 用于移動設備的框架TensorFlow Lite發布重大更新
用于移動設備的框架TensorFlow Lite發布重大更新

TensorFlow用于移動設備的框架TensorFlow Lite發布重大更新,支持開發者使用手機等移動設備的GPU來提高模型推斷速度。
在進行人臉輪廓檢測的推斷速度上,與之前使用CPU相比,使用新的GPU后端有不小的提升。在Pixel 3和三星S9上,提升程度大概為4倍,在iPhone 7上有大約有6倍。
為什么要支持GPU?
眾所周知,使用計算密集的機器學習模型進行推斷需要大量的資源。
但是移動設備的處理能力和功率都有限。雖然TensorFlow Lite提供了不少的加速途徑,比如將機器學習模型轉換成定點模型,但總是會在模型的性能或精度上做出讓步。
而將GPU作為加速原始浮點模型的一種選擇,不會增加量化的額外復雜性和潛在的精度損失。
在谷歌內部,幾個月來一直在產品中使用GPU后端做測試。結果證明,的確可以加快復雜網絡的推斷速度。
在Pixel 3的人像模式(Portrait mode)中,與使用CPU相比,使用GPU的Tensorflow Lite,用于摳圖/背景虛化的前景-背景分隔模型加速了4倍以上。新深度估計(depth estimation)模型加速了10倍以上。
在能夠為視頻增加文字、濾鏡等特效的YouTube Stories和谷歌的相機AR功能Playground Stickers中,實時視頻分割模型在各種手機上的速度提高了5-10倍。
對于不同的深度神經網絡模型,使用新GPU后端,通常比浮點CPU快2-7倍。對4個公開模型和2個谷歌內部模型進行基準測試的效果如下:
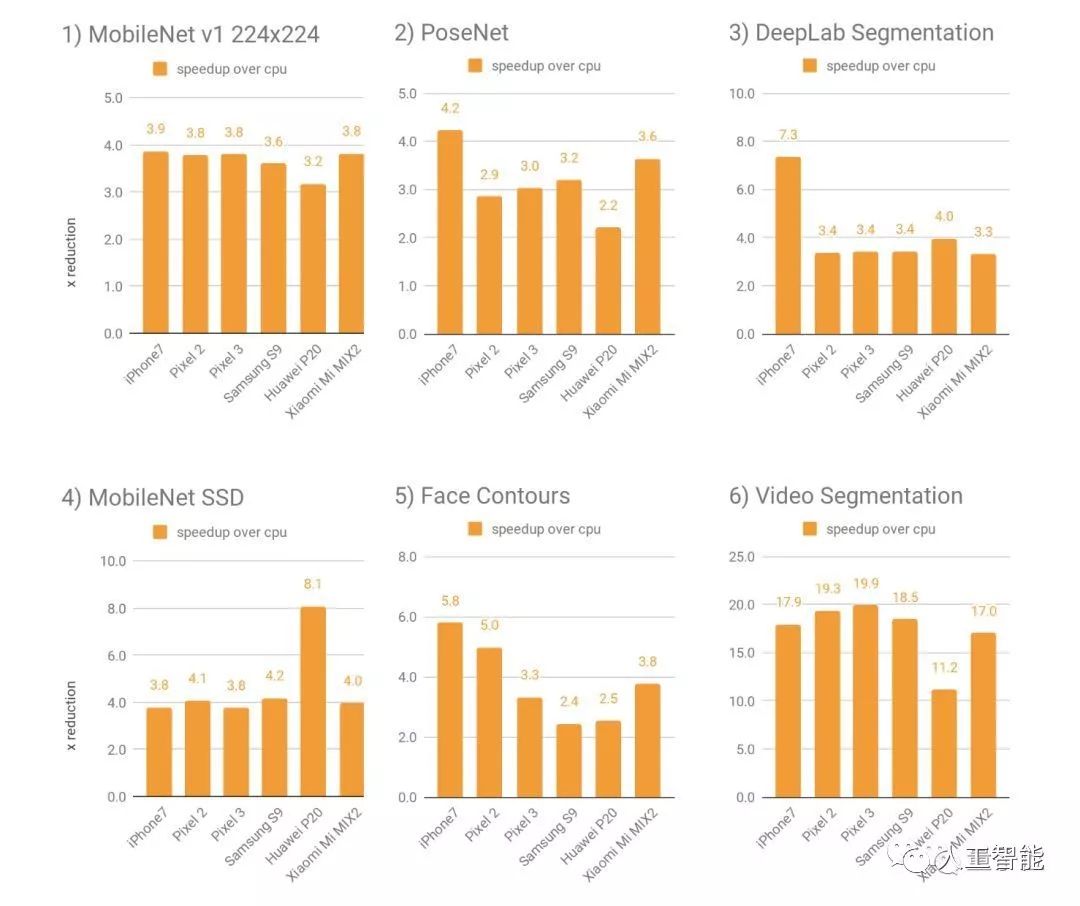
使用GPU加速,對于更復雜的神經網絡模型最為重要,比如密集的預測/分割或分類任務。
在相對較小的模型上,加速的效果就沒有那么明顯了,使用CPU反而有利于避免內存傳輸中固有的延遲成本。
如何使用?
安卓設備(用Java)中,谷歌已經發布了完整的Android Archive (AAR) ,其中包括帶有GPU后端的TensorFlow Lite。
你可以編輯Gradle文件,用AAR替代當前的版本,并將下面的代碼片段,添加到Java初始化代碼中。
//InitializeinterpreterwithGPUdelegate.GpuDelegatedelegate=newGpuDelegate();Interpreter.Optionsoptions=(newInterpreter.Options()).addDelegate(delegate);Interpreterinterpreter=newInterpreter(model,options);//Runinference.while(true){writeToInputTensor(inputTensor);interpreter.run(inputTensor,outputTensor);readFromOutputTensor(outputTensor);}//Cleanup.delegate.close();在iOS設備(用C++)中,要先下載二進制版本的TensorFlowLite。然后更改代碼,在創建模型后調用ModifyGraphWithDelegate()。//InitializeinterpreterwithGPUdelegate.std::unique_ptr
(更多的使用教程,可以參見TensorFlow的官方教程,傳送門在文末)
還在發展中
當前發布的,只是TensorFlow Lite的開發者預覽版。
新的GPU后端,在安卓設備上利用的是OpenGL ES 3.1 Compute Shaders,在iOS上利用的是Metal Compute Shaders。
能夠支持的GPU操作并不多。有:
ADD v1、AVERAGE_POOL_2D v1、CONCATENATION v1、CONV_2D v1、DEPTHWISE_CONV_2D v1-2、FULLY_CONNECTED v1、LOGISTIC v1
MAX_POOL_2D v1、MUL v1、PAD v1、PRELU v1、RELU v1、RELU6 v1、RESHAPE v1、RESIZE_BILINEAR v1、SOFTMAX v1、STRIDED_SLICE v1、SUB v1、TRANSPOSE_CONV v1
TensorFlow官方表示,未來將會擴大操作范圍、進一步優化性能、發展并最終確定API。
完整的開源版本,將會在2019年晚些時候發布。
傳送門
使用教程:
https://www.tensorflow.org/lite/performance/gpu
項目完整文檔:
https://www.tensorflow.org/lite/performance/gpu_advanced
博客地址:
https://medium.com/tensorflow/tensorflow-lite-now-faster-with-mobile-gpus-developer-preview-e15797e6dee7
-
cpu
+關注
關注
68文章
11277瀏覽量
224956 -
移動設備
+關注
關注
0文章
528瀏覽量
55942 -
tensorflow
+關注
關注
13文章
334瀏覽量
62178 -
TensorFlow Lite
+關注
關注
0文章
26瀏覽量
828
原文標題:TensorFlow Lite發布重大更新!支持移動GPU、推斷速度提升4-6倍
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
申請指定設備發布Profile
申請指定設備發布Profile
如何在TensorFlow Lite Micro中添加自定義操作符(1)
微軟發布多項智能Microsoft?365?Copilot副駕駛重大更新
【上海晶珩睿莓1開發板試用體驗】將TensorFlow-Lite物體歸類(classify)的輸出圖片移植到LVGL9.3界面中
【上海晶珩睿莓1開發板試用體驗】TensorFlow-Lite物體歸類(classify)
技術洞見:THEIA S1 & S1 LITE 直播機實操效果真的棒!
芯科科技Arduino開發資源重大更新
無法將Tensorflow Lite模型轉換為OpenVINO?格式怎么處理?
迅為iTOP-3576開發板適用于ARM PC、邊緣計算、個人移動互聯網設備及其他多媒體產品。
DevEco重大更新快來體驗吧
迅為iTOP-RK3576開發板/核心板6TOPS超強算力NPU適用于ARM PC、邊緣計算、個人移動互聯網設備及其他多媒體產品
微軟Copilot迎來重大更新
FlexBuild構建Debian 12,在“tflite_ethosu_delegate”上構建失敗了怎么解決?
LibreELEC 12.0.2 為樹莓派用戶帶來重大變化!




 工商網監
工商網監
評論