 網絡爬蟲的基本工作流程
網絡爬蟲的基本工作流程

網絡爬蟲的基本工作流程
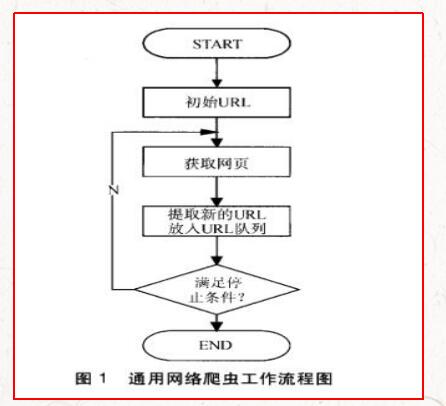
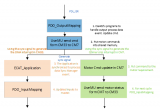
通用網絡爬蟲根據預先設定的一個或若干初始種子URL開始,以此獲得初始網頁上的URL列表,在爬行過程中不斷從URL隊列中獲一個的URL,進而訪問并下載該頁面。頁面下載后頁面解析器去掉頁面上的HTML標記后得到頁面內容,將摘要、URL等信息保存到Web數據庫中,同時抽取當前頁面上新的URL,保存到URL隊列,直到滿足系統停止條件。其工作流程如圖1所示。
主題爬蟲工作流程
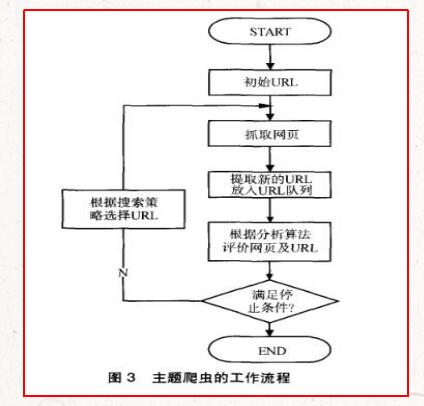
主題爬蟲需要根據一定的網頁分析算法,過濾掉與主題無關的鏈接,保留有用的鏈接并將其放入等待抓取的URL隊列。然后,它會根據一定的搜索策略從待抓取的隊列中選擇下一個要抓取的URL,并重復上述過程,直到滿足系統停止條件為止。所有被抓取網頁都會被系統存儲,經過一定的分析、過濾,然后建立索引,以便用戶查詢和檢索;這一過程所得到的分析結果可以對以后的抓取過程提供反饋和指導。其工作流程如圖3所示。
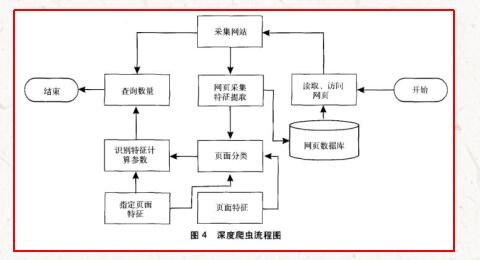
深度網絡爬蟲工作流程
1994年Dr.jillEllsworth提出DeepWeb(深層頁面)的概念,即DeepWeb是指普通搜索引擎難以發現的信息內容的Web頁面¨。DeepWeb中的信息量比普通的網頁信息量多,而且質量更高。但是普通的搜索引擎由于技術限制而搜集不到這些高質量、高權威的信息。這些信息通常隱藏在深度Web頁面的大型動態數據庫中,涉及數據集成、中文語義識別等諸多領域。如此龐大的信息資源如果沒有合理的、高效的方法去獲取,將是巨大的損失。因此,對于深度網爬行技術的研究具有極為重大的現實意義和理論價值。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
網絡爬蟲
+關注
關注
1文章
52瀏覽量
9157 -
爬蟲
+關注
關注
0文章
87瀏覽量
8091
發布評論請先 登錄
相關推薦
熱點推薦
是德科技與三星攜手英偉達展示端到端AI-RAN驗證工作流程
是德科技(NYSE: KEYS )與三星電子宣布,會在巴塞羅那舉行的2026年世界移動通信大會(MWC 2026)上,與英偉達聯合演示端到端人工智能無線接入網絡(AI-RAN)測試與驗證工作流程。該
虛幻引擎5在建筑可視化中的應用:趨勢、挑戰與基于Perforce P4的工作流程
UE5正在重塑建筑可視化:實時交互、AI輔助、BIM聯動......技術紅利已來,工作流卻拖了后腿?這篇干貨解析了趨勢和痛點,更揭秘了如何用Perforce P4打造高效的UE5工作流。

安寶特方案丨AI 識別遇上 AR 工作流,PCB 質控迎來新的「黃金時代」
差異和流程不一致長期制約良率,而基于AR標準化工作流+AI識別的應用,正讓所有工位實現“無差別準確執行”。01破解人工質檢困境:讓標準化操作如臨現場Arbigtec

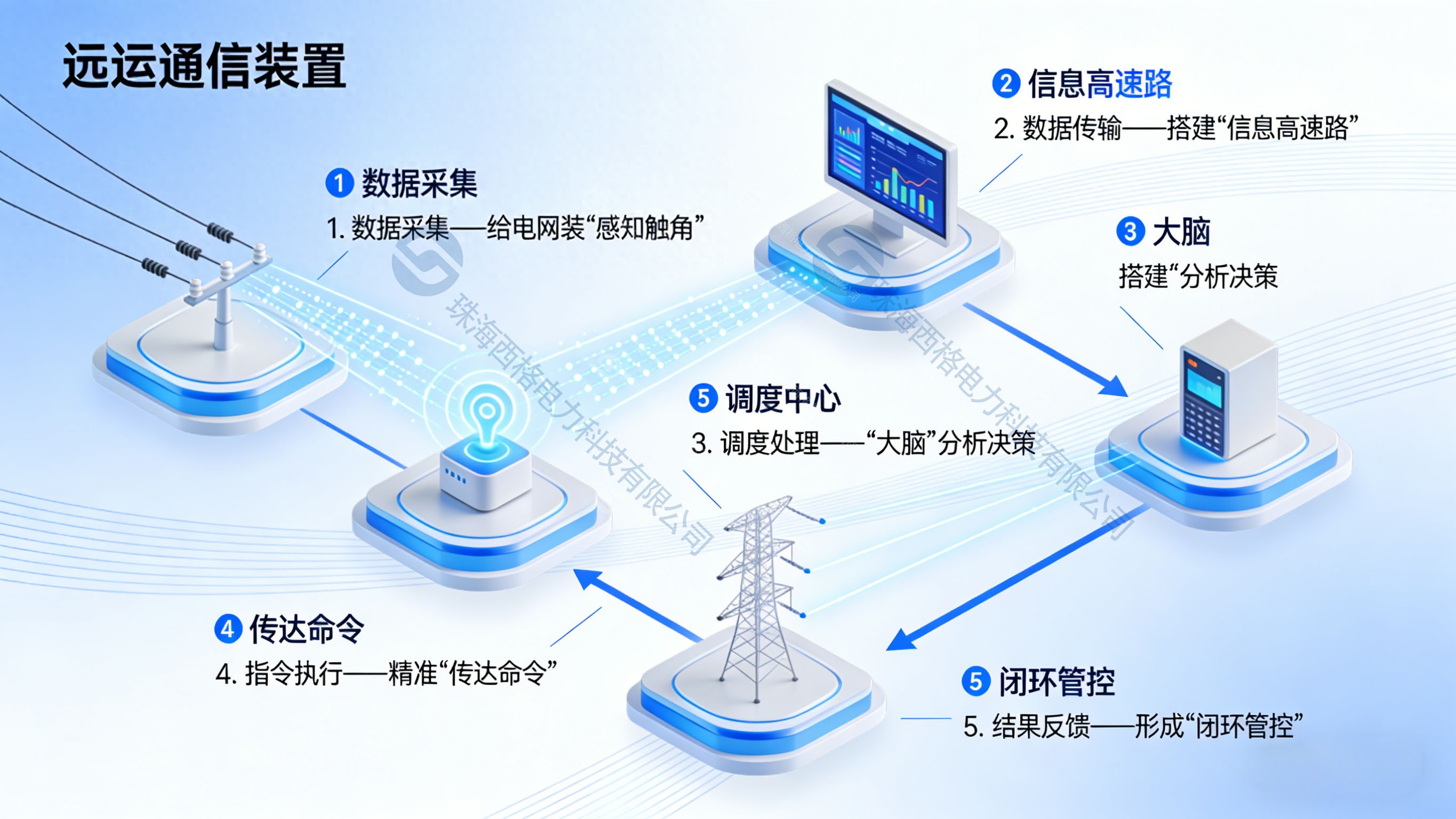
一張圖看懂遠動通信裝置的工作流程
遠動通信裝置作為電網的“千里眼”“順風耳”,核心是完成“現場狀態上傳”與“調度指令下達”的閉環協作。它的工作流程看似復雜,實則可拆解為“數據采集—數據傳輸—調度處理—指令執行—結果反饋”五大核心步驟
芯片ATE測試詳解:揭秘芯片測試機臺的工作流程
ATE(自動測試設備)是芯片出廠前的關鍵“守門人”,負責篩選合格品。其工作流程分為測試程序生成載入、參數測量與功能測試(含直流、交流參數及功能測試)、分類分檔與數據分析三階段,形成品質閉環。為平衡

# 深度解析:爬蟲技術獲取淘寶商品詳情并封裝為API的全流程應用
需求。本文將深入探討如何借助爬蟲技術實現淘寶商品詳情的獲取,并將其高效封裝為API。 一、爬蟲技術核心原理與工具 1.1 爬蟲運行機制 網絡爬蟲
鋰電池組裝生產線——鋰電池電芯分選與組裝段工作流程
該段設備實現了從單個電芯到電池組預備組裝的全流程自動化作業,其核心工作流程環環相扣,體現了高度的自動化與系統性。 流程始于人工上料,操作員將檢測合格的電芯批量放入面墊機的料斗中,為自動化線的啟動做好
強強合作 西門子與日月光合作開發 VIPack 先進封裝平臺工作流程
平臺開發基于 3Dblox 的工作流程。雙方目前已經合作完成三項 VIPack 技術的 3Dblox 工作流程驗證,包括扇出型基板上芯片封裝(FOCoS)、扇出型基板上芯片橋接
ADI Power Studio工作流程與工具概述
、直觀的工作流程,利用準確的模型來仿真實際性能,并自動生成關鍵的物料清單和報告等內容,幫助工程團隊更早做出更優決策。
恩智浦i.MX RT1180跨界MCU驅動EtherCAT的工作流程
上周的分享已經介紹了整個參考設計的概況和相關硬件資源。那么,本次會從軟件工程角度進行分享。首先來了解EtherCAT Slave工作流程。
Nginx限流與防爬蟲配置方案
在互聯網業務快速發展的今天,網站面臨著各種流量沖擊和惡意爬蟲的威脅。作為運維工程師,我們需要在保證正常用戶訪問的同時,有效防范惡意流量和爬蟲攻擊。本文將深入探討基于Nginx的限流與防爬蟲解決方案,從原理到實踐,為大家提供一套完

VirtualLab Fusion應用:將光耦合入單模光纖的最佳工作距離
光斑計算初始工作距離
在光線光學焦點距離處的光場評估
通過參數掃描確定最佳工作距離
在最佳距離處的場評估
工作流程步驟基礎
工作流程步驟基礎
發表于 06-03 08:44
爬蟲數據獲取實戰指南:從入門到高效采集
爬蟲數據獲取實戰指南:從入門到高效采集 ? ? 在數字化浪潮中,數據已成為驅動商業增長的核心引擎。無論是市場趨勢洞察、競品動態追蹤,還是用戶行為分析,爬蟲技術都能助你快速捕獲目標信息。然而,如何既



 工商網監
工商網監
評論