") 實現(xiàn) TensorFlow 架構(gòu)的規(guī)模性和靈活性
實現(xiàn) TensorFlow 架構(gòu)的規(guī)模性和靈活性

TensorFlow 是為了大規(guī)模分布式訓(xùn)練和推理而設(shè)計的,不過它在支持新機器學(xué)習(xí)模型和系統(tǒng)級優(yōu)化的實驗中的表現(xiàn)也足夠靈活。
本文對能夠同時兼具規(guī)模性和靈活性的系統(tǒng)架構(gòu)進行了闡述。設(shè)定的人群是已基本熟悉 TensorFlow 編程概念,例如 computation graph, operations, and sessions。有關(guān)這些主題的介紹,請參閱
https://tensorflow.google.cn/guide/low_level_intro?hl=zh-CN。如已熟悉Distributed TensorFlow,本文對您也很有幫助。行至文尾,您應(yīng)該能了解 TensorFlow 架構(gòu),足以閱讀和修改核心 TensorFlow 代碼了。
概覽
TensorFlow runtime 是一個跨平臺庫。圖 1 說明了它的一般架構(gòu)。 C API layer 將不同語言的用戶級代碼與核心運行時分開。
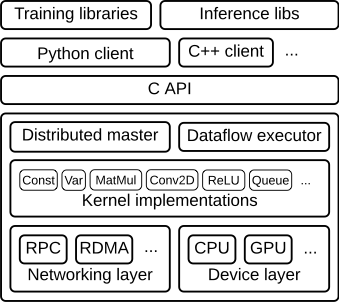
圖 1
本文重點介紹以下幾個方面:
客戶端:
將整個計算過程轉(zhuǎn)義成一個數(shù)據(jù)流圖
通過 session,啟動圖形執(zhí)行
分布式主節(jié)點
基于用戶傳遞給 Session.run() 中的參數(shù)對整個完整的圖形進行修剪,提取其中特定子圖
將上述子圖劃分成不同片段,并將其對應(yīng)不同的進程和設(shè)備當(dāng)中
將上述劃分的片段分布到 worker services 工作節(jié)點服務(wù)上
每個 worker services 工作節(jié)點服務(wù)上執(zhí)行其收到的圖形片段
工作節(jié)點服務(wù) Worker Services(每一任務(wù)一個)
使用內(nèi)核實現(xiàn)來計劃圖形表示的計算部分分配給正確的可用硬件(如 cpu,gpu 等)
與其他工作節(jié)點服務(wù) work services 相互發(fā)送和接收計算結(jié)果
內(nèi)核實現(xiàn)
執(zhí)行單個圖形操作的計算部分
圖2 說明了這些組件的相互作用。“/ job:worker / task:0” 和 “/ job:ps / task:0” 都是工作節(jié)點服務(wù) worker services 上執(zhí)行的任務(wù)。“PS” 表示“參數(shù)服務(wù)器”:負(fù)責(zé)存儲和更新模型參數(shù)。其他任務(wù)在迭代優(yōu)化參數(shù)時會對這些參數(shù)發(fā)送更新。如果在單機環(huán)境下,上述 PS 和 worker 不是必須的,不需要在任務(wù)之間進行這種特定的分工,但是對于分布式訓(xùn)練,這種模式就是很常見的。
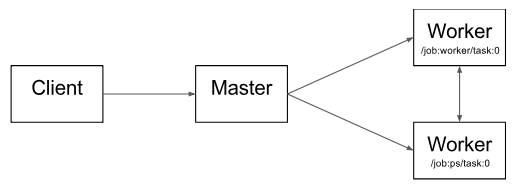
圖 2
請注意,分布式主節(jié)點 Distributed Master 和工作節(jié)點服務(wù) Worker Service 僅存在于分布式 TensorFlow 中。TensorFlow 的單進程版本包含一個特殊的 Session 實現(xiàn),它可以執(zhí)行分布式主服務(wù)器執(zhí)行的所有操作,但只與本地進程中的設(shè)備進行通信。
下面,通過逐步處理示例圖來詳細(xì)介紹一下 TensorFlow 核心模塊。
客戶端
用戶在客戶端編寫 TensorFlow 程序來構(gòu)建計算圖。該程序可以直接組成單獨的操作,也可以使用 Estimators API 之類的便利庫來組合神經(jīng)網(wǎng)絡(luò)層和其他更高級別的抽象概念。TensorFlow 支持多種客戶端語言,我們優(yōu)先考慮 Python 和 C ++,因為我們的內(nèi)部用戶最熟悉這些語言。隨著功能的日趨完善,我們一般會將它們移植到 C ++,以便用戶可以從所有客戶端語言優(yōu)化訪問。盡管大多數(shù)訓(xùn)練庫仍然只支持 Python,但 C ++ 確實能夠支持有效的推理。
客戶端創(chuàng)建會話,該會話將圖形定義作為tf.GraphDef 協(xié)議緩沖區(qū)發(fā)送到分布式主節(jié)點。當(dāng)客戶端評估圖中的一個或多個節(jié)點時,評估會觸發(fā)對分布式主節(jié)點的調(diào)用以啟動計算。
在圖 3 中,客戶端構(gòu)建了一個圖表,將權(quán)重(w)應(yīng)用于特征向量(x),添加偏差項(b)并將結(jié)果保存在變量中。
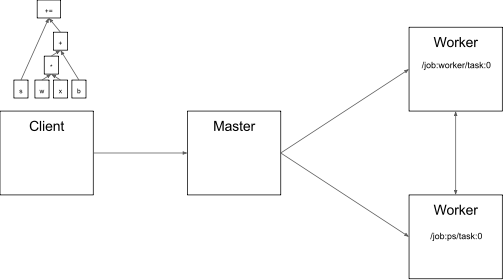
圖 3
代碼:
tf.Session
分布式主節(jié)點 Distributed master
分布式主節(jié)點:
基于客戶端指定的節(jié)點,從完整的圖形中截取所需的子圖
對圖表進一步進行劃分,使其可以將每個圖形片段映射到不同的執(zhí)行設(shè)備上
以及緩存這些劃分好的片段,以便在后續(xù)步驟中再次使用
由于主節(jié)點可以總攬步驟計算,因此它可以使用標(biāo)準(zhǔn)的優(yōu)化方法去做優(yōu)化,例如公共子表達式消除和常量的綁定。然后,對一組任務(wù)中優(yōu)化后的子圖或者片段執(zhí)行協(xié)調(diào)。
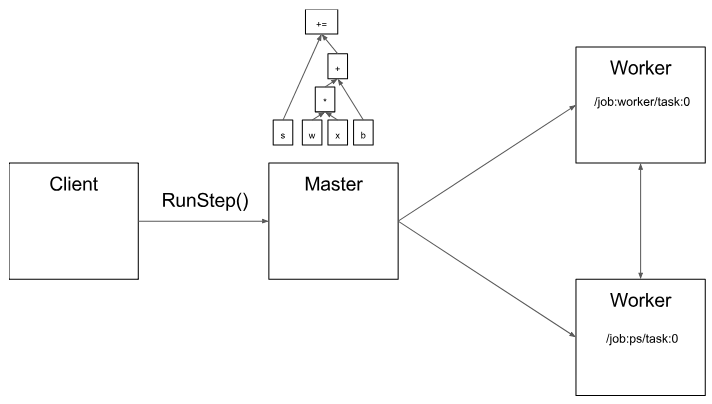
圖4
圖 5 顯示了示例圖的可能分區(qū)。分布式主節(jié)點已對模型參數(shù)進行分組,以便將它們放在參數(shù)服務(wù)器上。
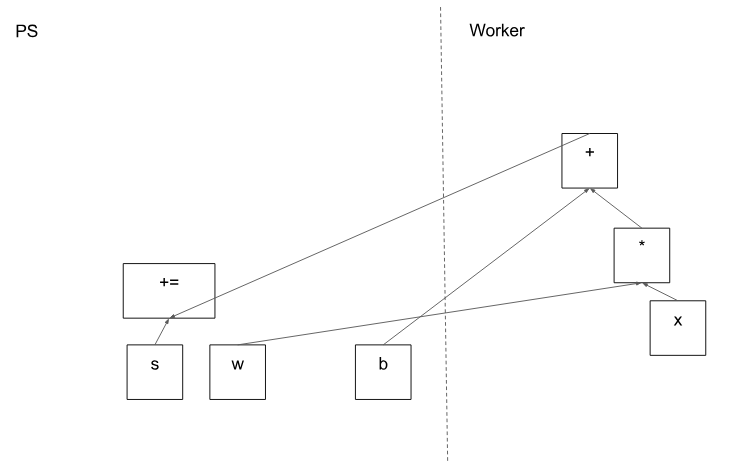
圖5
在分區(qū)切割圖形邊緣的情況下,分布式主節(jié)點插入發(fā)送和接收節(jié)點以在分布式任務(wù)之間傳遞信息(圖 6)。
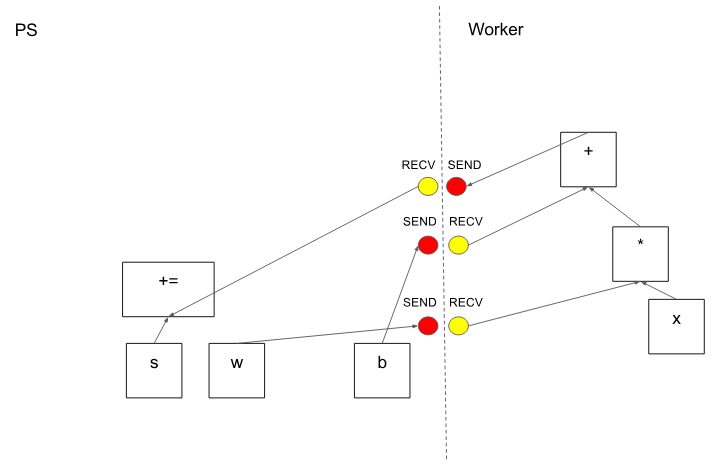
圖 6
然后,分布式主節(jié)點將圖形片段傳送到分布式任務(wù)。
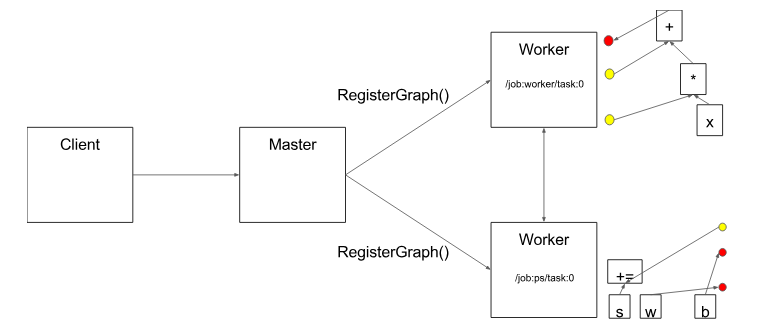
圖 7
代碼:
MasterService API definition
Master interface
工作節(jié)點服務(wù) Worker Service
在每個任務(wù)中,該部分負(fù)責(zé):
處理來自 master 發(fā)來的請求
為包含本地子圖規(guī)劃所需要的內(nèi)核執(zhí)行
協(xié)調(diào)與其他任務(wù)之間的直接信息交換
我們優(yōu)化了 Worker Service,以便其以較低的負(fù)載便能夠運行大型圖形。當(dāng)前的版本可以執(zhí)行每秒上萬個子圖,這使得大量副本可以進行快速的,細(xì)粒度的訓(xùn)練步驟。Worker service 將內(nèi)核分派給本地設(shè)備并在可能的情況下并行執(zhí)行內(nèi)核,例如通過使用多個 CPU 內(nèi)核或者 GPU 流。
我們還特別針對每對源設(shè)備和目標(biāo)設(shè)備類型的 Send 和 Recv 操作進行了專攻:
使用 cudaMemcpyAsync() 來進行本地 CPU 和 GPU 設(shè)備之間的重疊計算和數(shù)據(jù)傳輸
兩個本地 GPU 之間的傳輸使用對等 DMA,以避免通過主機 CPU 主內(nèi)存進行高負(fù)載的復(fù)制
對于任務(wù)之間的傳輸,TensorFlow 使用多種協(xié)議,包括:
gRPC over TCP
融合以太網(wǎng)上的 RDMA
另外,我們還初步支持 NVIDIA 用于多 GPU 通信的 NCCL 庫
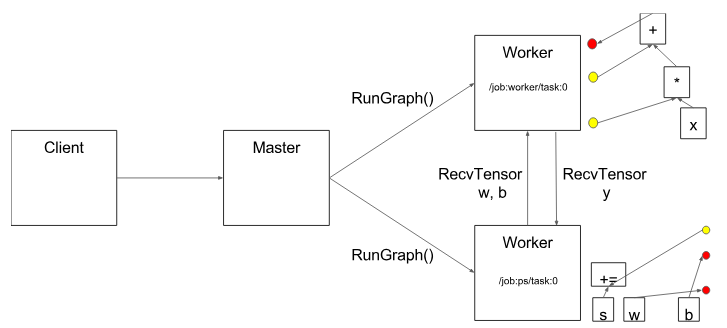
圖8
代碼:
WorkerService API definition
Worker interface
Remote rendezvous (for Send and Recv implementations)
內(nèi)核運行
該運行時包含了 200 多個標(biāo)準(zhǔn)操作,其中涉及了數(shù)學(xué),數(shù)組,控制流和狀態(tài)管理等操作。每個操作都有對應(yīng)各種設(shè)備優(yōu)化后的內(nèi)核運行。其中許多操作內(nèi)核都是通過使用 Eigen::Tensor 實現(xiàn)的,它使用 C ++ 模板為多核 CPU 和 GPU 生成高效的并行代碼;但是,我們可以自由地使用像 cuDNN 這樣的庫,就可以實現(xiàn)更高效的內(nèi)核運行。我們還實現(xiàn)了 quantization 量化,可以在移動設(shè)備和高吞吐量數(shù)據(jù)中心應(yīng)用等環(huán)境中實現(xiàn)更快的推理,并使用 gemmlowp 低精度矩陣庫來加速量化計算。
如果用戶發(fā)現(xiàn)很難去將子計算組合,或者說組合后發(fā)現(xiàn)效率很低,則用戶可以通過注冊額外的 C++ 編寫的內(nèi)核來提供有效的運行。例如,我們建議為一些性能的關(guān)鍵操作注冊自己的融合內(nèi)核,例如 ReLU 和 Sigmoid 激活函數(shù)及其對應(yīng)的梯度等。XLA Compiler提供了一個實驗性質(zhì)的自動內(nèi)核融合實現(xiàn)。
代碼:
OpKernel?interface
-
存儲
+關(guān)注
關(guān)注
13文章
4791瀏覽量
90065 -
架構(gòu)
+關(guān)注
關(guān)注
1文章
532瀏覽量
26590 -
tensorflow
+關(guān)注
關(guān)注
13文章
334瀏覽量
62184
原文標(biāo)題:實現(xiàn) TensorFlow 架構(gòu)的規(guī)模性和靈活性
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
探索PCM510xA系列音頻DAC:高性能與靈活性的完美結(jié)合
強強聯(lián)合!RT-Thread助力某國產(chǎn)天車操作系統(tǒng)廠商破解晶圓廠實時性與靈活性難題|優(yōu)秀案例

CDCM1802時鐘緩沖器:高性能與靈活性的完美結(jié)合
高速MOSFET驅(qū)動芯片MAX17604:高性能與靈活性的完美結(jié)合
探索PCM510xA系列音頻DAC:高性能與靈活性的完美結(jié)合
探索PCM186x-Q1音頻ADC:高性能與靈活性的完美結(jié)合
TLV320ADC3140音頻ADC:高性能與靈活性的完美結(jié)合
TLV320ADC6120音頻ADC:高性能與靈活性的完美結(jié)合
TLV320ADC5120音頻ADC:高性能與靈活性的完美結(jié)合
TAA3020音頻ADC:高性能與靈活性的完美結(jié)合
深入解析 RENESAS SLG51003 PMIC:高性能與靈活性的完美結(jié)合
探索XMC7000工業(yè)微控制器:高性能與靈活性的完美結(jié)合
沁恒網(wǎng)絡(luò)芯片,自研技術(shù)解鎖集成度與靈活性

EtherCAT熱插拔技術(shù):提升工業(yè)自動化系統(tǒng)靈活性的關(guān)鍵

磁性近程傳感器保證非接觸式定位和近程檢測的靈活性和可靠性




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論