 Github上放出了只需4-8塊GPU就能訓練的“改進版”BigGAN模型代碼
Github上放出了只需4-8塊GPU就能訓練的“改進版”BigGAN模型代碼

機器學習模型訓練成本往往令普通人倍感頭疼,動輒幾十上百塊泰坦,別說買,就是租都肉疼。近日,BigGAN作者之一在Github上放出了只需4-8塊GPU就能訓練的“改進版”BigGAN模型代碼,可以說是窮人的福音。新模型使用PyTorch實現。
機器學習模型訓練是一個耗時費力的過程,而且隨著人們對模型性能要求的提升,訓練模型需要的計算力正以驚人的速度增長,堆疊高性能GPU進行數據訓練幾乎是唯一選擇,動輒幾十塊上百塊的泰坦,搞的地主家也沒有余糧。
BigGAN效果拔群,但訓練成本同樣讓人望而卻步,想自己搞?先摸摸錢包再說。
現在,BigGAN原作者之一Andrew Brock在Github上放出了只需4-8塊GPU就能訓練的新版BigGAN,想窮人之所想,急窮人之所急,可以說是非常親民了。新模型使用的是PyTorch,而不是TF。
下面一起看看這個新模型的具體介紹,以下內容來自Github上的簡介。
本資源包含由Andrew Brock,JeffDonahue和Karen Simonyan進行的大規模GAN高保真自然圖像合成訓練的BigGAN,只需4-8塊 GPU的訓練代碼。
本段代碼由Andy Brock和Alex Andonian編寫。
運行環境和條件
PyTorch 1.0.1
tqdm,numpy,scipy和h5py
ImageNet訓練集
首先,可以選擇準備目標數據集的預處理HDF5版本,以實現更快的輸入輸出。之后需要計算FID所需的Inception時刻。這些都可以通過修改和運行以下代碼來完成
shscripts / utils / prepare_data.sh
默認情況下,ImageNet訓練集被下載到此目錄中的根文件夾中,并將以128x128像素分辨率準備緩存的HDF5。
在scripts文件夾中,有多個bash腳本可以訓練具有不同批量大小的BigGAN。假設您無法訪問完整的TPU pod,因此通過梯度累積(在多個小批量下進行梯度平均,并且僅在N次累積后執行優化程序步驟),以此形式表示大批量。
默認情況下,可以使用launch_BigGAN_bs256x8.sh腳本訓練一個全尺寸的BigGAN模型,批大小為256和8個梯度累積,總批量為2048。在8張V100上進行全精度訓練(無張量),訓練需要15天,期間共進行約150k次迭代。
首先需要確定設置可以支持的最大批量大小。這里提供的預訓練模型是在8個V100上(每個顯存16GB )上訓練的,這個配置可以支持比默認使用的B1S256稍多一些的載荷。一旦確定了這一點,就應該修改腳本,使批大小乘以梯度累積的數量等于所需的總批量大小(BigGAN默認為2048)。
另外,此腳本使用--load_in_memarg,將整個(最大支持64GB)的I128.hdf5文件加載到RAM中,以加快數據的加載速度。如果沒有足夠的RAM做硬件支持(可能需要96GB以上的RAM),請刪除此參數。
度量標準和抽樣
在訓練期間,腳本將輸出帶有訓練指標和測試指標的日志,同時保存模型權重和優化程序參數的多個副本(前者保存最近的2個,后者保存5個最高得分),并且每次保存權重時將生成樣本和插值。 logs文件夾包含處理這些日志的腳本,并使用MATLAB繪制結果。
訓練之后,可以使用sample.py生成其他樣本和插值,使用不同的截斷值,批量大小,站立統計累積次數等進行測試。有關示例,請參閱sample_BigGAN_bs256x8.sh腳本。
默認情況下,所有內容都保存在weights/samples/logs/data文件夾中,這些文件夾設置與此repo位于同一文件夾中。可以使用--base_root參數將所有這些指向不同的基本文件夾,或者使用各自的參數(例如--logs_root)選擇每個基礎文件夾的特定位置。
此代碼中包含了運行BigGAN-deep的腳本,但還沒有完全訓練使用它們的模型,因此用戶可以視作這些模型尚未測試過。此外,我代碼中還包括在CIFAR上運行模型的腳本,以及在ImageNet上運行SA-GAN(包括EMA)和SN-GAN的腳本。
SA-GAN代碼假設用戶配置在4張TitanX(或等同于該配置的GPU RAM),并且將以批量大小為128以及2個梯度累積運行。
關于初始度量標準的重要說明
本資源使用PyTorch內置的初始網絡來計算IS和FID分數。這些分數與使用Tensorflow官方初始代碼獲得的分數不同,僅用于監控目的。使用--sample_npz參數在模型上運行sample.py,然后運行inception_tf13來計算實際的TensorFlow IS。請注意,需要安裝TensorFlow 1.3或更早版本,因為1.4或更高版本會破壞原始的IS代碼。
預訓練模型
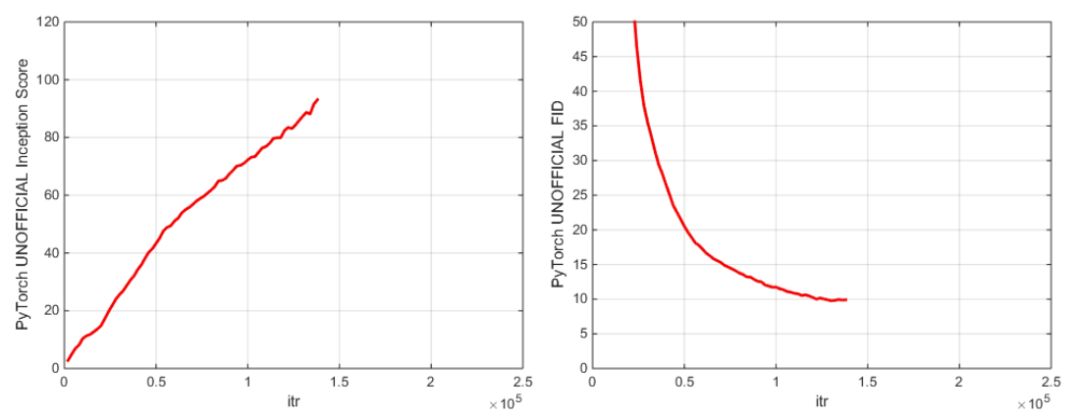
PyTorch初始分數和FID分數
我們引入了兩個預訓練模型檢查點(使用G,D,G的EMA副本,優化器和狀態dict):
主要檢查點是在 128x128 ImageNet 圖像上訓練的 BigGAN,該模型使用 BS256 和 8 梯度累積,并在崩潰前實現,其 TF Inception Score 為 97.35 +/- 1.79,
詳見:
https://drive.google.com/open?id=1nAle7FCVFZdix2—ks0r5JBkFnKw8ctW
第一個模型(100k G iters)的早期檢查點,性能更高,在崩潰之前實現,可能更容易微調。
詳見:
https://drive.google.com/open?id=1dmZrcVJUAWkPBGza_XgswSuT-UODXZcO。
另外,使用Places-365數據集的預訓練模型即將推出。
此repo還包含用于將原始TF HubBigGAN 生成器權重的PyTorch的移植腳本。有關更多詳細信息,請參閱TFHub文件夾中的腳本。
使用自己的數據集或創建新的訓練函數微調模型
如果想恢復中斷訓練或微調預訓練模型,請在運行相同的啟動腳本,添加--resume參數。實驗名稱是由訓練配置自動生成的,但如果希望使用修改后的優化器設置微調模型,可以使用--experiment_namearg進行文件名的覆蓋。
要準備自己的數據集,需要將其添加到datasets.py并修改utils.py中的convenience dicts,以獲得數據集的相應元數據。在prepare_data.sh中重復此過程(也可以選擇生成HDF5預處理副本,并計算FID的Inception Moments)。
默認情況下,訓練腳本將保存初始分數最高的前5個檢查點。對于ImageNet以外的數據集,初始分數可能是一種非常差的質量標準,可以使用--which_bestFID來代替。
要使用自己的訓練函數(如訓練BigVAE):修改train_fns.GAN_training_function或在if config['which_train_fn'] =='GAN'之后添加新的訓練函數。
本模型的主要亮點
本資源庫提供完整的訓練和指標日志以供參考。重現論文過程中最困難的事情之一就是檢查訓練早期的記錄日志是否規整,特別是在訓練時間長達數周的情況下。希望這將有助于未來的工作。
本資源庫包括一個加速的FID計算 - 原始的scipy版本可能需要超過10分鐘來計算矩陣sqrt,此版本使用加速的PyTorch版本,計算時間不到1秒。
本資源用了一種加速、低內存消耗的正交寄存器實現。默認情況下,只計算最大奇異值(譜范數),但本段代碼通過 —num_G_SVs 參數支持了更多 SV 的計算。
本模型與原始BigGAN之間的主要區別
我們使用來自SA-GAN的優化器設置(G_lr= 1e-4,D_lr = 4e-4,num_D_steps= 1,與BigGAN的設置不同(G_lr = 5e-5,D_lr = 2e-5,num_D_steps = 2)。雖然這樣犧牲了些許性能,但這是削減訓練時間的第一步。
默認情況下,本資源不使用Cross-Replica BatchNorm(又名Synced BatchNorm)。本資源嘗試的兩種變體與內置的BatchNorm具有略微不同的梯度(盡管是相同的前向傳遞),可以滿足訓練要求。
梯度累積意味著需要更頻繁地更新SV估計值和BN統計量(頻度增加了8倍)。這意味著BN統計數據更接近于常設統計數據,而且奇異值估計往往更準確。因此,在測試模式下默認使用G來衡量指標(使用BatchNorm運行統計估算,而不是像文件中那樣計算常設統計數據)。
我們仍然支持常設統計信息(具體見sample.sh腳本)。這也可能導致早期累積的梯度變得過時,但在實踐中這已經不再是個問題。
目前給出的預訓練模型未經過正交正則化訓練。似乎增加了模型由于截斷變得不可修復的可能性,但本資源庫中給出特定模型似乎格外好運,沒有碰到這種情況。不過,我們還是提供兩個經過高度優化(快速和最小內存消耗)的正交寄存器實現,直接計算正交寄存器梯度。
Github資源地址:
https://github.com/ajbrock/BigGAN-PyTorch
-
gpu
+關注
關注
28文章
5194瀏覽量
135431 -
機器學習
+關注
關注
66文章
8553瀏覽量
136931 -
GitHub
+關注
關注
3文章
488瀏覽量
18662
原文標題:學生黨福音!僅4個GPU打造自己的BigGAN,PyTorch代碼已開源
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
從訓練到推理:大模型算力需求的新拐點已至

RA8P1部署ai模型指南:從訓練模型到部署?|?本周六

在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
AI智能大模型,你身邊的最好用的辦公提效小能手
使用ROCm?優化并部署YOLOv8模型
Arm神經技術是業界首創在 Arm GPU 上增添專用神經加速器的技術,移動設備上實現PC級別的AI圖形性能
aicube的n卡gpu索引該如何添加?
為什么無法在GPU上使用INT8 和 INT4量化模型獲得輸出?
代碼革命的先鋒:aiXcoder-7B模型介紹

請問如何在imx8mplus上部署和運行YOLOv5訓練的模型?
摩爾線程GPU原生FP8計算助力AI訓練




 工商網監
工商網監
評論