 網絡爬蟲是否合法
網絡爬蟲是否合法

網絡爬蟲是否合法
網絡爬蟲在大多數情況中都不違法,其實我們生活中幾乎每天都在爬蟲應用,如百度,你在百度中搜索到的內容幾乎都是爬蟲采集下來的(百度自營的產品除外,如百度知道、百科等),所以網絡爬蟲作為一門技術,技術本身是不違法的,且在大多數情況下你都可以放心大膽的使用爬蟲技術。
爬蟲作為一種計算機技術就決定了它的中立性,因此爬蟲本身在法律上并不被禁止,但是利用爬蟲技術獲取數據這一行為是具有違法甚至是犯罪的風險的。所謂具體問題具體分析,正如水果刀本身在法律上并不被禁止使用,但是用來捅人,就不被法律所容忍了。
或者我們可以這么理解:爬蟲是用來批量獲得網頁上的公開信息的,也就是前端顯示的數據信息。因此,既然本身就是公開信息,其實就像瀏覽器一樣,瀏覽器解析并顯示了頁面內容,爬蟲也是一樣,只不過爬蟲會批量下載而已,所以是合法的。不合法的情況就是配合爬蟲,利用黑客技術攻擊網站后臺,竊取后臺數據(比如用戶數據等)。
舉個例子:像谷歌這樣的搜索引擎爬蟲,每隔幾天對全網的網頁掃一遍,供大家查閱,各個被掃的網站大都很開心。這種就被定義為“善意爬蟲”。但是像搶票軟件這樣的爬蟲,對著12306每秒鐘恨不得擼幾萬次,鐵總并不覺得很開心,這種就被定義為“惡意爬蟲”。
如何在使用爬蟲時避免違法犯罪
1、嚴格遵守網站設置的robots協議;
2、在規避反爬蟲措施的同時,需要優化自己的代碼,避免干擾被訪問網站的正常運行;
3、在設置抓取策略時,應注意編碼抓取視頻、音樂等可能構成作品的數據,或者針對某些特定網站批量抓取其中的用戶生成內容;
4、在使用、傳播抓取到的信息時,應審查所抓取的內容,如發現屬于用戶的個人信息、隱私或者他人的商業秘密的,應及時停止并刪除。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
網絡爬蟲
+關注
關注
1文章
52瀏覽量
9192 -
爬蟲
+關注
關注
0文章
87瀏覽量
8157
發布評論請先 登錄
相關推薦
熱點推薦
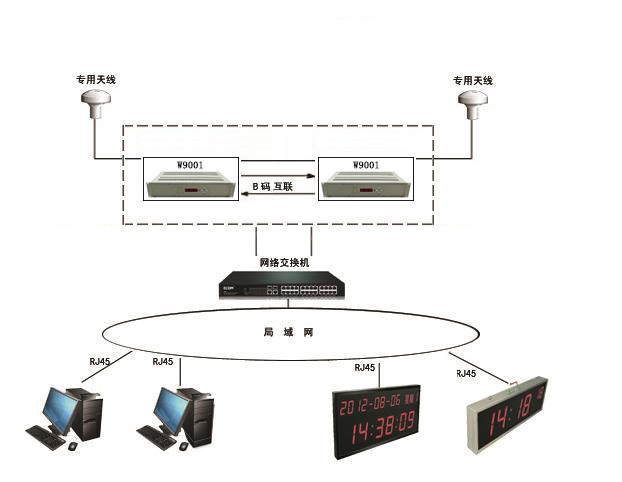
北斗網絡時間服務器:從“精準心跳”到自主可控的技術實踐
北斗網絡時間服務器早已不再是一個簡單的“時鐘盒子”。它正如同為數字世界注入“精準心跳”的起搏器,支撐著從智慧航道的數據邏輯正確,到電網故障的毫秒級定位,再到金融交易的合法時間戳認證 。
京東關鍵詞API接口獲取
你想要獲取京東關鍵詞相關的 API 接口,以此替代傳統爬蟲,更合規、穩定地獲取商品列表等信息,我會先講解 官方合規的 API 獲取與使用方式 (推薦),再說明非官方接口的情況(僅供學習),并給出
京東關鍵詞搜索商品列表的Python爬蟲實戰
京東關鍵詞搜索商品列表 Python 爬蟲實戰 你想要實現京東關鍵詞搜索商品的爬蟲,我會從 合規聲明、環境準備、頁面分析、代碼實現、反爬優化 五個方面展開,幫助你完成實戰項目。 一、前置聲明(重要
你的企業網絡,是否真的“跟得上”數字化轉型的腳步?
前言在數字化轉型的浪潮中,您的企業是否也面臨這樣的網絡困境:分公司訪問云端系統頻繁卡頓,視頻會議屢屢中斷成為溝通的常態;跨地域數據傳輸緩慢,嚴重影響項目交付進度;盡管已投入大量成本部署多條專線,網絡

# 深度解析:爬蟲技術獲取淘寶商品詳情并封裝為API的全流程應用
需求。本文將深入探討如何借助爬蟲技術實現淘寶商品詳情的獲取,并將其高效封裝為API。 一、爬蟲技術核心原理與工具 1.1 爬蟲運行機制 網絡爬蟲
電能質量在線監測裝置的遠程實時波形查看是否會受到網絡延遲的影響?
電能質量在線監測裝置的遠程實時波形查看 一定會受到網絡延遲的影響 ,且延遲會直接體現在波形顯示的 “滯后性、連貫性、同步性” 上 —— 網絡延遲越大,遠程看到的波形與現場實際波形的偏差越明顯,甚至
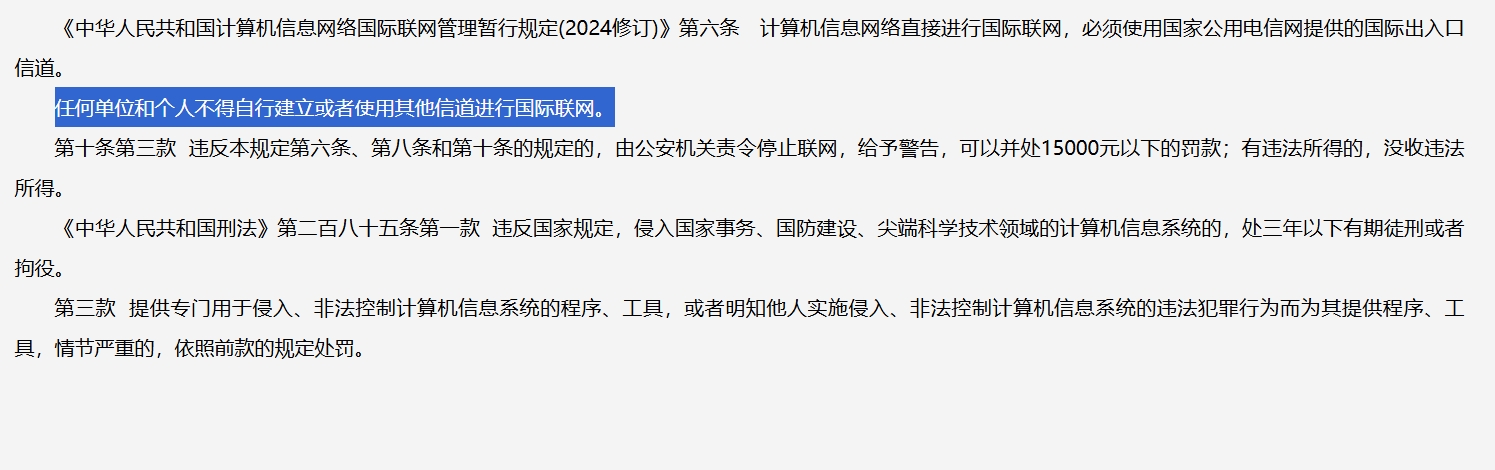
SD-WAN跨境專線是什么?跨境網絡專線合法嗎?
問題。本文將為您全面解析SD-WAN跨境專線的合法性,并介紹合法的跨境網絡專線方案,幫助企業安全、合規地開展國際業務。 一、關于跨境網絡的合法
校準電能質量在線監測裝置時,如何判斷標準源的輸出是否準確?
在校準電能質量在線監測裝置時,標準源的輸出準確性是 “溯源根基”—— 若標準源自身存在偏差,會直接導致被校準裝置的誤差判斷失效。需通過 **“溯源合法性驗證→靜態參數校準→動態參數核驗→環境與負載

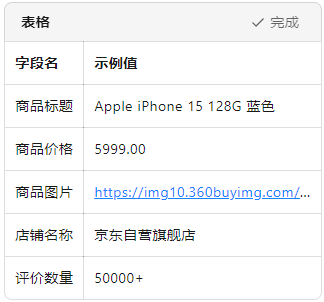
從 0 到 1:用 PHP 爬蟲優雅地拿下京東商品詳情
PHP 語言 實現一個 可運行的京東商品爬蟲 ,不僅能抓取商品標題、價格、圖片、評價數,還能應對常見的反爬策略。全文附完整代碼, 復制粘貼即可運行 。 一、為什么選擇 PHP 做爬蟲? 雖然 Python 是爬蟲界的“老大哥”
Nginx限流與防爬蟲配置方案
在互聯網業務快速發展的今天,網站面臨著各種流量沖擊和惡意爬蟲的威脅。作為運維工程師,我們需要在保證正常用戶訪問的同時,有效防范惡意流量和爬蟲攻擊。本文將深入探討基于Nginx的限流與防爬蟲解決方案,從原理到實踐,為大家提供一套完
看不見的安全防線:信而泰儀表如何驗證零信任有效性
是否經過認證;
設備令牌:用于校驗用戶是否使用合法的客戶端訪問應用;
應用令牌:用于校驗是用戶是否有應用的訪問權限。
測試拓撲:
場景 1: SDP控制器下發帶源IP的可信資產,DU
發表于 09-09 15:33
網絡光纖出問題怎么辦
常亮表示無光信號輸入,需檢查光纖線路。 如果發現指示燈異常,可以嘗試重啟設備,看是否能恢復網絡連接。 檢查光纖接口: 檢查光貓、路由器、光纖跳線(尾纖)的接口是否松動或臟污。 使用無塵布清潔接口,確保連接良好。 檢查光纖彎曲度
ISO/SAE 21434標準解讀 DEKRA德凱解析ISO/SAE 21434汽車網絡安全產品
? ? ? 隨著智能網聯汽車的普及,車輛網絡安全已成為行業關注的關鍵議題。全球范圍內,合法合規和供應鏈安全要求不斷升級。ISO/SAE 21434作為汽車電子電氣(E/E)系統網絡安全管理的權威
穩定、高效、智能:蜂鳥IP如何為技術玩家提供可靠動態IP服務?
在當今數字化時代,網絡環境的穩定性和靈活性已成為技術愛好者和專業人士關注的重點。無論是爬蟲開發、網絡安全測試,還是多地域網絡訪問需求,一個可靠的動態IP服務能顯著提升工作效率,避免因I



 工商網監
工商網監
評論