 對scikit-learn和numpy生成數據樣本的方法做一個總結
對scikit-learn和numpy生成數據樣本的方法做一個總結

????在學習機器學習算法的過程中,我們經常需要數據來驗證算法,調試參數。但是找到一組十分合適某種特定算法類型的數據樣本卻不那么容易。還好numpy, scikit-learn都提供了隨機數據生成的功能,我們可以自己生成適合某一種模型的數據,用隨機數據來做清洗,歸一化,轉換,然后選擇模型與算法做擬合和預測。
1. numpy隨機數據生成API????
numpy比較適合用來生產一些簡單的抽樣數據。API都在random類中,常見的API有:
1)rand(d0,d1,...,dn) 用來生成d0×d1×...dn維的數組 。數組的值在[0,1)之間
例如:np.random.rand(3,2,2),輸出如下3×2×2的數組
array([[[ 0.49042678, 0.60643763], [ 0.18370487, 0.10836908]], [[ 0.38269728, 0.66130293], [ 0.5775944 , 0.52354981]],
[[ 0.71705929, 0.89453574], [ 0.36245334, 0.37545211]]])
2)randn((d0,d1,...,dn)也是用來生成d0xd1x...dn維的數組。不過數組的值服從N(0,1)的標準正態分布。
例如:np.random.randn(3,2),輸出如下3x2的數組,這些值是N(0,1)的抽樣數據。
array([[-0.5889483 , -0.34054626], [-2.03094528, -0.21205145], [-0.20804811, -0.97289898]])
如果需要服從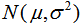 的正態分布,只需要在randn上每個生成的值x上做變換
的正態分布,只需要在randn上每個生成的值x上做變換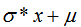 即可 。
即可 。
例如:2*np.random.randn(3,2) + 1,輸出如下3x2的數組,這些值是N(1,4)的抽樣數據。
array([[ 2.32910328, -0.677016 ], [-0.09049511, 1.04687598], [ 2.13493001, 3.30025852]])
3)randint(low[,high,size]),生成隨機的大小為size的數據,size可以為整數,為矩陣維數,或者張量的維數。值位于半開區間 [low, high)。
例如:np.random.randint(3, size=[2,3,4])返回維數維2x3x4的數據,取值范圍為最大值為3的整數。
array([[[2, 1, 2, 1],[0, 1, 2, 1],[2, 1, 0, 2]],[[0, 1, 0, 0],[1, 1, 2, 1],[1, 0, 1, 2]]])
再比如: np.random.randint(3, 6, size=[2,3]) 返回維數為2x3的數據。取值范圍為[3,6).
array([[4, 5, 3], [3, 4, 5]])
4)random_integers(low[,high,size]),和上面的randint類似,區別在于取值范圍是閉區間[low, high]。
5)random_sample([size]),返回隨機的浮點數,在半開區間 [0.0, 1.0)。如果是其他區間[a,b),可以加以轉換(b - a) * random_sample([size]) + a
例如: (5-2)*np.random.random_sample(3)+2 返回[2,5)之間的3個隨機數。
array([ 2.87037573, 4.33790491, 2.1662832 ])
2. scikit-learn隨機數據生成API介紹
scikit-learn生成隨機數據的API都在datasets類之中,和numpy比起來,可以用來生成適合特定機器學習模型的數據。常用的API有:
1) 用make_regression生成回歸模型的數據
2) 用make_hastie_10_2,make_classification或者make_multilabel_classification生成分類模型數據
3) 用make_blobs生成聚類模型數據
4) 用make_gaussian_quantiles生成分組多維正態分布的數據
3. scikit-learn隨機數據生成實例
3.1回歸模型隨機數據
這里我們使用make_regression生成回歸模型數據。幾個關鍵參數有n_samples(生成樣本數), n_features(樣本特征數),noise(樣本隨機噪音)和coef(是否返回回歸系數)。例子代碼如下:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets.samples_generator import make_regression # X為樣本特征,y為樣本輸出, coef為回歸系數,共1000個樣本,每個樣本1個特征X, y, coef =make_regression(n_samples=1000, n_features=1,noise=10, coef=True)# 畫圖plt.scatter(X, y, color='black')plt.plot(X, X*coef, color='blue',linewidth=3)plt.xticks(())plt.yticks(())plt.show()
輸出的圖如下:

3.2 分類模型隨機數據
這里我們用make_classification生成三元分類模型數據。幾個關鍵參數有n_samples(生成樣本數), n_features(樣本特征數), n_redundant(冗余特征數)和n_classes(輸出的類別數),例子代碼如下:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets.samples_generator import make_classification # X1為樣本特征,Y1為樣本類別輸出, 共400個樣本,每個樣本2個特征,輸出有3個類別,沒有冗余特征,每個類別一個簇X1, Y1 = make_classification(n_samples=400, n_features=2, n_redundant=0, n_clusters_per_class=1, n_classes=3)plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)plt.show()
輸出的圖如下:
3.3 聚類模型隨機數據
這里我們用make_blobs生成聚類模型數據。幾個關鍵參數有n_samples(生成樣本數), n_features(樣本特征數),centers(簇中心的個數或者自定義的簇中心) 和 cluster_std(簇數據方差,代表簇的聚合程度)。例子如下:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets.samples_generator import make_blobs # X為樣本特征,Y為樣本簇類別, 共1000個樣本,每個樣本2個特征,共3個簇,簇中心在[-1,-1], [1,1], [2,2], 簇方差分別為[0.4, 0.5, 0.2]X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [1,1], [2,2]], cluster_std=[0.4, 0.5, 0.2])plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)plt.show()
輸出的圖如下:
3.4 分組正態分布混合數據
我們用make_gaussian_quantiles生成分組多維正態分布的數據。幾個關鍵參數有n_samples(生成樣本數),n_features(正態分布的維數),mean(特征均值),cov(樣本協方差的系數), n_classes(數據在正態分布中按分位數分配的組數)。 例子如下:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import make_gaussian_quantiles#生成2維正態分布,生成的數據按分位數分成3組,1000個樣本,2個樣本特征均值為1和2,協方差系數為2X1, Y1 = make_gaussian_quantiles(n_samples=1000, n_features=2, n_classes=3, mean=[1,2],cov=2)plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
輸出圖如下:
以上就是生產隨機數據的一個總結,希望可以幫到學習機器學習算法的朋友們。
-
機器學習
+關注
關注
66文章
8553瀏覽量
136928
原文標題:機器學習算法的隨機數據生成
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
算法工程師需要具備哪些技能?
CIE全國RISC-V創新應用大賽 人臉識別系統介紹與移植
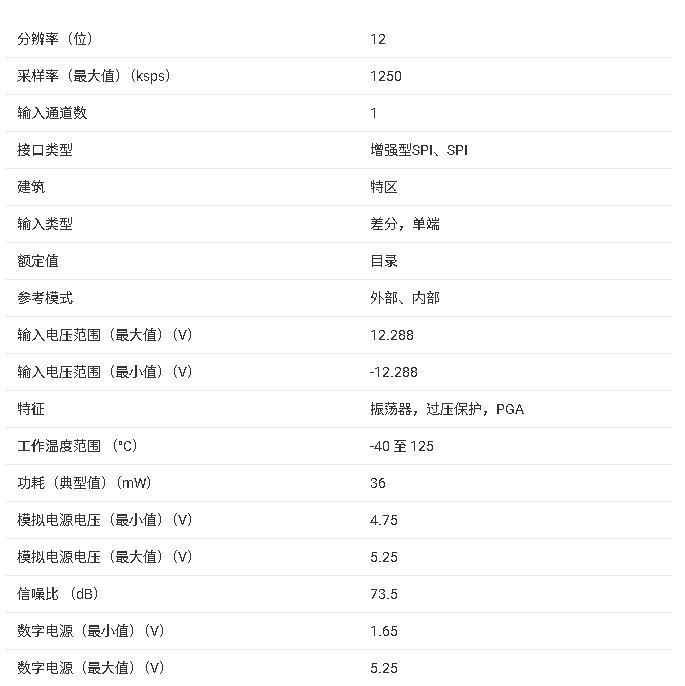
?ADS8661W 數據手冊總結
NVIDIA GR00T-Dreams助力光輪智能革新合成數據
如何使用WaveDac8設置一個簡單的數據采集系統,以生成不同持續時間的脈沖?
破解數據瓶頸:智能汽車合成數據架構與應用實踐

破解數據瓶頸:智能汽車合成數據架構與應用實踐

51Sim利用NVIDIA Cosmos提升輔助駕駛合成數據場景的泛化性
嵌入式AI技術漫談:怎么為訓練AI模型采集樣本數據
[Actor] 通過actor創建控制中心與數據采集工作站來看操作者架構
技術分享 | 高逼真合成數據助力智駕“看得更準、學得更快”

功德+1,用小安派-Eyes-S1做一個電子木魚
嵌入式AI技術之深度學習:數據樣本預處理過程中使用合適的特征變換對深度學習的意義
技術分享 | AVM合成數據仿真驗證方案




 工商網監
工商網監
評論