集成
下圖顯示了基于樹的算法的發展歷程:
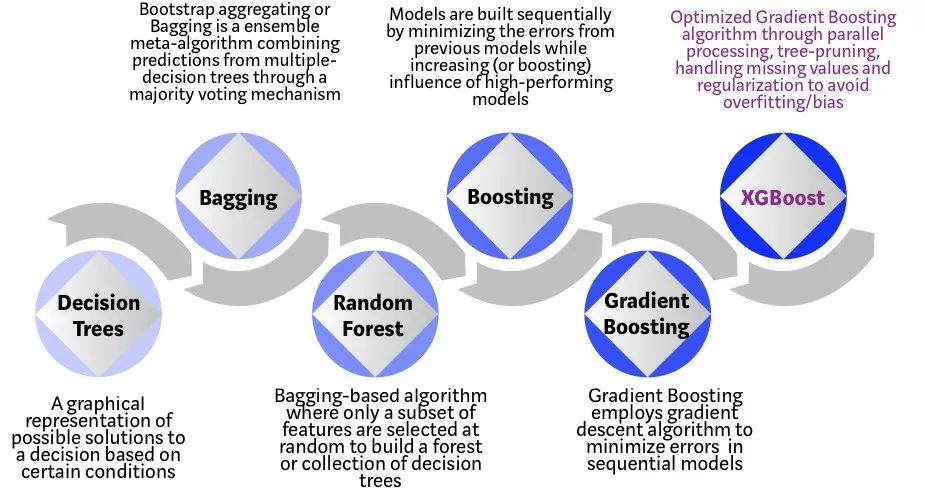
決策樹:由一個決策圖和可能的結果(包括資源成本和風險)組成, 用來創建到達目標的規劃。
Bagging:是一種集合元算法,通過多數投票機制將來自多決策樹的預測結合起來,也就是將弱分離器 f_i(x) 組合起來形成強分類器 F(x) 的一種方法
隨機森林:基于Bagging算法。隨機選擇一個包含多種特性的子集來構建一個森林,或者決策樹的集合
Boosting:通過最小化先前模型的誤差,同時增加高性能模型的影響,順序構建模型
梯度上升:對于似然函數,要求最大值,叫做梯度上升
XGBoost:極端梯度上升,XGBoost是一個優化的分布式梯度上升庫,旨在實現高效,靈活和跨平臺
為什么XGBoost能橫掃機器學習競賽平臺?
下圖是XGBoost與其它gradient boosting和bagged decision trees實現的效果比較,可以看出它比R, Python,Spark,H2O的基準配置都快。
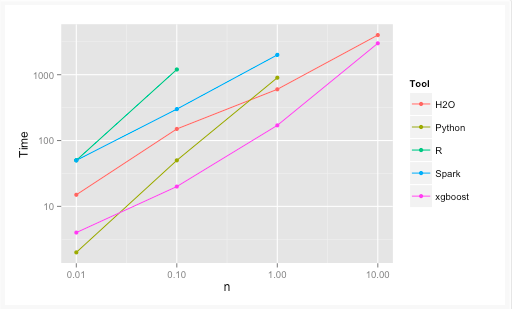
XGBoost和Gradient Boosting Machines(GBMs)都是集合樹方法,使用梯度下降架構來提升弱學習者(通常是CART)。而XGBoost通過系統優化和算法增強改進了基礎GBM框架,在系統優化和機器學習原理方面都進行了深入的拓展。
系統優化:
并行計算:
由于用于構建base learners的循環的可互換性,XGBoost可以使用并行計算實現來處理順序樹構建過程。
外部循環枚舉樹的葉節點,第二個內部循環來計算特征,這個對算力要求更高一些。這種循環嵌套限制了并行化,因為只要內部循環沒有完成,外部循環就無法啟動。
因此,為了改善運行時,就可以讓兩個循環在內部交換循環的順序。此開關通過抵消計算中的所有并行化開銷來提高算法性能。
Tree Pruning:
GBM框架內樹分裂的停止標準本質上是貪婪的,取決于分裂點的負損失標準。XGBoost首先使用'max_depth'參數而不是標準,然后開始向后修剪樹。這種“深度優先”方法顯著的提高了計算性能。
硬件優化:
該算法旨在有效利用硬件資源。這是通過在每個線程中分配內部緩沖區來存儲梯度統計信息來實現緩存感知來實現的。諸如“核外”計算等進一步增強功能可優化可用磁盤空間,同時處理不適合內存的大數據幀。
算法增強:
正則化:
它通過LASSO(L1)和Ridge(L2)正則化來懲罰更復雜的模型,以防止過擬合。
稀疏意識:
XGBoost根據訓練損失自動“學習”最佳缺失值并更有效地處理數據中不同類型的稀疏模式。
加權分位數草圖:
XGBoost采用分布式加權分位數草圖算法,有效地找到加權數據集中的最優分裂點。
交叉驗證:
該算法每次迭代時都帶有內置的交叉驗證方法,無需顯式編程此搜索,并可以指定單次運行所需的增強迭代的確切數量。
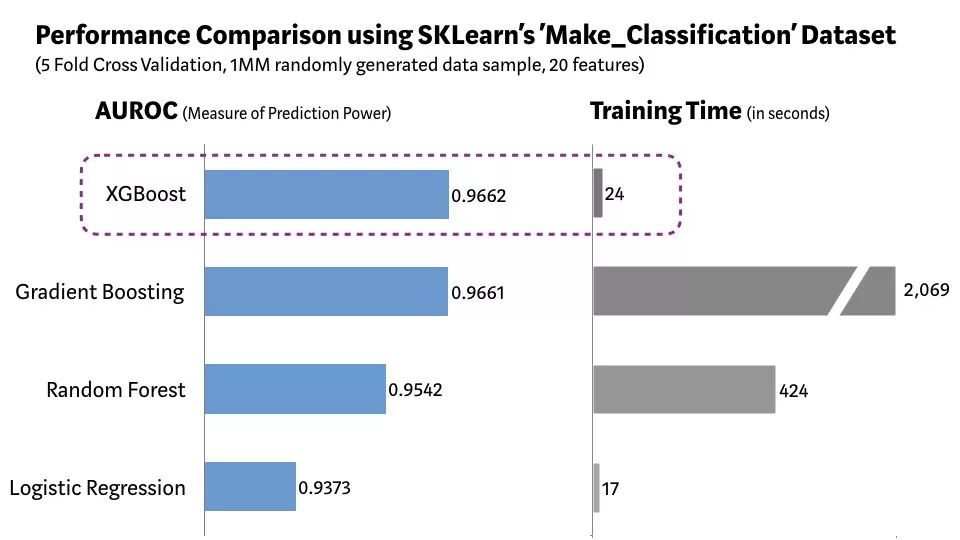
為了測試XGBoost到底有多快,可以通過Scikit-learn的'Make_Classification'數據包,創建一個包含20個特征(2個信息和2個冗余)的100萬個數據點的隨機樣本。
下圖為邏輯回歸,隨機森林,標準梯度提升和XGBoost效率對比:
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107849 -
機器學習
+關注
關注
66文章
8554瀏覽量
136986 -
大數據
+關注
關注
64文章
9065瀏覽量
143784
原文標題:陳天奇做的XGBoost為什么能橫掃機器學習競賽平臺?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
太燃了!人形機器人1500米比賽,這家奪冠!更有機器人全程自主奔跑

第21屆全國大學生智能汽車競賽龍芯“走馬觀碑”組首場直播培訓
機器學習和深度學習中需避免的 7 個常見錯誤與局限性

廣和通斬獲具身智能家務機器人黑客松競賽二等獎
EtherCAT?技術前瞻:人形機器人通信的新選擇!

TDK傳感器技術助力實現標槍比賽數據的可視化
機器人競技幕后:磁傳感器芯片激活 “精準感知力”
第六屆TE Connectivity AI Cup全球競賽圓滿收官
FPGA在機器學習中的具體應用
超燃!人形機器人格斗賽,這隊奪冠!

全球首個人形機器人半馬開跑,“天工”奪冠彰顯科技新高度

從人形機器人馬拉松開跑看機器人“核心大小腦”的方案優勢
**【技術干貨】Nordic nRF54系列芯片:傳感器數據采集與AI機器學習的完美結合**
工業機器人設計工程師必備指南免費下載



 工商網監
工商網監
評論