 gpu加速原理
gpu加速原理

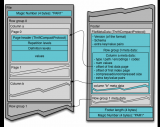
GPU一推出就包含了比CPU更多的處理單元,更大的帶寬,使得其在多媒體處理過程中能夠發揮更大的效能。例如:當前最頂級的CPU只有4核或者6核,模擬出8個或者12個處理線程來進行運算,但是普通級別的GPU就包含了成百上千個處理單元,高端的甚至更多,這對于多媒體計算中大量的重復處理過程有著天生的優勢。下圖展示了CPU和GPU架構的對比。
從硬件設計上來講,CPU 由專為順序串行處理而優化的幾個核心組成。另一方面,GPU 則由數以千計的更小、更高效的核心組成,這些核心專為同時處理多任務而設計。
通過上圖我們可以較為容易地理解串行運算和并行運算之間的區別。傳統的串行編寫軟件具備以下幾個特點:要運行在一個單一的具有單一中央處理器(CPU)的計算機上;一個問題分解成一系列離散的指令;指令必須一個接著一個執行;只有一條指令可以在任何時刻執行。而并行計算則改進了很多重要細節:要使用多個處理器運行;一個問題可以分解成可同時解決的離散指令;每個部分進一步細分為一系列指示;每個部分的問題可以同時在不同處理器上執行。
舉個生活中的例子來說,你要點一份餐館的外賣,CPU型餐館用一輛大貨車送貨,每次可以拉很多外賣,但是送完一家才能到下一家送貨,每個人收到外賣的時間必然很長;而GPU型餐館用十輛小摩托車送貨,每輛車送出去的不多,但是并行處理的效率高,點餐之后收貨就會比大貨車快很多。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
cpu
+關注
關注
68文章
11279瀏覽量
224999 -
gpu
+關注
關注
28文章
5194瀏覽量
135459
發布評論請先 登錄
相關推薦
熱點推薦
基于NVIDIA GPU加速端點使用千問3.5 VLM開發原生多模態智能體
阿里巴巴推出了全新開源 千問3.5 系列,專為構建原生多模態智能體而設計。該系列的首個模型是一款總參數為 397B、具備推理能力的原生視覺語言模型 (VLM),基于由混合專家模型 (MoE) 和門控 Delta 網絡 (Gated Delta Networks) 組成的混合架構構建。千問3.5 能夠理解和導航用戶界面,相較上一代 VLM 有了顯著提升。
Altair CFD 以技術賦能工程創新?
(Altair? ultraFluidX?)原生GPU加速,可超高速完成車輛、建筑空氣動力學仿真,一夜即可完成一輪高瞬態仿真迭代。2. 全類型仿真分析,覆蓋核心需求:支持全尺度流場分析(穩態/瞬態、層流/湍流等
發表于 02-28 14:47
RK3562 單板機圖形用戶界面開發完全手冊:Qt Creator 配置與 LVGL 案例詳解(二)
程序自啟動與 GPU 加速實現。通過圖片顯示、LED 控制等案例,明確關鍵代碼與測試步驟。創龍科技以清晰實操指引,幫助開發者高效完成 Qt 圖形界面開發,適用于工業控制、智能終端等場景。

RK3562 單板機圖形用戶界面開發完全手冊:Qt Creator 配置與 LVGL 案例詳解(一)
程序自啟動與 GPU 加速實現。通過圖片顯示、LED 控制等案例,明確關鍵代碼與測試步驟。創龍科技以清晰實操指引,幫助開發者高效完成 Qt 圖形界面開發,適用于工業控制、智能終端等場景。

RSoft GPU加速技術重塑光子元件設計效率革命
設計效率。為了解決這個問題,RSoft 光子器件工具的 FullWAVE FDTD 模組中引入 GPU 加速,通過 NVIDIA GPU 的平行運算能力,使得模擬速度相比 CPU 計算大幅提升。

NVIDIA RTX PRO 5000 Blackwell GPU的深度評測
NVIDIA RTX PRO 5000 Blackwell 是 NVIDIA RTX 5000 Ada Generation 的升級迭代產品,其各項核心指標均針對 GPU 加速工作流的高性能

如何在NVIDIA Jetson平臺上運行最新的開源AI模型
在小型、低功耗的邊緣設備上運行先進的 AI 和計算機視覺工作流正變得越來越具有挑戰性。機器人、智能攝像頭和自主設備需要實時智能來感知、理解并做出反應,而無需依賴云端。NVIDIA Jetson 平臺通過緊湊的 GPU 加速模塊和專為邊緣 AI 與機器人開發設計的開發套件,
沐曦股份GPU加速技術助力藥物研發降本增效
沐曦股份科學計算團隊近期取得突破性進展,成功將主流分子動力學模擬引擎GROMACS中的FEP計算全流程部署于GPU執行,并實現2.5倍性能提升,相關成果獲得GROMACS官方團隊的高度認可,該GPU
FPGA和GPU加速的視覺SLAM系統中特征檢測器研究
(Nvidia Jetson Orin與AMD Versal)上最佳GPU加速方案(FAST、Harris、SuperPoint)與對應FPGA加速方案的性能,得出全新結論。

NVIDIA與合作伙伴推動物理AI發展
借助 NVIDIA RTX PRO Blackwell GPU 加速的高級藍圖、視覺語言模型和合成數據生成擴展,可提高生產力并改善各環境的安全性。
使用NVIDIA GPU加速Apache Spark中Parquet數據掃描
隨著各行各業的企業數據規模不斷增長,Apache Parquet 已經成為了一種主流數據存儲格式。Apache Parquet 是一種列式存儲格式,專為高效的大規模數據處理而設計。它按列而非按行的方式組織數據,這使得 Parquet 在查詢時僅讀取所需的列,而無需掃描整行數據,即可實現高性能的查詢和分析。高效的數據布局使 Parquet 在現代分析生態系統中成為了受歡迎的選擇,尤其是在 Apache Spark 工作負載中。
高效地擴展Polars GPU Parquet讀取器
在處理大型數據集時,數據處理工具的性能至關重要。Polars 作為一個以速度和效率著稱的開源數據處理庫,它提供了由 cuDF 驅動的 GPU 加速后端,能夠顯著提升性能。

NVIDIA技術驅動帕西尼觸覺感知與人形機器人智能突破
感知科技實現了從接觸仿真、觸覺信號產生、仿真數據生成,再到觸覺模態模型訓練的全流程 GPU 加速,提升標定和訓練效率 100 倍,完成觸覺傳感器的批量標定和觸覺模態規模化實機部署。
基于1.35M Instance設計的GPU加速實例
CPU是計算機的核心部件,由運算器、控制器、寄存器組和內部總線等部分組成。常見的x86架構CPU核心數相對較少,一般在8 - 32核左右,主要是為了解決復雜的邏輯運算和順序執行指令的任務。它在處理單線程任務時效率很高,能夠快速執行復雜的指令集,例如進行數學計算、程序的流程控制等操作。

使用NVIDIA RTX PRO Blackwell系列GPU加速AI開發
NVIDIA GTC 推出新一代專業級 GPU 和 AI 賦能的開發者工具—同時,ChatRTX 更新現已支持 NVIDIA NIM,RTX Remix 正式結束測試階段,本月的 NVIDIA Studio 驅動現已開放下載。



 工商網監
工商網監
評論